







分区
一般情况下创建的表对应一组存储文件,当数据量较大时MySQL的性能就开始下降
解决方案:如果数据表中的数据具有特定业务含义数据的特性,可以将表中数据分散到多个存储文件中,以保证单个文件的执行效率。
最常见的分文件的方法是按照id值进行分区,不同的分区对应不同的存储问题。采用id的hash值进行分区,实际上就是对10进行取模,可以将数据均匀的分散到10个文件中
create table tb_article(
id int primary key,
title varchar(32),
content mediumtext
) partition by hash(id) partitions 10;-- 按照id的hash值进行分区,总共分为10个区
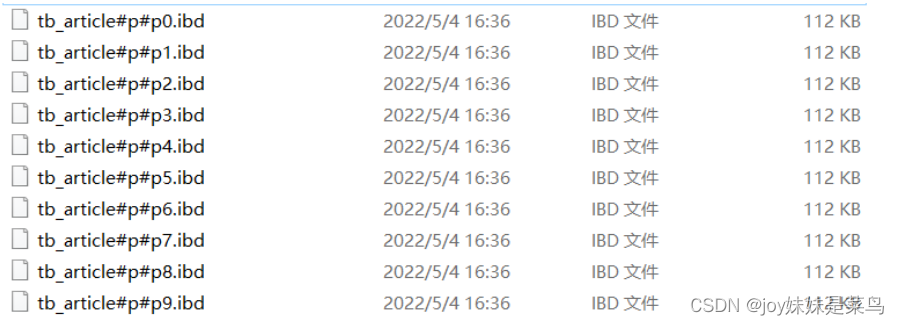
服务器端的表分区对客户端都是透明的,客户端还是照常插入数据,但是服务器端会按照设定的分区算法分散存储数据
PreparedStatement ps = conn.prepareStatement("insert into tb_article values(?,?,?)");
for (int i = 0; i < 10000; i++) {
ps.setInt(1, i+1);
ps.setString(2, i + "_name");
ps.setString(3, i+"_content");
ps.executeUpdate();
}
InnoDB逻辑存储结构
InnoDB中所有的数据都被逻辑地存放在表空间,表空间又由段、区、页组成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t76SrBar-1652268755542)(C:\Users\pon18\AppData\Roaming\Typora\typora-user-images\image-20220509222233621.png)]](https://i-blog.csdnimg.cn/blog_migrate/e58da8eec904d4ff078a0063db13c3a7.png)
段
segement区域。常见的段有数据段、索引段、回滚段等,在InnoDB存储引擎中,对段的管理都是由引擎自身所完成的
区
extent区域。区是由连续的页组成的空间,无论页的大小怎么变,区的大小默认总是为1MB
为了保证区中的页的连续性,InnoDB存储引擎一次从磁盘申请4-5个区,InnoDB页的大小默认为16kb,即一个区一共有64(1MB/16kb=16)个连续的页。
每个段开始,先用32页(page)大小的碎片页来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表或者是undo类的段,可以开始申请较小的空间,节约磁盘开销。
页
page区域,也叫块。页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置。
常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
分区算法分类
MySQL支持的常见分区类型有Range、List、Hash、key分区,其中range最为常见
- Range范围:允许将数据划分到不同的范围,例如可以将一个表通过年份划分成若干个分区
- List预定义列表:允许系统通过预先定义的列表的值将数据进行分割
- hash哈希:允许通过对表中的一个或者多个列的hash key进行计算,最后通过这个hash码将数据对应到不同的分区
- key键值:是hash分区的而一种扩展,这里的hash key是由mysql系统产生的
- 复合模式:多种模式的组合使用,例如对已经进行了range分区的表上,对其中的分区再次进行hash分区
指定分区中的列名称时需要使用主键列或者主键中的一部分,否则设置失败
hash哈希分区
一般永不不按照业务规则进行数据文件的均匀拆分,输出的结果和输入是否有规律无关,仅适用于整型字段
create table tb_emp(
id int primary key
auto_increment,
name varchar(32) not null,
hiredate date default '1989-2-3'
)partition by hash(id) partitions 4;
一般要求hash中的值最好有一定的线性关系,否则分区数据将不能均匀分布。
key关键字分区
key用于处理字符串,比hash()多一步从字符串中计算出一个整数,然后再进行取模计算
create table tb_article(
id int auto_increment,
title varchar(64) comment '文章标题',
content text, primary key(id,title)
)partition by key(title) partitions 10;
range范围分区
range是按照一种指定数据的大小范围进行分区,例如按照文章的发布时间将数据分区存放
获取时间戳select unix_timestamp('2022-4-30 23:59:59 ') 1651334399
