






文章目录
sv的仿真时间调度机制
Time literal
format
type: time,state :4 ,bit: 32
42ps
3.13ns//no space
1step//only 1
在整个编译文件中使用`timescale或者timeprecision定义时间精度中的最小的就是1step。使用#1step可以在进入当前的timeslot前进行采样,等同于在当前timeslot的prepone上进行采样。
- 在clocking block(使用clocking, endclocking作为关键字,主要是在interface中使用),input信号默认使用#1step来采样,output信号默认delay为 0。
- 在并发断言中,断言中的变量的值在prepone进行采样,断言在Observed region进行计算,在Reactive region判断断言成功/失败。如果断言中的变量是clocking block中的输入信号,则必须采样带有#1step的clocking block的输入信号。实际是无论信号是否在clocking block中,断言采样在#1setp和prepone中没有任何区别
如果所有编译文件定义了相同的时间精度,那么#1 = #1step,但如果有新的时间精度文件加入,#1就可能不等于#1step,所以#1是局部时间精度的函数,#1step是全局的。 注意2个time slot之间并不是只有1个step,可能是多个。
`timescale
`timescale 1ns/1ps
//等效于
module test;
timeunit 1ns;
timeprecision 10ps;
endmodule
//但是timeunit 1ns;
//timeprecision 10ps;一定要放在module块里
Events Regions
Verilog的赋值
简单给大家复习一下吧,可能有些人不太清楚这些具体的术语
连续赋值
连续赋值就是一旦赋值,输出将随输入改变而变化,一旦修改输入则立刻体现在输出上。
input a,b;
wire out;
assign out = a & b;
常用于组合逻辑
过程赋值
过程赋值只会在赋值时刻进行改变,其余时间保持不变,而且根据使用的赋值符号=和<=,分为阻塞赋值和非阻塞赋值。
阻塞赋值 :
//例1
initial begin
ai = 4'd1 ; //(1)
ai = 4'd2 ; //(2)
//ai 最此刻为 2
#20 ; //(3)
ai = 4'd3 ; //(4)
bi = 4'd4 ; //(5)
value_blk = ai + bi ; //(6)
//value_blk 最终为7
#40;
end
非阻塞赋值 =>
//例1
initial begin
ai = 4'd1 ; //(1)
bi = 4'd2 ; //(2)
//ai和bi的初始值分别为1,2
#20 ; //(3)
//非阻塞赋值
ai <= 4'd3 ; //(4)
bi <= 4'd4 ; //(5)
value_nonblk <= ai + bi ; //(6)
#40;
//value_blk 最终为3
end
非阻塞赋值类似于物理电路中的时序电路,其中可以这样理解代码执行顺序,1->2->3之后其他的非阻塞赋值(4)(5)(6)不着急执行,而是列入到"事件队列"中,一直存到#40需要被执行前,即下一个时刻需要执行前,(4)(5)(6)将会被同时执行,此时对于value_nonblk而言其对应的ai和bi依旧是1和2,因此结果为3,可用于时序电路建模。
非阻塞赋值是前一个赋值并不会阻塞后一个赋值,而是将所有赋值放到“事件队列”中,并在该时刻的“最后”同时执行,也就是说,赋值过程不会阻塞。
event
