






 本文提出了一种新的跟踪方法,利用编码器-解码器结构来建模目标物体与搜索区域的时空依赖,通过解码器预测目标位置,简化了现有跟踪流程。STARK将对象跟踪转化为边界框预测,适用于端到端学习,无需后处理。
本文提出了一种新的跟踪方法,利用编码器-解码器结构来建模目标物体与搜索区域的时空依赖,通过解码器预测目标位置,简化了现有跟踪流程。STARK将对象跟踪转化为边界框预测,适用于端到端学习,无需后处理。
STARK
Abstract
在本文中,我们提出了一种以编码器-解码器转换器为关键元件的跟踪结构。编码器对目标物体和搜索区域之间的全局时空特征依赖关系进行建模,而解码器学习查询嵌入来预测目标物体的空间位置。我们的方法将对象跟踪转换为直接的边界框预测问题,而不使用任何建议或预定义的锚。使用编码器-解码器转换器,对象的预测只使用一个简单的全卷积网络,它直接估计对象的角。整个方法是端到端的,不需要任何后处理步骤,如余弦窗口和边界盒平滑,从而大大简化了现有的跟踪管道。
Introduction
1、卷积核并不擅长模拟图像内容和特征的长期依赖关系,因为它们只处理空间或时间上的局部邻域。
2、目前流行的跟踪器,包括离线Siamese跟踪器和在线学习模型,几乎都是建立在卷积运算之上的。因此,这些方法仅在图像内容的局部关系建模方面表现良好,而在捕获远程全局交互有所限制。
3、空间信息和时间信息对目标跟踪都很重要,前者包含用于目标定位的物体外观信息,后者包含物体跨帧的状态变化信息。以前的Siamese跟踪器仅利用空间信息进行跟踪,而在线方法使用历史预测进行模型更新。虽然这些方法是成功的,但它们并没有明确地模拟空间和时间之间的关系。
4、提出了一种新的基于编码器-解码器转换器的时空结构,用于视觉跟踪。新架构包含三个关键组件:编码器、解码器和预测头。编码器接受初始目标对象、当前图像和动态更新模板的输入。编码器中的自关注模块通过特征依赖关系来学习输入之间的关系。由于模板图像在整个视频序列中不断更新,编码器可以同时捕获目标的空间和时间信息。解码器学习查询嵌入来预测目标物体的空间位置。基于角点的预测头用于估计当前帧中目标物体的边界框。同时,分数头来控制动态模板图像的更新。
Related Work
我们的工作受到最近的工作DETR[5]的启发,但有以下根本区别。
(1)学习任务不同。
DETR是为目标检测而设计的,而这项工作是为目标跟踪而设计的。
(2)网络输入不同。
DETR将整个图像作为输入,而我们的输入是由一个搜索区域和两个模板组成的三元组。它们的主干特征首先被平面化和连接,然后发送到编码器。
(3)查询设计和训练策略不同。
DETR使用100个对象查询,并在训练期间使用匈牙利算法将预测与事实相匹配。相比之下,我们的方法只使用一个查询,并且总是将其与基本事实相匹配,而不使用匈牙利算法。
(4)boundingbox head 不同。
DETR使用一个三层感知器来预测boundingbox。我们的网络采用corner-based box head,以实现更高质量的定位。
为了在空间维度上提取模板与搜索区域之间的关系,大多数跟踪器采用了相关变量,包括naive correlation、the depth-wise correlation 和the point-wise correlation。尽管近年来取得了显著的进展,但这些方法仅仅捕获了局部相似度,而忽略了全局信息。相比之下,transformer的自关注机制可以捕获远程关系,使其适合于成对匹配任务。
Method
3.1 A Simple Baseline Based on Transformer
提出了用于视觉跟踪的时空变压器网络,称为STARK。为了清楚起见,我们首先介绍一个简单的基线方法,它直接应用原始编码器-解码器转换器进行跟踪。基线法只考虑空间信息,取得了令人印象深刻的效果。之后,我们扩展基线以学习目标定位的空间和时间表征。我们引入了一个动态模板和一个更新控制器来捕捉目标对象的外观变化。
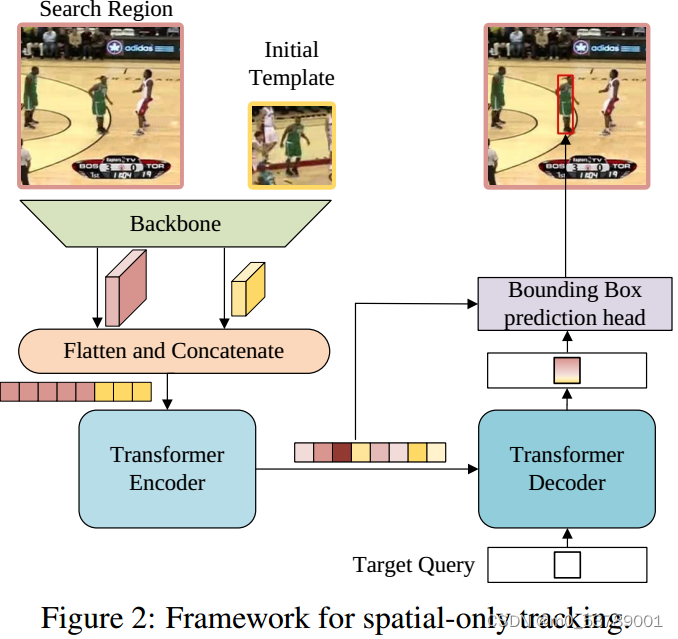
