



爬虫课后作业报告
- 准备
- 了解需要用到的requests库的知识与应用
https://pypi.org/project/requests/
- 在Pycharm中安装requests库
- file->settings
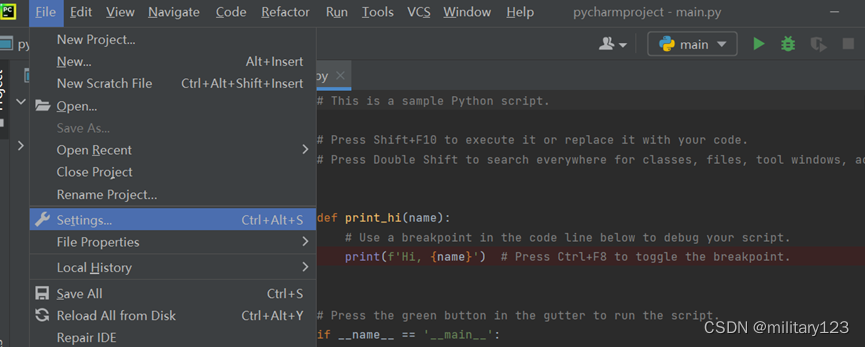
- 选择project下的interpreter,下滑寻找是否有requests,若有则不需要再进行安装,否则点击左上角+号,在搜索框中填入requests,点击安装。
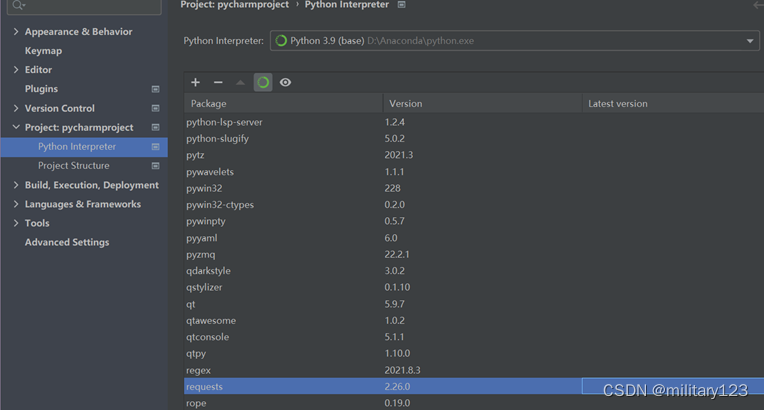
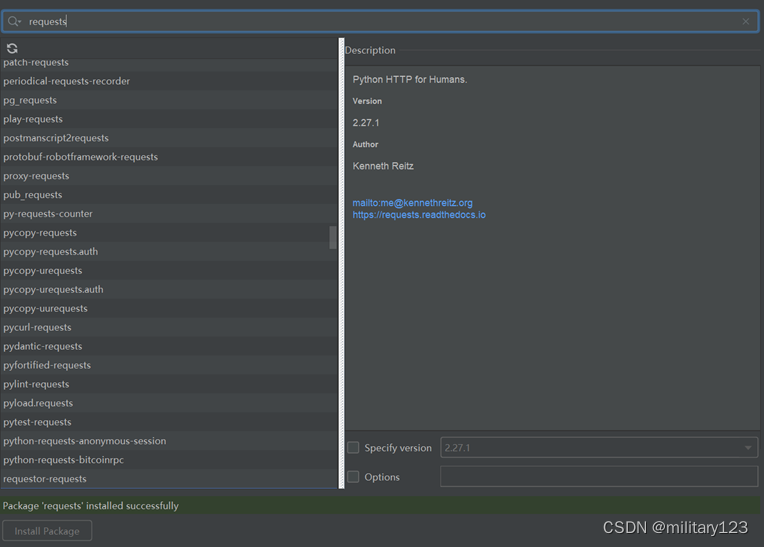
- 过程
- 了解静态网页解析办法,学习beautifulsoup用法
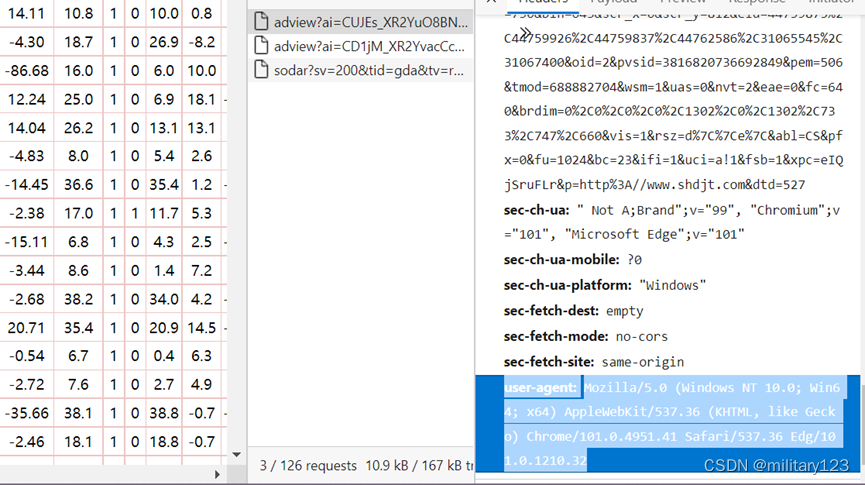
- 构建header
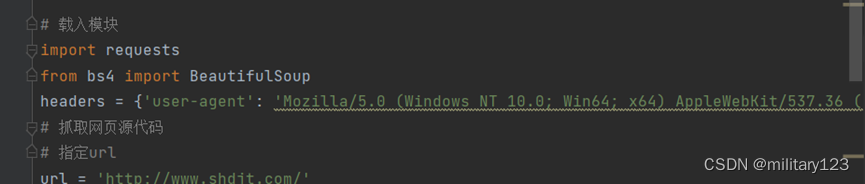
