







RevPRAG: Revealing Poisoning Attacks in Retrieval-Augmented Generation through LLM Activation Analysis
RevPRAG:通过大语言模型激活分析揭示检索增强生成中的投毒攻击
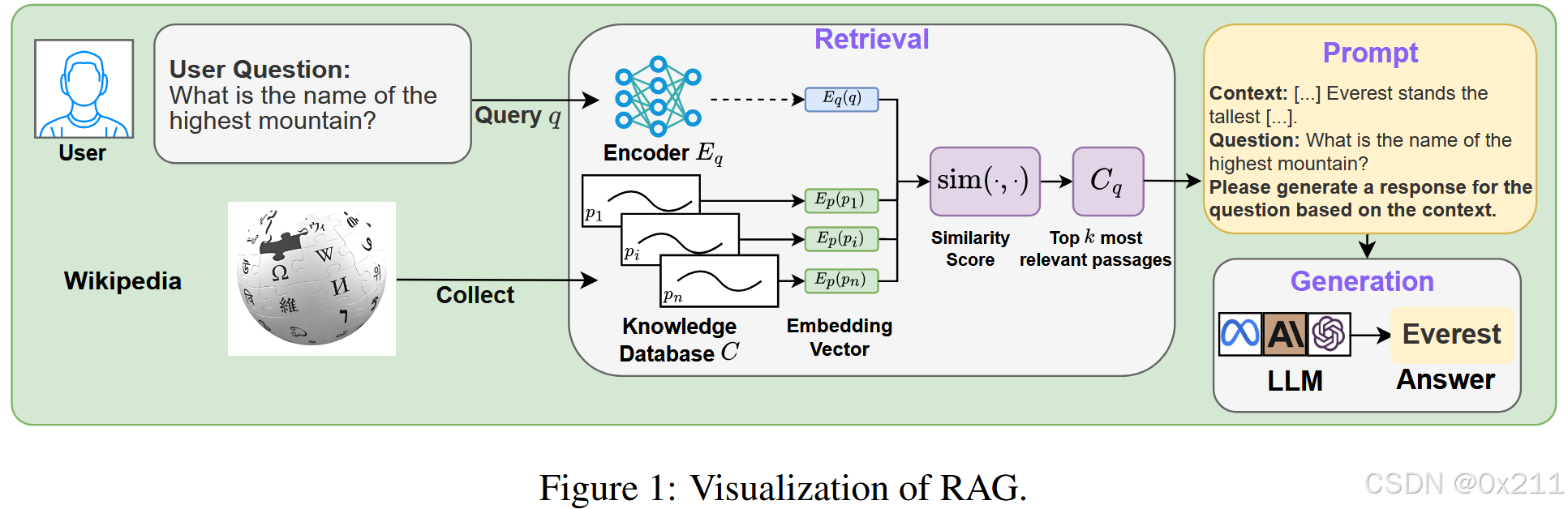
RAG 投毒攻击涉及将恶意文本注入知识库,最终导致生成攻击者目标响应(也称为投毒响应)。 但是,目前可用于检测此类投毒攻击的方法有限。 我们旨在通过引入 RevPRAG 来弥补这项工作的差距,RevPRAG 是一种灵活且自动化的检测流程,它利用大语言模型的激活来检测投毒响应。 我们的研究揭示了大语言模型在生成投毒响应与正确响应时激活模式的差异。 我们在多个基准和 RAG 架构上的结果表明,我们的方法可以达到98% 的真阳性率,同时将假阳性率保持在接近1% 的水平。
INSTRUCTRAG Wei 等人 (2024) 利用大型语言模型 (LLM) 来分析如何从嘈杂的检索文档中提取正确的答案;RobustRAG Xiang 等人 (2024) 引入多个大型语言模型 (LLM) 从检索到的文本中生成答案,然后聚合这些响应。 然而,上述防御方法需要集成额外的庞大模型,从而产生相当大的开销。 同时,很难立即评估 RAG 的当前响应是否值得信赖。
本文将重点转向利用大型语言模型 (LLM) 的内在属性来检测 RAG 污染,而不是依赖外部模型。 观点是如果可以准确地确定 RAG 的响应是正确的还是被污染的,就可以有效地阻止 RAG 污染攻击。 我们试图观察大型语言模型 (LLM) 的答案生成过程,以确定响应是否受到损害。 重点不在于检测LLM的恶意输入,因为恶意响应的后果更为有害,并且更能表明存在攻击。 使用激活来解释和控制LLM行为的越来越多的研究 Ferrando 等人 (2024); He 等人 (2024) 为我们提供了灵感。
