







展望Flink各版本及新特性
- 一 Flink 1.9 版本
- 二 Flink 1.10 [重要版本 : Blink 整合完成]
- 三 Flink 1.11 [重要版本]
- 四 Flink 1.12 [重要版本]
- 五 Flink 1.13
- 六 Flink 1.14
- 七 Flink 1.15
- 八 Flink 1.16
- 九 Flink 1.17
- Flink 2.0 规划
一 Flink 1.9 版本
阿里内部版本Blink首次合并入Flink,并于2019年8月22日,正式发布Apache Flink 1.9.0 版本。
此次版本更新带来的重大功能包括批处理作业的批式恢复,以及 Table API 和 SQL 的基于 Blink 的新查询引擎(预览版)。同时,这一版本还推出了 State Processor API,这是社区最迫切需求的功能之一,该 API 使用户能够用 Flink DataSet 作业灵活地读写保存点。此外,Flink 1.9 还包括一个重新设计的 WebUI 和新的 Python Table API (预览版)以及与 Apache Hive 生态系统的集成(预览版)。
新功能和改进
- 细粒度批作业恢复 (FLIP-1)
- State Processor API (FLIP-43)
- Stop-with-Savepoint (FLIP-34)
- 重构 Flink WebUI
- 预览新的 Blink SQL 查询处理器
- Table API / SQL 的其他改进
- 预览 Hive 集成 (FLINK-10556)
- 预览新的 Python Table API (FLIP-38)
1.1 细粒度批作业恢复
批作业(DataSet、Table API 和 SQL)从 task 失败中恢复的时间被显著缩短了。在 Flink 1.9 之前,批处理作业中的 task 失败是通过取消所有 task 并重新启动整个作业来恢复的,即作业从头开始,所有进度都会废弃。在此版本中,Flink 将中间结果保留在网络 shuffle 的边缘,并使用此数据去恢复那些仅受故障影响的 task。所谓 task 的 “failover regions” (故障区)是指通过 pipelined 方式连接的数据交换方式,定义了 task 受故障影响的边界。
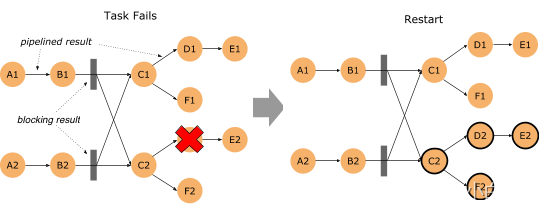
要使用这个新的故障策略,需要确保 flink-conf.yaml 中有 jobmanager.execution.failover-strategy: region 的配置。
注意:1.9 发布包中默认就已经包含了该配置项,不过当从之前版本升级上来时,如果要复用之前的配置的话,需要手动加上该配置。
“Region” 的故障策略也能同时提升 “embarrassingly parallel” 类型的流作业的恢复速度,也就是没有任何像 keyBy() 和 rebalance 的 shuffle 的作业。当这种作业在恢复时,只有受影响的故障区的 task 需要重启。对于其他类型的流作业,故障恢复行为与之前的版本一样。
1.2 State Processor API
直到 Flink 1.9,从外部访问作业的状态仅局限于:Queryable State(可查询状态)实验性功能。此版本中引入了一种新的、强大的类库,基于 DataSet 支持读取、写入、和修改状态快照。在实践上,这意味着:
Flink 作业的状态可以自主构建了,可以通过读取外部系统的数据(例如外部数据库),然后转换成 savepoint。
Savepoint 中的状态可以使用任意的 Flink 批处理 API 查询(DataSet、Table、SQL)。例如,分析相关的状态模式或检查状态差异以支持应用程序审核或故障排查。
Savepoint 中的状态 schema 可以离线迁移了,而之前的方案只能在访问状态时进行,是一种在线迁移。
Savepoint 中的无效数据可以被识别出来并纠正。
新的 State Processor API 覆盖了所有类型的快照:savepoint,full checkpoint 和 incremental checkpoint。
1.3 Stop-with-Savepoint
“Cancel-with-savepoint” 是停止、重启、fork、或升级 Flink 作业的一个常用操作。然而,当前的实现并没有保证输出到 exactly-once sink 的外部存储的数据持久化。为了改进停止作业时的端到端语义,Flink 1.9 引入了一种新的 SUSPEND 模式,可以带 savepoint 停止作业,保证了输出数据的一致性。你可以使用 Flink CLI 来 suspend 一个作业
1.4 新 Blink SQL 查询处理器预览
在 Blink 捐赠给 Apache Flink 之后,社区就致力于为 Table API 和 SQL 集成 Blink 的查询优化器和 runtime。第一步,我们将 flink-table 单模块重构成了多个小模块(FLIP-32)。这对于 Java 和 Scala API 模块、优化器、以及 runtime 模块来说,有了一个更清晰的分层和定义明确的接口。

紧接着,我们扩展了 Blink 的 planner 以实现新的优化器接口,所以现在有两个插件化的查询处理器来执行 Table API 和 SQL:1.9 以前的 Flink 处理器和新的基于 Blink 的处理器。基于 Blink 的查询处理器提供了更好地 SQL 覆盖率(1.9 完整支持 TPC-H,TPC-DS 的支持在下一个版本的计划中)并通过更广泛的查询优化(基于成本的执行计划选择和更多的优化规则)、改进的代码生成机制、和调优过的算子实现来提升批处理查询的性能。除此之外,基于 Blink 的查询处理器还提供了更强大的流处理能力,包括一些社区期待已久的新功能(如维表 Join,TopN,去重)和聚合场景缓解数据倾斜的优化,以及内置更多常用的函数。
注:两个查询处理器之间的语义和功能大部分是一致的,但并未完全对齐。具体请查看发布日志。