- 解析网页
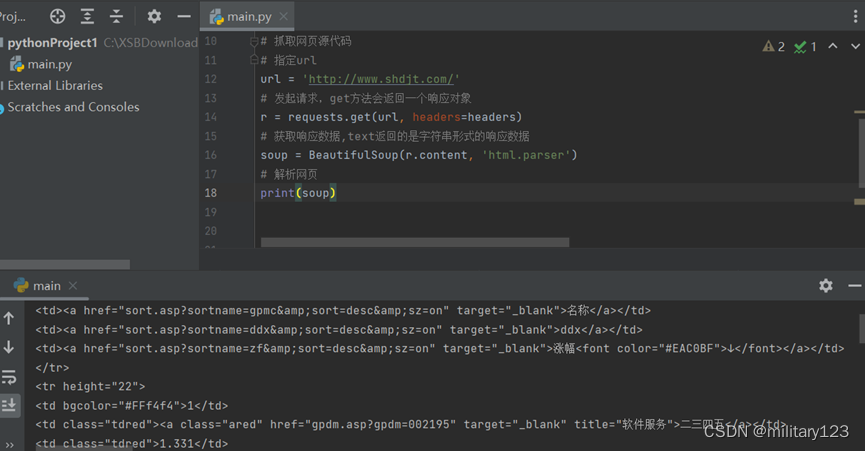
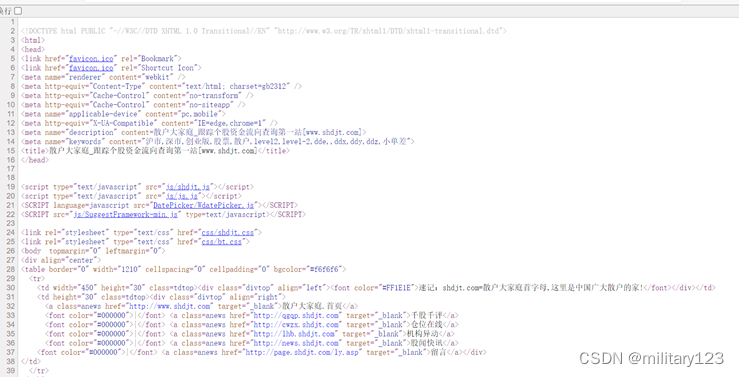
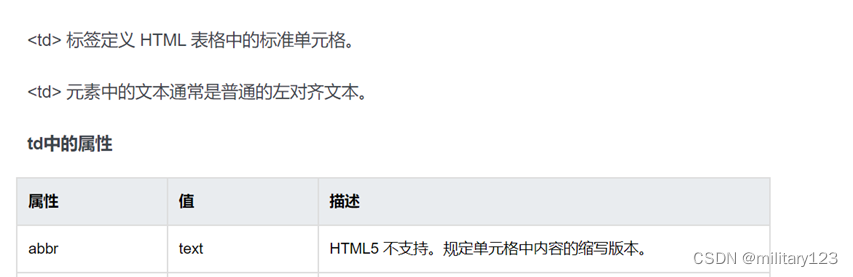
- 可以看出所有需要爬取的数据都在<td class=”tdred”>节点里,用find_all函数找到所有节点,遍历内容。以td的上一个节点tr作为操作对象
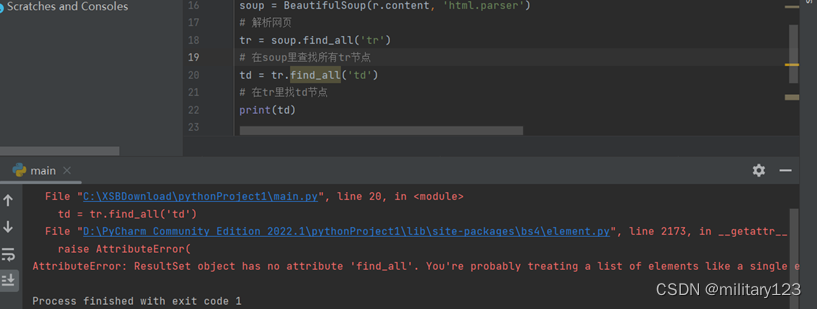
- 报错是因为找出来的tr节点不止一个,无法一次性找出所有td节点,所以需要循环遍历tr,输出其中的文字内容。通过查找,了解到HTML 的<td>标签中有一个abbr属性的值为text文本,即需要爬取的目标数据。
- 提取出所有文本
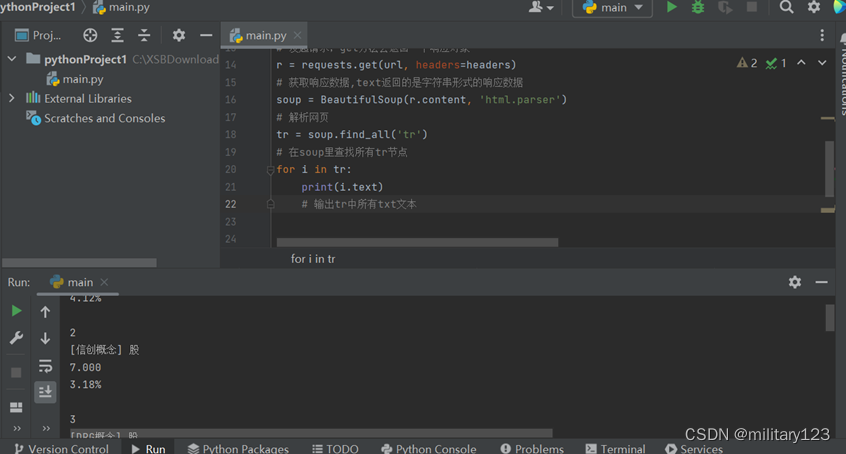
- 代码