从数学建模的角度讲,sv是一个基于离散事件仿真(Discrete Event Simulation,缩写为DES)设计的语言。与之相反的是Continuous-Time Models,在一些热力学、模拟电路、纳电子器件等系统的建模中一般采取这种建模方式,一般使用微积分里面学的ode或者数理方程学的pde解决,当然,很多没有解析解的pde也是直接采用有限差分法等方法转换为DTM(Discrete-Time Models)的问题,会引入一定的误差。对于DTM的问题,一种是简单的设定一个时间片(time slot,在早期的IEEE描述里面,也叫做timestep,只不过现在不这么叫了),在程序里面写一个for循环,每delay一个time slot就计算仿真一次,更新一次状态。其实游戏里面的subtick就是这个,我们玩联机游戏也大多是服务器每过多少ms计算更新一次状态,游戏行业叫做subtick,我们IEEE就叫做time slot。
sv的DES还稍微有所不同,只有在有事件触发的时候才进行仿真,比如@(*)就是任何变量的改变都会触发块内仿真语句的计算@(posedge clk)就只有时钟的上升沿是触发事件。
这样的好处是,在没有什么信号变化或者系统空闲的时候,我们可以仿真的很快,有时你仿真几千ms,但因为没什么数据变化,其实仿真的耗时很短(而且因为fsdb或者vcd的格式只会记录数据的变化,所以占用的存储也很小)
process
事件触发的系统任务就叫做进程(Processes),这是sv中用于模拟电路中并发调度的单元,比如:原语(Primitives)、initial过程块、always过程块、连续赋值(continuous assign)、异步任务(asynchronous tasks)、过程赋值(procedural assignment)等。进程是可以被执行的,有相应的状态标志(state,比如挂起)。进程会响应输入的变化并产生对应的输出。sv的描述的对象也正是这些进程。
而event可以大概分为:
更新事件(update event):仿真中,net或者variable上每次的变化被认为是一次更新事件。
求值事件(evaluation event):进程对更新事件敏感!当一个更新事件被执行时,所有对该更新事件敏感的进程都会被求值,但是顺序是任意的。进程的求值本身也被认为是一种事件,即求值事件(evaluation event)。更新事件和求值事件的相互交替执行,推动了仿真时间的前移。
time-solt
时间片time-slot(后简称ts)是EDA工具进行仿真进程中的抽象时间单位,该时间点内所有线程被划分为相应的优先级进行调度。如果线程在同一ts内被调度,从外部看他们仿佛属于同一时间点“并行”执行的,但是实际上是有先有后,因为软件行为中不存在绝对的并行。ts存在的主要价值是能够解决一部分仿真中的竞争与冒险,使仿真行为尽量与实际电路行为保持一致。
归结起来一句话:通过一个ts中发生的行为,可以认为是实际电路中同一时刻并行完成的,而在仿真中是有先后顺序调度的。
一般来说,改变`timescale能够减少我们的time slot数量或者总的事件量,那么对仿真时间就是有收益的,比如1ns/10ps一般比1ns/1ps快
为什么要引入event region
Race(竞争): 就是结果依赖于事件执行的相对时间和相对顺序。Verilog/Systemverilog需要面对两种常见的Race是Hardware Race和simulation race。
Hardware race是芯片工程师最熟悉的概念,这里不做介绍。
什么是simulation race?