不过, Blink 的查询处理器的集成还没有完全完成。因此,1.9 之前的 Flink 处理器仍然是1.9 版本的默认处理器,建议用于生产设置。你可以在创建 TableEnvironment 时通过 EnvironmentSettings 配置启用 Blink 处理器。被选择的处理器必须要在正在执行的 Java 进程的类路径中。对于集群设置,默认两个查询处理器都会自动地加载到类路径中。当从 IDE 中运行一个查询时,需要在项目中显式地增加一个处理器的依赖。
1.5 Table API / SQL 的其他改进
除了围绕 Blink Planner 令人兴奋的进展外,社区还做了一系列的改进,包括:
为 Table API / SQL 的 Java 用户去除 Scala 依赖 (FLIP-32)
作为重构和拆分 flink-table 模块工作的一部分,我们为 Java 和 Scala 创建了两个单独的 API 模块。对于 Scala 用户来说,没有什么改变。不过现在 Java 用户在使用 Table API 和 SQL 时,可以不用引入一堆 Scala 依赖了。
重构 Table API / SQL 的类型系统(FLIP-37)
我们实现了一个新的数据类型系统,以便从 Table API 中移除对 Flink TypeInformation 的依赖,并提高其对 SQL 标准的遵从性。不过还在进行中,预计将在下一版本完工,在 Flink 1.9 中,UDF 尚未移植到新的类型系统上。
Table API 的多行多列转换(FLIP-29)
Table API 扩展了一组支持多行和多列、输入和输出的转换的功能。这些转换显著简化了处理逻辑的实现,同样的逻辑使用关系运算符来实现是比较麻烦的。
崭新的统一的 Catalog API
Catalog 已有的一些接口被重构和(某些)被替换了,从而统一了内部和外部 catalog 的处理。这项工作主要是为了 Hive 集成(见下文)而启动的,不过也改进了 Flink 在管理 catalog 元数据的整体便利性。
SQL API 中的 DDL 支持 (FLINK-10232)
到目前为止,Flink SQL 已经支持 DML 语句(如 SELECT,INSERT)。但是外部表(table source 和 table sink)必须通过 Java/Scala 代码的方式或配置文件的方式注册。1.9 版本中,我们支持 SQL DDL 语句的方式注册和删除表(CREATE TABLE,DROP TABLE)。然而,我们还没有增加流特定的语法扩展来定义时间戳抽取和 watermark 生成策略等。流式的需求将会在下一版本完整支持
官方原文:
https://flink.apache.org/news/2019/08/22/release-1.9.0.html
二 Flink 1.10 [重要版本 : Blink 整合完成]
作为 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成(beta 版本)以及对 Python 支持(PyFlink)的重大优化。
Flink 1.10 同时还标志着对 Blink[1] 的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。
2.1 内存管理及配置优化
Flink 目前的 TaskExecutor 内存模型存在着一些缺陷,导致优化资源利用率比较困难,例如:
流和批处理内存占用的配置模型不同;
流处理中的 RocksDB state backend 需要依赖用户进行复杂的配置。
为了让内存配置变的对于用户更加清晰、直观,Flink 1.10 对 TaskExecutor 的内存模型和配置逻辑进行了较大的改动 。这些改动使得 Flink 能够更好地适配所有部署环境(例如 Kubernetes, Yarn, Mesos),让用户能够更加严格的控制其内存开销。
■ Managed 内存扩展
Managed 内存的范围有所扩展,还涵盖了 RocksDB state backend 使用的内存。尽管批处理作业既可以使用堆内内存也可以使用堆外内存,使用 RocksDB state backend 的流处理作业却只能利用堆外内存。因此为了让用户执行流和批处理作业时无需更改集群的配置,我们规定从现在起 managed 内存只能在堆外。
■ 简化 RocksDB 配置
此前,配置像 RocksDB 这样的堆外 state backend 需要进行大量的手动调试,例如减小 JVM 堆空间、设置 Flink 使用堆外内存等。现在,Flink 的开箱配置即可支持这一切,且只需要简单地改变 managed 内存的大小即可调整 RocksDB state backend 的内存预算。
另一个重要的优化是,Flink 现在可以限制 RocksDB 的 native 内存占用,以避免超过总的内存预算——这对于 Kubernetes 等容器化部署环境尤为重要。关于如何开启、调试该特性,请参考 RocksDB
2.2 统一的作业提交逻辑
在此之前,提交作业是由执行环境负责的,且与不同的部署目标(例如 Yarn, Kubernetes, Mesos)紧密相关。这导致用户需要针对不同环境保留多套配置,增加了管理的成本。
在 Flink 1.10 中,作业提交逻辑被抽象到了通用的 Executor 接口。新增加的 ExecutorCLI 引入了为任意执行目标指定配置参数的统一方法。此外,随着引入 JobClient负责获取 JobExecutionResult,获取作业执行结果的逻辑也得以与作业提交解耦
2.3 原生 Kubernetes 集成(Beta)
对于想要在容器化环境中尝试 Flink 的用户来说,想要在 Kubernetes 上部署和管理一个 Flink standalone 集群,首先需要对容器、算子及像 kubectl 这样的环境工具有所了解。
在 Flink 1.10 中,我们推出了初步的支持 session 模式的主动 Kubernetes 集成(FLINK-9953 [15])。其中,“主动”指 Flink ResourceManager (K8sResMngr) 原生地与 Kubernetes 通信,像 Flink 在 Yarn 和 Mesos 上一样按需申请 pod。用户可以利用 namespace,在多租户环境中以较少的资源开销启动 Flink。这需要用户提前配置好 RBAC 角色和有足够权限的服务账号。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