# 载入模块
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'}
# 抓取网页源代码
# 指定url
url = 'http://www.shdjt.com/'
# 发起请求,get方法会返回一个响应对象
r = requests.get(url, headers=headers)
# 获取响应数据,text返回的是字符串形式的响应数据
soup = BeautifulSoup(r.content, 'html.parser')
# 解析网页
tr = soup.find_all('tr')
# 在soup里查找所有tr节点
for i in tr:
print(i.text)
# 输出tr中所有txt文本
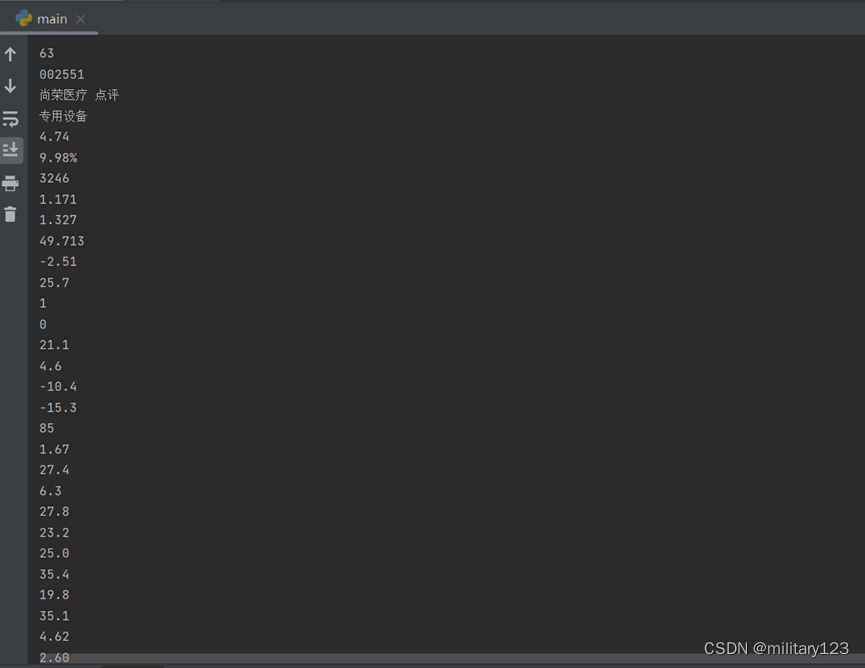
- 最终效果

















 6034
6034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