提出了一种基于视觉变换的简单基线框架,用于目标跟踪。网络架构如图2所示。它主要由三个部分组成:卷积主干、编解码器transformer和bounding box prediction head。
Backbone
可以使用任意卷积网络作为特征提取的主干。在不失通用性的前提下,我们采用了普通的ResNet作为主干。更具体地说,除了删除最后一层和全连接层外,原始ResNet没有其他变化。
Encoder
从主干输出的特征映射在输入到编码器之前需要进行预处理。具体来说,首先使用瓶颈层将通道数从C减少到d。然后将特征映射平面化并沿着空间维度进行连接,该序列作为变压器编码器的输入。编码器由N层编码器组成,每层编码器由一个带有前馈网络的多头自注意模块组成。编码器捕获序列中所有元素之间的特征依赖关系,并用全局上下文信息强化原始特征,从而使模型能够学习用于对象定位的判别特征。
Decoder
解码器将目标查询和来自编码器的增强特征序列作为输入。与采用100个对象查询的DETR不同,我们只在解码器中输入一个查询来预测目标对象的一个边界框。此外,由于只有一个预测,我们去掉了DETR中用于预测关联的Hungarian算法。与编码器类似,解码器堆叠M个解码器层,每个解码器层由自注意、编码器-解码器注意和前馈网络组成。在编码器-解码器注意模块中,目标查询可以关注模板上的所有位置和搜索区域特征,从而学习最终边界框预测的鲁棒表示。
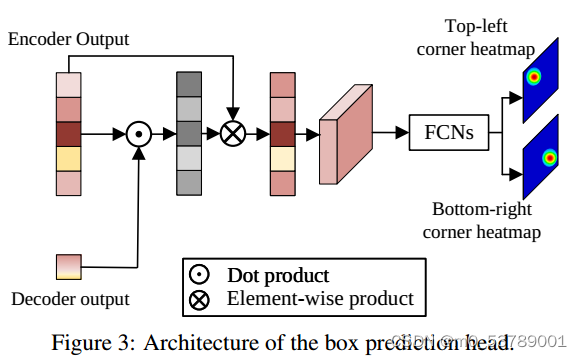
Head
首先从编码器的输出序列中提取搜索区域特征,然后计算搜索区域特征与解码器的输出嵌入之间的相似度。
接下来,将相似性分数与搜索区域特征进行逐元素地相乘,以增强重要区域并削弱不太区分的区域。将新的特征序列重构为特征映射f∈R dx × Hs × Ws,然后将其输入到简单的全卷积网络(FCN)中。
在推理过程中,模板图像及其特征由第一帧初始化,并在后续帧中固定。在跟踪过程中,在每一帧中,网络从当前帧中选取一个搜索区域作为输入,并返回预测框作为最终结果,不使用任何后处理。
3.2 Spatio-Temporal Transformer Tracking
Input
除了来自初始模板的空间信息外,动态模板还可以捕获目标外观随时间的变化,提供额外的时间信息。与第3.1节中的基线架构类似,三元组的特征映射被平面化并连接,然后发送给编码器。该编码器通过在空间和时间维度上对全局关系进行建模来提取判别性的时空特征。
Head
在跟踪过程中,有些情况下不应该更新动态模板。例如,当目标被完全遮挡或移出视野时,或者当跟踪器漂移时,裁剪模板是不可靠的。为简单起见,我们认为只要搜索区域包含目标,动态模板就可以更新。为了自动确定当前状态是否可靠,我们添加了一个简单的分数预测头,它是一个三层感知器,然后是一个sigmoid激活。如果分数高于阈值τ,则认为当前状态是可靠的。
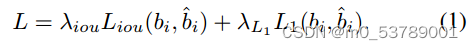
正如最近的研究所指出的那样,联合学习定位和分类可能会导致两个任务的次优解,这有助于解耦定位和分类。因此,我们将训练过程分为两个阶段,将定位作为首要任务,分类作为次要任务。具体来说,在第一阶段,除了分数头外,整个网络都是端对端训练,只使用等式1中与定位相关的损失。在这个阶段,我们保证所有的搜索图像都包含目标物体,并让模型学习定位能力。在第二阶段,只对分数头进行优化,将二值交叉熵损失定义为
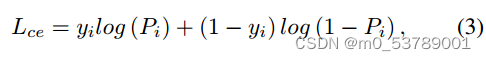
其中yi为groundtruth标签,Pi为预测置信度,其他参数均被冻结以避免影响定位能力。这样,经过两个阶段的训练,最终的模型同时学习了定位和分类能力。
在推理过程中,在第一帧初始化两个模板和相应的特征。然后将搜索区域裁剪并输入到网络中,生成一个边界框和置信度评分。只有当达到更新间隔且置信度评分高于阈值τ时,才会更新动态模板。为了提高效率,我们将更新间隔设置为Tu帧。新模板从原始图像中裁剪出来,然后输入到主干中进行特征提取。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