select unix_timestamp('2022-3-31 23:59:59 ') 1648742399
create table tb_article(
id int auto_increment,
title varchar(32) not null,
pub_date int, primary key(id,pub_date)
) partition by range(pub_date)(
-- 2022年3月和以前的数据
partition p202203 values less than (1648742399),
-- 2022年4月的数据
partition p202204 values less than (1651334399),
-- 2022年4月以后的数据
partition p202205 values less than maxvalue
);
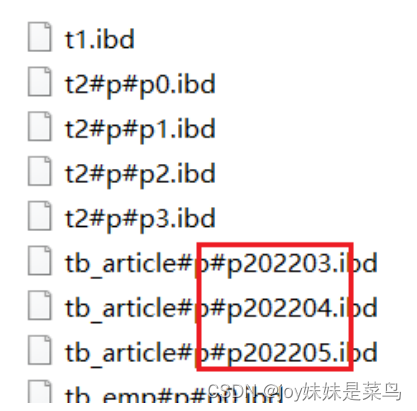
其中maxvalue表示最大值。MySQL允许在分区键中使用null,分区键允许是一个字段,也可以是一个表达式。一般MySQL的分区会把null当作0或者最小值进行处理。需要注意:range中null当作最小值;list中null必须出现在枚举列表中,否则不作处理;hash或者key分区中null被当作0值处理
条件运算符只能使用less than,所以要求小值在前
list列表分区
列表分区也是一种条件分区,使用列表值进行分区。列表值应该是离散值,而范围分区是连续值
create table tb_article(
id int auto_increment,
title varchar(32) not null status tinyint(1), -- 用于表示文章的状态,例如0草稿、1完成未发布、2已发布、3下架
primary key(id,status)
)partition by list(status)(
partition writing values in (1,0), -- 表示正在写的文章
partition publishing values in(2,3) -- 表示已经完成的文章
);
分区管理
range/list增加分区
针对文档数据采用年份和月份归档,随着时间的推移新增一个月份
alter table tb_article add partition(
-- 业务规则应该是小于2022-05-31 23:59:59
partition p202205 values less than (1654012799)
)
删除指定名称对应的分区
alter table tb_article drop partition p202205;
注意:删除分区后,分区中对应的数据也会随之删除
key/hash新增分区
alter table tb_article add partition paratitions 5;
销毁分区
alter table tb_article coalesce partition 6;
key和hash分区的管理不会删除数据,但是每一条调整分区,会对所有数据重写分配到新的分区上。所以效率极低。一般强烈建议:要求在设计阶段就考虑好分区策略
分区查询
当数据表中的数据量非常大时,分区才能带来效率提升,否则性能提升不明显。
只有检索字段为分区字段时,分区带来的效率提升才能显示出来。
分区字段的选择非常重要,并且业务逻辑要尽可能的根据分区字段做相应调整。
-
指定分区查询:
select * from table partition (pname) -
mysql可以根据查询条件判断在哪个分区中,如果不能确定则查询全部
表分区的用途
-
逻辑数据分割
-
提高单一的写入或者读取的应用速度
-
提高分区范围查询的速度
-
分割数据能够有多个不同的物理文件路径
-
高效的保存历史数据
常见的数据库对象
| 对象 | 描述 |
|---|---|
| 表(TABLE) | 表是存储数据的逻辑单元,列是字段,行是记录 |
| 数据字典 | 系统表,存放数据库相关信息的表。系统表的数据通常由数据库系统维护,程序员通常不应该修改,只可查看 |
| 约束(CONSTRAINT) | 执行数据校验的规则,用于保证数据完整性的规则 |
| 视图(VIEW) | 一个或者多个数据表里的数据的逻辑显示,视图并不存储数据 |
| 索引(INDEX) | 用于提高查询性能,相当于书的目录 |
| 存储过程(PROCEDURE) | 用于完成一次完整的业务处理,没有返回值,但可通过传出参数将多个值传给调用环境 |
| 存储函数(FUNCTION) | 用于完成一次特定的计算,具有一个返回值 |
| 触发器(TRIGGER) | 相当于一个事件监听器,当数据库发生特定事件后,触发器被触发,完成相应的处理 |
视图
视图概述
-
MySQL视图是一种虚拟存在的表,由行列构成,但实际并不存在于数据库,也不具有数据。行和列的数据来自于定义视图的查询中所使用的表,并在使用视图时动态生成
-
视图建立在已有表的基础上,视图赖以建立的表称为基表
- 视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