仿真引入的race的是由于Verilog/SV采用的event-driven仿真算法产生的,由于仿真器一次只能处理一个event,因此必然会将同一个time slot的event进行排序。但在实际硬件中这些事件是同时发生的,这种仿真与实际硬件的偏差会引起额外Race,但在实际的design中并不存在,因此可能导致仿真与实际design的mismatch。正是因为这个原因Verilog中规定了一个特定的event region必须以任意的顺序来处理,但每个实现都有固定的顺序。
调度机制详解
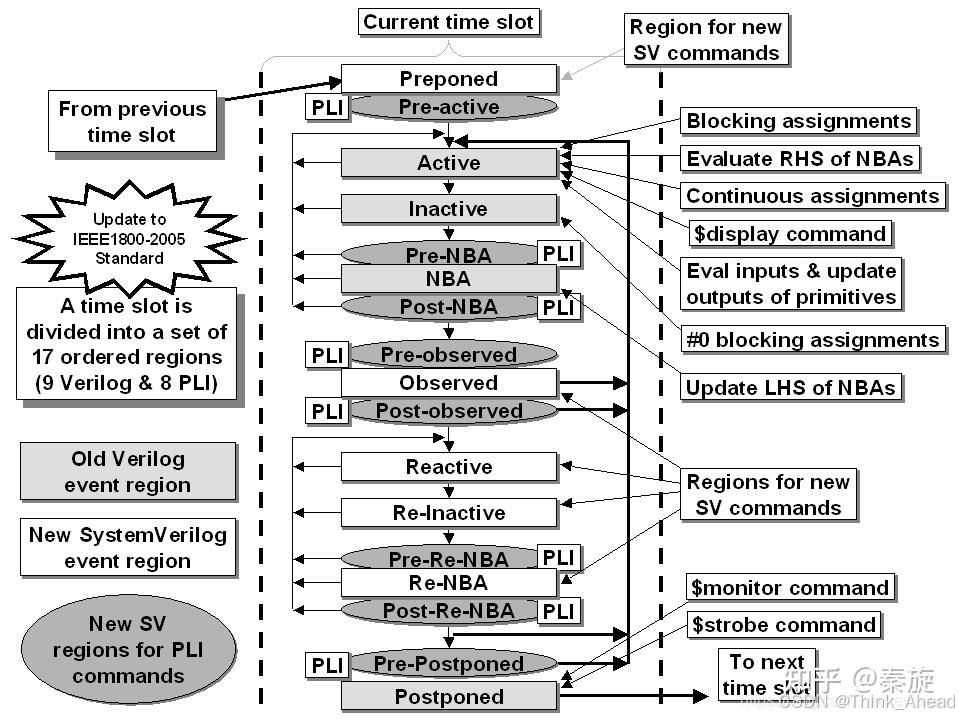
这是event region在verilog-2005里的标准定义,总共有17个Event Regions,我感觉没必要全部掌握,大家真有兴趣可以去知乎看秦旋的文章。
比如8个PLI(Programming Language Interface,用来调用其它语言的函数的接口,比如C/C++),感觉基本用不到,要用dpi还挺麻烦的,反正我一般是直接使用
initial begin
$system("echo '仿真开始' > log.txt");
$system("timeout 30 python script.py") // 调用Python脚本
end
这种,各种其他语言函数都可以通用,而且$system函数会阻塞仿真进程,直到脚本执行完毕才会继续执行后续仿真代码,很好用。
下面是一个我觉得需要掌握的——
简要流程
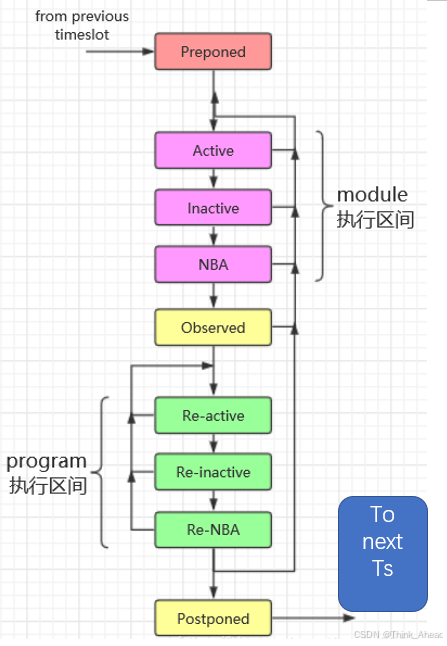
| 域名 | 作用 |
|---|---|
| preponed 前置区域 | 时间片入口,断言数据的采样时间,这时候采样数据 |
| active/inactive/NBA | module中代码执行时间 |
| active | 1.阻塞赋值\2.计算非阻塞赋值的右侧表达式(RHS即Right-Hand-Side)。并且把相应的更新事件调度至NBA Region(NBA即nonblocking assignment,非阻塞赋值)。3.连续赋值。4.调用$display系统函数。5.primitive(原语)计算。 |
| Inactive Region | #0延迟下的阻塞赋值。 |
| observed | 断言检查时间 |
| re-active/re-inactive/re-NBA | program中代码执行时间(顺序和active的差不多);执行系统函数 e x i t 及隐式的 exit及隐式的 exit及隐式的exit命令 |
| postponed | 时间片出口,调用 m o n i t o r 和 monitor和 monitor和strobe系统函数 |
看图表我们发现:
图表总结
1.非阻塞赋值其实是分成了两个步骤,先计算RHS,再更新LHS,中间会去完成其它事件的调度和计算。而阻塞赋值两步同时执行,不存在中间插入其它事件的情况。
2.2005标准相对2001标准引入了program,多了Reactive Region set(Reactive、Re-Inactive、Re-NBA),将验证代码和设计代码区域区分开了,减少了竞争冒险。
3.图表中也看出来为什么我们一般推荐使用
asign而不是always @(*),因为连续赋值语句会在0时刻进行触发,以便传递常值;而always的阻塞赋值没有这个效果
2.大家可能喜欢用#0延迟去消除对同一变量赋值所引起的竞争,但是其实按照编码规范来,你就不应该在多个always对同一个变量进行阻塞赋值,所以理论上就不应该用到#0的阻塞赋值,当时很多时候其实组合逻辑的赋值很难合到一个一个块内,特别是仿真的时候,在逻辑先后明确的时候使用Inavtive Region也无可厚非(写设计的时候就别用了)。
虽然Inactive Region不推荐使用,但是Re-Inactive Region还是有一些独特的价值的,比如开一些后台fork时,你希望新开的子进程优先于父进程执行,就可以这样操作:
