







安装包可以直接去官网下载,尽量不要选择太新的版本
这里选择的是3.6.3
要先在虚拟机上安装lrzsz命令以便于我们将文件从本地上传到虚拟机
yum install lrzsz
之后把安装包上传到集群当中
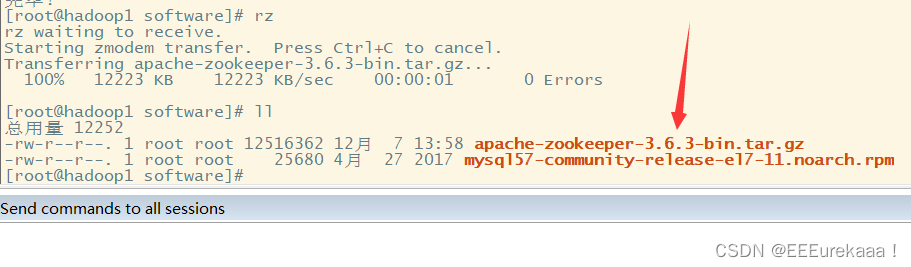
然后把zookeeper解压到servers中
tar -xzvf apache-zookeeper-3.6.3-bin.tar.gz -C ../servers

之后我们为Zookeeper配置环境变量
在文件末尾添加如下内容
#ZOOKEEPER环境变量配置
export ZOOKEEPER_HOME=/export/servers/apache-zookeeper-3.6.3-bin
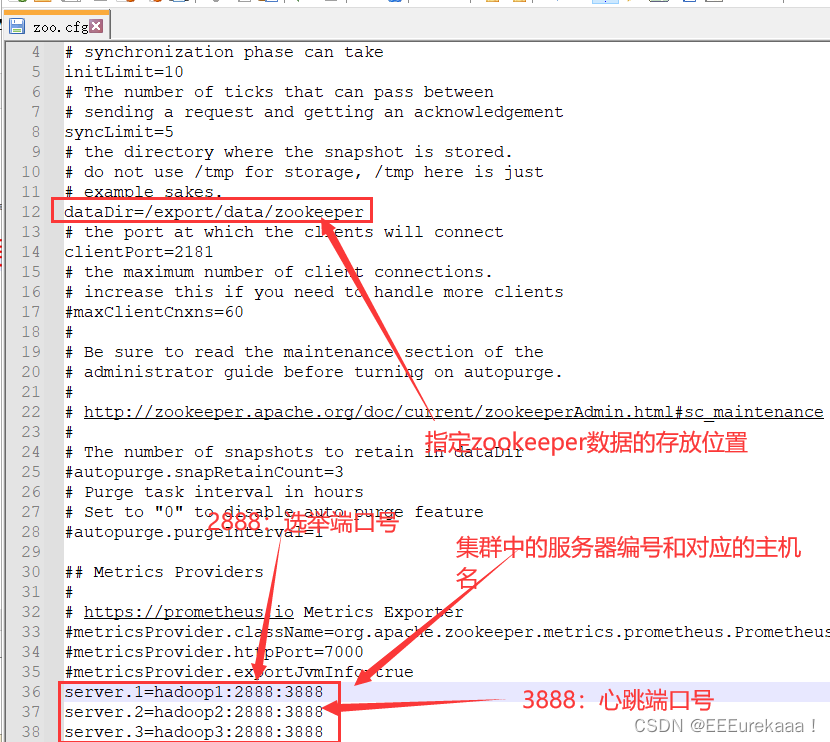
export PATH=$PATH:$ZOOKEEPER_HOME/bin之后我们配置zookeeper

复制一份然后去修改
cp zoo_sample.cfg zoo.cfg

这里使用了一个插件,notepad++,可以连接虚拟机编辑文件
创建myid文件
myid文件的数据越大,越容易被选举成为leader,这个文件的内容一般就是服务器的编号,在每个服务器上都要创建相应的目录以及该文件。
要在刚刚配置文件中指定的目录中创建myid文件

hadoop1中输入服务器编号1即可
然后我们将zookeeper和环境变量配置文件分发到hadoop2和hadoop3中
scp -r /export/servers/apache-zookeeper-3.6.3-bin hadoop2:/export/servers/
scp -r /export/servers/apache-zookeeper-3.6.3-bin hadoop3:/export/servers/
scp /etc/profile hadoop2:/etc/
scp /etc/profile hadoop3:/etc/之后我们要为他们单独创建myid文件
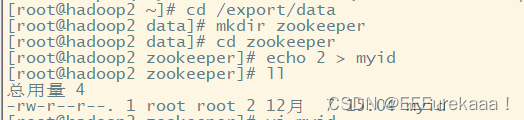
hadoop3进行同样的操作即可
之后执行 source /etc/profile
我们测试一下是否安装成功
在三台虚拟机上同时执行 zkServer.sh start
然后再用zkServer.sh status查看状态



可以看到hadoop3被选举成为了leader, 也印证了myid越大越容易成为leader
其实zookeeper有一个机制,当机器启动数量超过集群机器数量的半数时,已启动的机器中myid最大的服务器就会被选举为leader,在leader确立之后,即便有再大的myid也不会成为leader了
之后我们杀死hadoop3的zookeeper服务,来模拟服务器宕机


此时hadoop2成为了leader
此外zookeeper还有很多的机制这里不再赘述
最后我们zkServer.sh stop关闭服务即可



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