- 视图是向用户提供基表数据的另一种表现形式。通常在大型项目中,以及数据表比较复杂的情况下,视图可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。
视图和基表
区别
-
视图不是真实的表,是一个虚拟表,其结构和数据都是建立对基表真实查询的基础上
-
存储在数据库中的查询操作定义了视图的内容和结构,视图的行和列的数据来自于查询所引用的实际表,引用视图时动态生成
-
视图没有实际的物理记录,数据集实际存储在基表中
-
视图是数据的窗口,基表才是真实内容。视图是查看数据表的一种方式。从安全的角度上来看,视图的数据安全性高,使用视图的开发人员不涉及数据表,甚至可以不知道基表的真实结构
-
视图的创建和删除只影响视图本身,不会影响对应的基本表
具体举例讲解
基表是用于存储真实数据
create table tb_dept(
id bigint primary key auto_increment,
name varchar(32)
);
-- 向基表中插入数据
insert into tb_dept(name) values('教学部'),('市场部'),('咨询部');
create table tb_emp(
id bigint primary key auto_increment,
name varchar(32) not null,
dept_id bigint not null,
foreign key(dept_id) references tb_dept(id) on delete cascade
);
insert into tb_emp(name,dept_id) values('严峻',1),('小党',3),('大展',2);
创建视图
基础语法:create view 视图名称 as 查询语句;
-- 举例
create view v_emp
as
select e.id empno, e.name as ename,d.name dname from tb_emp e inner join tb_dept d on e.dept_id=d.id
视图是一个虚表,其中并不直接存储数据,但是可以当作表的方式进行使用,具体数据来源于定义视图的查询结果集
-- 查询视图
select * from v_emp;
查看视图
查看视图的结构desc 视图名称;
mysql> desc v_emp;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| empno | bigint(20) | NO | | 0 | |
| ename | varchar(32) | NO | | NULL | |
| dname | varchar(32) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
查看视图的定义,可以查看创建视图对应的SQL语句
show create view v_emp;
插入数据到视图【注意增删改的要求是一致的】
create view v_emp1 as select * from tb_emp where id>1;
insert into v_emp1 values (4,'熊二',1); -- 插入成功
因为向视图中插入数据实际上就是向基本表中插入数据,也就是执行 insert into v_emp1 values (4,'熊二',1);操作就是向基本表 tb_emp 中插入数据,只要没有违反基本表中的约束规则,则插入成功
select * from tb_emp;
mysql> insert into v_emp1 values (4,'熊二',1);
ERROR 1062 (23000): Duplicate entry '4' for key 'PRIMARY'
视图的数据来自于两个表的查询结果
mysql> desc v_emp;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| empno | bigint(20) | NO | | 0 | |
| ename | varchar(32) | NO | | NULL | |
| dname | varchar(32) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
insert into v_emp values(5,'哈哥','教学部');
ERROR 1394 (HY000): Can not insert into join view 'test.v_emp' without fields list
create view v_emp2 as select e.*,d.* from tb_emp e inner join tb_dept d on e.dept_id=d.id;
-- ERROR 1060 (42S21): Duplicate column name 'id'
create view v_emp2 as select e.*,d.id did, d.name dname from tb_emp e inner join tb_dept d on e.dept_id=d.id;