program test;
initial begin
fork
process1;
process2;
process3;
join_none
#0;
//todo, parent process continues
end
endprogram
这样就巧妙的用#0 让父进程在re-inactive region再执行了,是不是挺高级。
还是挺复杂的,
如果你没有理解这几张图表,你可能还需要再去了解一些概念
sv的一些语法特性
自动推断长度
wire[7:0] signal1, signal2, signa13;
assign signal1 = '1; // equal with assign test_ signal1 = 8'b11111111
assign signal2 = '0; // equal with assign test_ signal2 = 8‘h00
assign signal3 = 'x; // equal with assign test_ signal3 = 8 ' bxxXXXXXx
支持string、real等
logic
logic 不支持 multidriver
如果要写三态门,比如pad的那种inout端口,还是需要wire
string
string s=“sv”
或者
bit [7:0]d =“sv”
string array
| Method | Description | Syntax & Usage |
|---|---|---|
len() | 返回字符串长度 | function int len();str.len(); |
putc() | 替换字符串中指定位置的字符 | task putc(int i, byte c);str.putc(i, c); |
getc() | 返回字符串指定位置的ASCII码值 | function byte getc(int i);str.getc(i); |
compare() | 字符串对比(区分大小写) | function byte compare(string str);result = str.compare(target_str); |
icompare() | 字符串对比(不区分大小写) | function byte icompare(string str);result = str.icompare(target_str); |
substr() | 返回从位置 i 到 j 的子字符串 | function string substr(int i, int j);sub_str = str.substr(i, j); |
array
int array[1:2]={3,4}
定宽数组
// 固定大小数组声明
int fix_arr[8]; // 8元素整型固定数组,是简写方式,完全写是int fix_arr[0:7];
bit [3:0] rd_arr[3] = ‘{1,3,5,7}; // 4位宽数组初始化(注意实际元素个数与声明大小不匹配)
initial begin
// 使用for循环遍历数组(存在潜在越界风险)
for(int i=0; i<4; i++) begin // 数组大小声明为3,但循环到i<4会导致越界
rd_arr[i] = 2; // 按索引访问
end
// 使用foreach安全遍历数组
foreach(rd_arr[i]) begin // 自动适配数组维度
rd_arr[i] = 2; // 按索引访问
end
end
动态数组
int rd_arr[]; //dynamic array
Int arr_size;
initial begin
rd_arr=new[4]; //create array : dimension 4.