特别地,我们实证分析了大语言模型 (LLM) 所有层中输入序列中最终符元 (token) 的激活情况。 我们的研究结果表明,通过比较大语言模型 (LLM) 在生成正确响应和中毒响应时的激活情况,可以非常有效地区分这两种类型的响应。 基于此,我们提出一个系统化的自动化检测流程,即 RevPRAG,它包含三个关键组件:中毒数据收集、大语言模型 (LLM) 激活收集和预处理以及检测模型设计。 重要的是要注意,这种检测方法不会改变检索增强生成 (RAG) 的工作流程或削弱其性能,因此与仅依赖于过滤检索文本的方法相比,它具有更好的对抗鲁棒性。
贡献:发现了当检索增强生成 (RAG) 生成正确响应与中毒响应时,大语言模型 (LLM) 激活中存在的不同模式;引入了 RevPRAG,这是一种用于检测检索增强生成 (RAG) 响应是否中毒的新型自动化流程。 为了应对新兴的 RAG 中毒攻击,RevPRAG 允许构建相应的新数据集来训练模型,从而有效检测新的威胁;已在各种大语言模型 (LLM) 架构和检索器上进行了实证验证,在我们自定义收集的检测数据集上展示了超过 98% 的准确率。
针对RAG鲁棒性的研究:RobustRAG通过投票机制减轻中毒文本的影响,而 INSTRUCTRAG明确学习去噪过程以解决中毒和无关信息。然而,这些方法一方面可能依赖于额外的 LLM,导致显著的开销。 另一方面,它们主要关注 LLM 生成响应之前的防御机制,这使得这些现有方法难以在 LLM 生成响应的同时实时检测中毒攻击。 在这项工作中,为了防御 RAG 攻击,我们提出了一种检测机制,该机制可以在模型响应生成过程中迅速捕获关键信息,并评估当前响应是否值得信赖。
攻击场景方案
使用poisonedRAG方案作为攻击方案,攻击者有一组的目标问题和对应的目标答案集合,攻击者可以为每个目标问题注入若干个中毒文本,对检索器有白盒访问权限。
基本原理
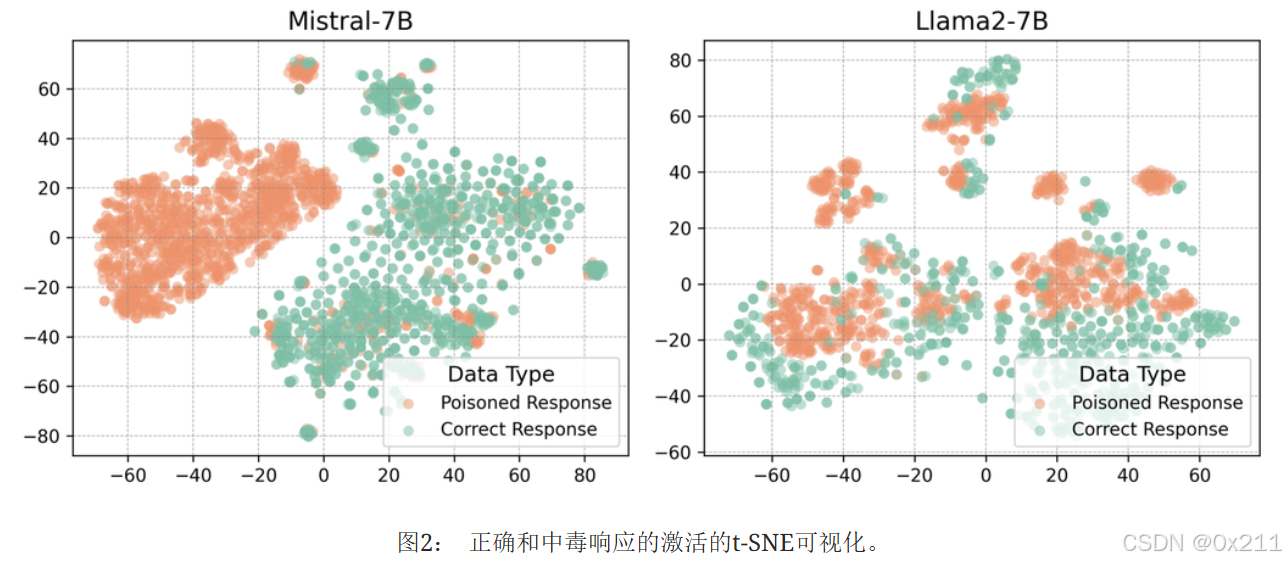
LLM的激活表示不同抽象层级的输入数据,使模型能够逐步从低级特征中提取高级语义信息。 这些激活中包含的广泛信息全面反映了LLM的整个决策过程。 激活已被应用于输出内容的事实验证He et al. (2024)和任务漂移检测Abdelnabi et al. (2024)。 由于LLM在生成不同响应时会产生不同的激活,我们假设LLM在生成中毒响应时与生成正确响应时也会表现出不同的激活。 图2 使用t-SNE(t分布随机邻域嵌入)展示了正确和中毒响应激活的可视化结果。 它可视化了在Natural Questions数据集上,Mistral-7B和Llama2-7B这两个LLM的所有层级的平均激活。 这在一定程度上清楚地证明了这两种类型的响应之间的可区分性,支持了我们的猜想。