desc v_emp2;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | bigint(20) | NO | | 0 | |
| name | varchar(32) | NO | | NULL | |
| dept_id | bigint(20) | NO | | NULL | |
| did | bigint(20) | NO | | 0 | |
| dname | varchar(32) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
insert into v_emp2(id,name,dept_id,did,dname) values(6,'小哥',1,null,'研发 部');
-- ERROR 1393 (HY000): Can not modify more than one base table through a join view 'test.v_emp2'
insert into v_emp2(id,name,dept_id) values(6,'小哥',1);
-
允许针对视图进行数据的修改操作,但是不允许同时修改多于一个基表
-
如果数据是通过计算得到的,也不能修改
- distinct、group by、having、union和union all
-
视图的修改实际上是针对基表数据的修改,不允许违反基本的约束规则
-
视图允许嵌套,就是 create view v_emp3 as select * from v_emp1
修改视图
当基表的结构发生变化时,可以修改视图定义。但是如果在视图定义中使用的列没有修改,则无需修改视图定义
语法: alter view 视图名称 as 新的查询语句;
删除视图
删除视图实际上就是删除视图的定义,不会删除数据
语法:drop view if exists 视图名称;
-- 举例
drop view empvu80;
说明:基于视图a、b创建了新的视图c,如果将视图a或者视图b删除,会导致视图c的查询失败。这样的视图c需要手动删除或修改,否则影响使用。
总结
视图的特点
- 视图的特点:视图的列可以来自不同的表或者计算出的列,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,有时可以修改数据,有时不允许修改数据。
- 视图的操作包括创建视图,查看视图,删除视图和修改视图。
优点
1、可以从基表中进行数据定制,简化数据操作,提高数据的安全性
2、共享所需数据、修改数据格式
3、重用sql语句
库表切分
使用分区可以将数据文件的变小,在一定程度上提高查询效率,但是业务区分很困难
使用视图可以实现按需获取数据,但是所查询的数据并没有变化,所以并不能提高查询效率
引入切分的原因:
-
为数据库减压
-
分区算法的局限性
-
针对分区算法只有MySQL5.1+之后才支持
水平拆分
水平分割:通过建立结构相同的几张表分别存储数据 类似分区
能够把一个特别大的表,水平拆分到不同的数据库服务器上,来分担一个数据库服务器的压力。提高数据库的性能和效率。
优点:
-
单表的并发能力提高了,磁盘 I/O 性能也提高了。
-
如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。
缺点:
- 无法实现表连接查询。
id重复的解决方案
水平切分时要求id不能重复,常见的解决方案有2种:
1、单独创建一个表,其中只包含一个id字段,每次自增该字段作为插入数据的id使用。
2、可以借用第三方应用,例如memcache或者redis的id自增实现
垂直拆分
垂直分割:将经常一起使用的字段放在一个单独的表中,其余字段存放在另外的表中,分割后的表记录之间是一对一的关系。
可以避免所有的业务表全部放在一台MySQL数据库服务器上,通过增加MySQL数据库实例的数,来分担来自业务层模块的数据请求压力,从而达到对降低MySQL数据库的压力。
优点:
-
减少增量数据写入时的锁对查询的影响。
-
由于单表数量下降,常见的查询操作由于减少了需要扫描的记录,使得单表单次查询所需的检索行数变少,减少了磁盘 IO,时延变短。
缺点:
- 无法解决单表数据量太大的问题。
典型案例:
模式:学生(学生编号,姓名、性别、住址、大字段属性用于存放照片)
解决方案:
create table tb_student(
id bigint primary key auto_increment,
name varchar(32) not null,
sex boolean default 1
) comment '存放学生基础信息';
create table tb_student_image(
id bigint primary key,
foreign key(id) references tb_student(id) on delete cascade, -- 实现一 对一关联
photo longblob -- 如果表中有大对象字段,则一定需要进行分表处理
)comment '学生的扩展信息';

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