for(int i=0; i<rd_arr.size; i++) begin //using for and foreach trace array
rd_arr[i]=2; //access by index
end
arr_size=rd_arry.size; //size 4
rd_arry=new[16] (rd_arr) ; //resize to 16: keep values,直接括号里给一个定宽数组也可以
arr_size=rd_arry.size; //size 16
rd_arry.delete(); //size 0
end
clock blocking
为什么要使用clock blocking?(以下简称cb)
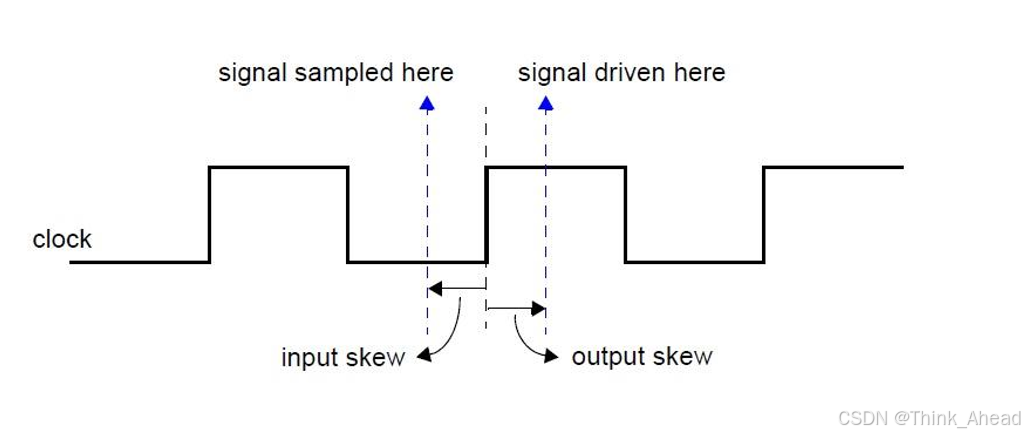
因为DV要假定该RTL将来综合后的电路在timing上没有问题,因此我们可以考虑利用Clocking blocks来构造一个理想的驱动和采样interface的环境。
语法示例:
clocking cb1 @(posedge clk)
default input #1step output (`CYCLE * 0.2);
input <list of all inputs> ;
output <list of all outputs>;
endclocking
这里需要注意的是:
1.cb的input是dut的output,cb的output是dut的input,验证的端口和设计的端口是相反的;
2.default的delay最好不要直接赋多少ns,这样会和仿真时clk的时钟频率相媾和,是不好的coding style
错误示范:
interface dut_if (input clk);
logic [15:0] dout;
logic [15:0] din;
logic ld, inc, rst_n;
clocking cb1 @(posedge clk);
default input #1ns output #1ns ;
input dout;
output din;
output ld, inc, rst_n;
endclocking
endinterface
正确示范
interface dut_if (input clk);
logic [15:0] dout;
logic [15:0] din;
logic ld, inc, rst_n;
clocking cb1 @(posedge clk);
default input #1step output `Tdrive;
input dout;
output din;
output ld, inc, rst_n;
endclocking
endinterface
在SystemVerilog的clocking block中,#1step和(\CYCLE * 0.2)`分别控制输入采样和输出驱动的时序,具体作用如下:
- #1step(输入采样偏移)
含义:表示输入信号在时钟事件(posedge clk)前1个仿真时间步的Postponed区域采样[1][9]
作用:
避免采样时的竞争条件(RACE)
确保采样到的是时钟边沿前的稳定值
1step是SystemVerilog特殊时间单位,等于当前时间精度(如timescale 1ns/1ps中为1ps)[9] - (\CYCLE * 0.2)
(输出驱动偏移) 含义:表示输出信号在时钟事件(posedge clk)后0.2个时钟周期驱动[2][4] 作用: 模拟实际电路中的信号传播延迟 确保DUT在时钟边沿后稳定阶段接收到信号 假设CYCLE是宏定义的时钟周期值(如define CYCLE 10ns),则实际驱动时间为2ns后[4][9] 配置对比 类型 偏移量 时序行为 典型应用场景 输入 #1step 时钟边沿前采样稳定值 避免亚稳态 输出 (\CYCLE*0.2)时钟边沿后延迟驱动 模拟物理延迟
enum
typedef enum {busy, idle} st_e; //named enum type
st_e st;
enum {start, do, end} a_st_e; //un-name enum type
initial begin
st=idle;
a_st_e=do;
st=st_e’(1);
st=0; //not legal 但其实至少vcs可以跑,只是有个warning这种
end
enum会自动推断状态代号的值,比如在以下代码中Start=0; do=1; end=2;
busy=0, idle=1
typedef enum {busy, idle} st_e; //named enum type
st_e st;
enum {start, do, end} a_st_e; //un-name enum type
initial begin
st=idle;
a_st_e=do;
st=st_e’(1);
st=0; //not legal
end
但是必须每个状态是唯一的
typedef enum {start=1, do, end=6, re-start} st_e; //named enum type
typedef enum {start=1, do, end=2, re-start} st_e; //语法报错,do和end都是2
结语
sv的复习就先到这啦,还有写语法特性,比如user define type,queue等,以及后面的面向对象的class等的用法,之后再介绍吧,感觉这种语法的东西多写写就会了,单独学学了也忘,后面先介绍uvm和sva吧,sv的知识点遇到了再发布。

















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