方法
方法概述
RevPRAG ,一个旨在利用LLM激活信息来检测RAG系统中知识投毒攻击的管道。包含三个模块:投毒数据收集、激活信息收集和预处理以及RevPRAG检测模型设计。
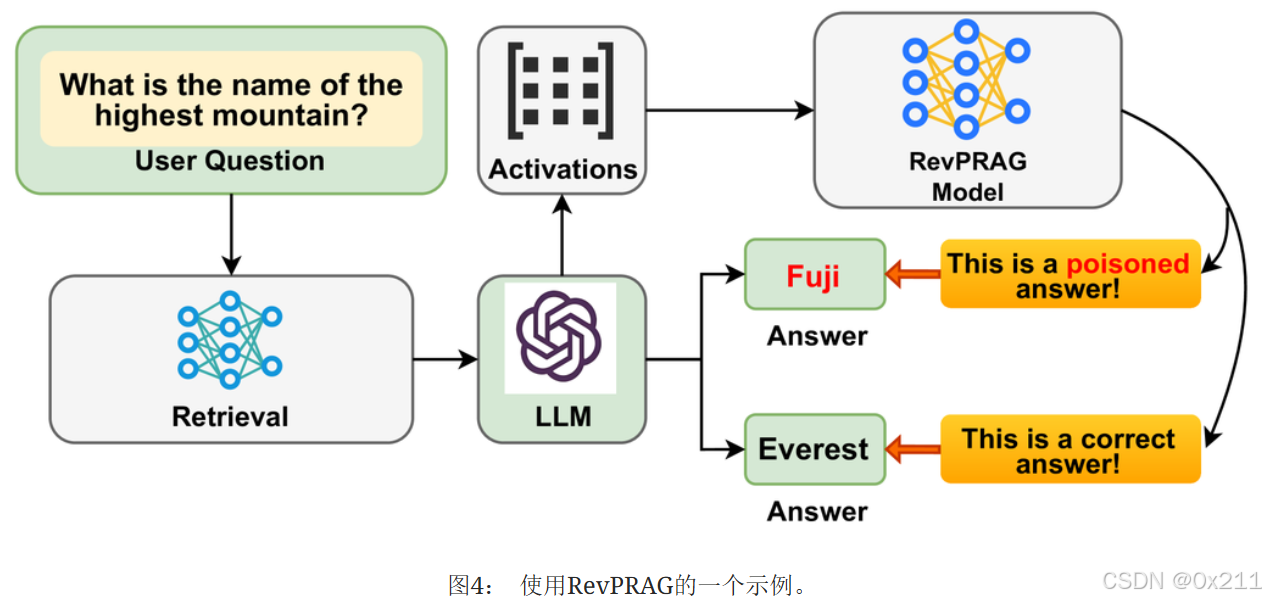
给定一个用户提示,例如“最高的山峰叫什么名字?”,LLM将提供一个回复。 同时,LLM生成的激活将在RevPRAG中收集和分析。 如果模型将激活分类为投毒行为,它将标记相应的回复(例如“富士山”)为投毒回复。 否则,它将确认回复(例如“珠穆朗玛峰”)为正确答案。
投毒数据收集
旨在提取LLM的激活,这些激活捕获模型在特定时间点接收到投毒文本后生成特定投毒响应的过程。 因此,我们首先需要在RAG上实施投毒攻击,以误导LLM生成目标投毒响应。第一步是制作足够数量的投毒文本并将其注入知识数据库。为了创建有效的投毒文本以专注于检测投毒攻击,采用了三种最先进的策略(即PoisonedRAG、GARAG和PAPRAG)来生成投毒文本并提高投毒文本与查询之间的相似性,以提高检索器选择投毒文本的可能性。 然后,检索到的文本与问题一起用于构建新的提示,以供LLM生成答案。

激活收集和处理
对于LLM输入序列X=(x1,x2,⋯,xn),提取LLM中所有层中最后一个符元xn的激活Act_n,作为上下文摘要。 这些激活Act_n包含LLM与输入相关的知识的内部表示。 当LLM根据问题生成响应时,它会遍历所有层,检索与输入相关的知识以生成答案。 如前所述,中毒响应的LLM激活与正确响应的激活之间存在显著差异。
我们引入了激活的归一化,以有效整合到训练过程中。 我们计算数据集的平均值μ和标准差σ。 然后,我们使用获得的μ和σ根据公式![]() 对激活进行归一化。 这种标准化通过统一缩放激活来提高训练效率,防止对较大特征产生偏差。 它还可以确保更平滑的优化,减轻与梯度相关的问题,并提高依赖于距离度量的算法的性能。
对激活进行归一化。 这种标准化通过统一缩放激活来提高训练效率,防止对较大特征产生偏差。 它还可以确保更平滑的优化,减轻与梯度相关的问题,并提高依赖于距离度量的算法的性能。
