







Dispatcher(分布式查询分发器)是MPP数据库的核心组件,所有的查询任务都要经过其进行分发,起着沟通用户到协调者(Coordinator,即QD)和执行调度的关键作用。
在这次的直播中,我们为大家介绍了Dispatcher基本原理和实现机制,并结合实际用例进行了操作演示。以下内容根据直播文字整理而成。
Slice与Gang的基本概念与分类
传统MPP数据库采用无共享Shared-Nothing架构来存储数据,节点之间不共享存储和计算资源,需要使用其他节点的数据时通常利用网络重分发。
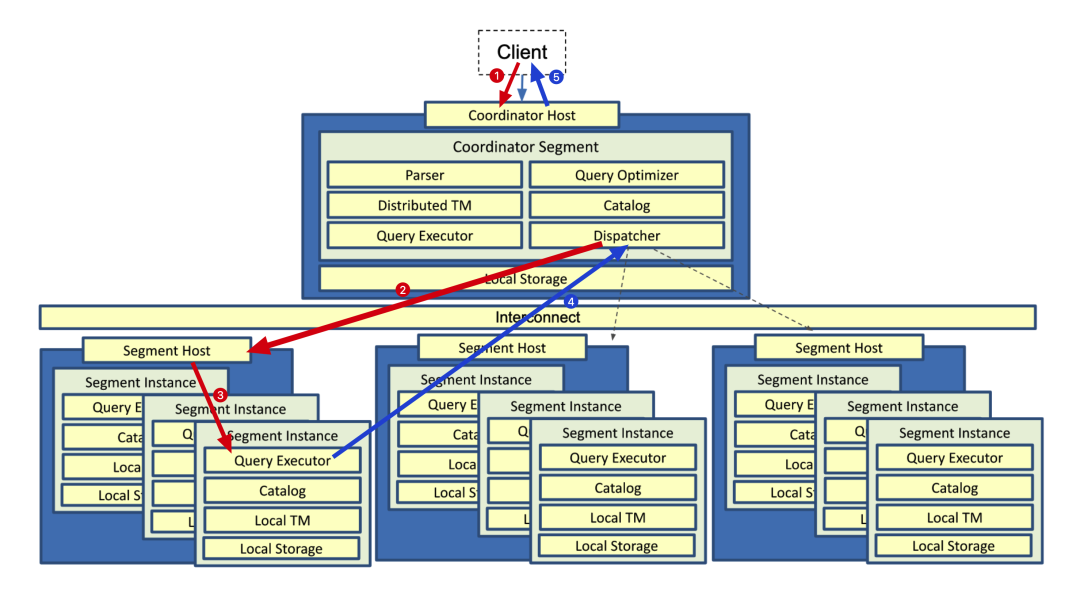
图1:Greenplum数据库查询示意图
(图片来自 Greenplum: A Hybrid Database for Transactional and Analytical Workloads,SIGMOD '21 ,序号和箭头系本文作者所加)
以Greenplum为例,如图1所示,当用户连接到Coordinator(协调者节点)进行查询操作时,会通过Dispatcher组件将查询任务分配到不同的Segment,各Segment之间通过Interconnect模块来传输数据。当各节点查询执行完成后,由QD节点对查询结果进行收集和整理,再回传给用户。
需要注意的是,在查询任务执行时,用户不会和QE产生任何的连接,所有消息都是通过QD 来中转传递,这也是MPP 数据库的重要特征。整个过程中,涉及到两个重要的概念:
Slice:为了在查询执行期间实现最大的并行度,Greenplum会将查询计划工作划分为Slices。Slice是查询计划中可以独立进行处理的部分。查询计划会为Motion生成Slice,Motion的每一侧都有一个Slice。正是由于Motion算子将查询计划分割为一个个Slice,上一层Slice对应的进程会读取下一层各个Slice进程广播或重分布操作生成的数据,然后进行计算。
Gang:属于同一个Slice但是运行在不同的Segment上的进程,称之为Gang。在Greenplum中,共有Unallocated、Reader Gang、Writer Gang、Entry Reader、Singleton Reader五种类型的Gang。其中:
Unallocated运行在QD,一般只在Gather Motion将各个QE回传的结果收取并集时才会用到。
Reader Gang和 Writer Gang会经常用到,而且相关的查询计划会很复杂。
● 只读的查询仅包含 Reader Gang,包含写操作的查询才会使用Writer Gang。
● 一些既读又写的查询(例如 Create table as、Update Returning等)可能同时包含这两类 Gang。
● 这两类 Gang 都只有 1-Gang 和 N-Gang 的情况(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