RevPRAG模型设计
收集和预处理激活数据集后,我们基于该数据集设计了一种探测机制。 受少样本学习和Siamese网络的启发,我们提出的RevPRAG模型擅长区分正确答案和中毒答案,并从有限的数据中展示出强大的泛化能力。
为了有效捕获大语言模型 (LLM) 不同层级之间和内部的关系,我们利用具有 ResNet18 架构的卷积神经网络 (CNN) 。 我们使用具有相同架构和权重的三元组网络来学习任务的嵌入,如图3所示。 在训练过程中,我们采用三元组边缘损失,这是一种常用于难以区分相似实例的任务的方法。 三元组边缘损失是用于训练神经网络的损失函数,用于人脸识别或目标分类等任务。 同时,三元组边缘损失也广泛应用于少样本学习场景。
当模型遇到分布外数据时,它可以利用少量支持数据快速适应,而无需重新训练整个模型。 此损失函数的目标是在高维嵌入空间(也称为特征空间)中学习相似性度量,其中相似对象的表示(例如,同一个人的图像)彼此靠近,而不同对象的表示则相距较远。
三元组边缘损失提供的这种强大的相似性度量特别适合区分 LLM 激活,使 RevPRAG 能够有效地区分由中毒攻击引起的激活差异。 三元组边缘损失的核心概念涉及使用三元组,每个三元组由一个锚样本、一个正样本和一个负样本组成。 锚样本和正样本代表相似的实例,而负样本代表不相似的实例。 该算法学习嵌入这些样本,使得锚样本和正样本之间的距离小于锚样本和负样本之间的距离。
![]()
给定训练样本 xa、xp 和 xn,它们分别代表锚点、正点和负点。 RevPRAG 嵌入模型将为任何 Acta 和 Actp 输出更接近的嵌入向量,但对于任何 Acta 和 Actn 则更远。 损失函数正式定义为:L=max(Dist(Acta,Actp)−Dist(Acta,Actn)+margin,0),其中 Dist(⋅,⋅) 表示距离度量(通常是欧几里德距离),margin 是一个正常数。 margin 的存在在三元组损失中引入了一个需要调整的附加参数。 如果 margin 太大,模型的损失将很高,并且可能难以收敛到零。 然而,更大的间隔通常会提高模型区分非常相似样本的能力,从而更容易区分Actp和Actn。 相反,如果间隔太小,损失将迅速接近零,使模型更容易训练,但它在区分Actp和Actn方面将效率降低。

直观上理解,这个东西是选用了三元组损失来建模,三元组损失需要有正样本、锚样本和负样本,因此要构建者三种类型的样本。以“最高的山是什么山”为例,“珠穆朗玛峰”这样的回答就可以作为锚样本,其他正确回答例如“最高的山是珠穆朗玛峰”这样因为语义和性质与锚样本相似,就作为正样本。就像对比学习一样,目标是让锚样本更偏向于正样本。
评估
实验设置
知识库:NQ、HotpotQA、MS-MARCO,从每一个知识数据库中都选择了3000个三元组(问题,文档,正确答案),训练、测试和支持占比7:2:1
三种投毒方案生成恶意文本:PoisonedRAG。GARAG和Corpus Poisoning
检索器:Contriever,Contriever-ms,DPR-mul和ANCE,相似度使用点积,top-K中k取5
baseline:目前还没有专门针对RAG投毒攻击的专用检测方法或评估。 因此,我们扩展了两种现有方法Li等人 (2024)和Xi等人 (2024),用于RAG场景。 CoS【Chain-of-scrutiny: Detecting backdoor attacks for large language models】是一种黑盒方法,它引导LLM为输入生成详细的推理步骤,随后仔细检查推理过程以确保其与最终答案一致。 MDP【Defending pre-trained language models as few-shot learners against backdoor attacks】是一种白盒方法,它利用中毒样本和干净样本之间掩蔽敏感性的差异。
评估指标: 真正率 (TPR),衡量有效检测到的中毒响应的比例。 假阳性率 (FPR),量化被错误分类为由中毒攻击引起的正确响应的比例。
结果
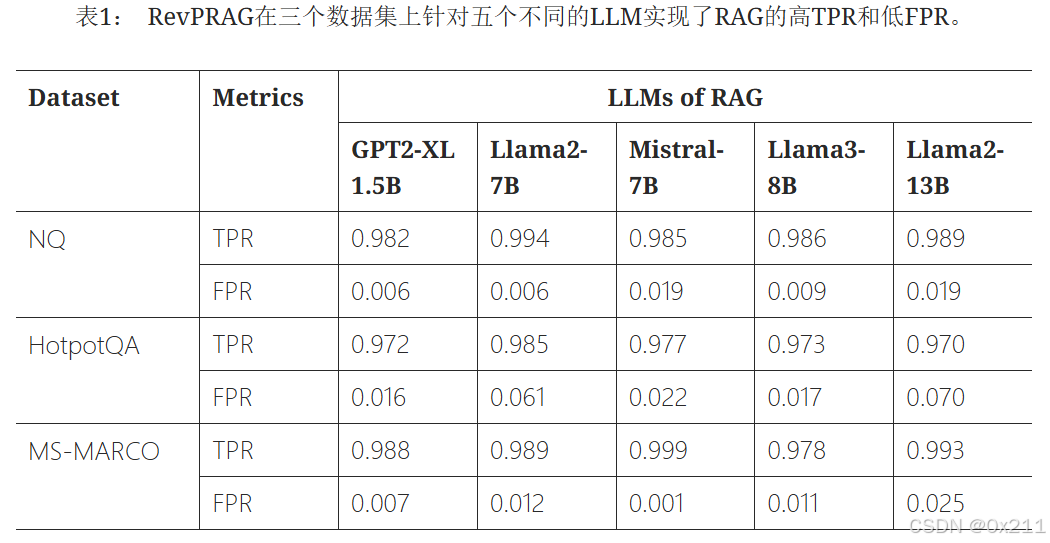
RevPRAG实现了高TPR和低FPR。 实验结果表明,基于LLM的激活来评估RAG系统的输出是正确还是中毒,既是高度可行且可靠的(即能够实现极高的准确性)。 其次,RevPRAG在不同的设置下都实现了较低的FPR,例如,在几乎所有情况下都接近1%。 此结果表明,我们的方法不仅最大限度地检测到了中毒响应,而且保持了较低的误报率,从而显著降低了将正确答案误分类为中毒响应的风险。
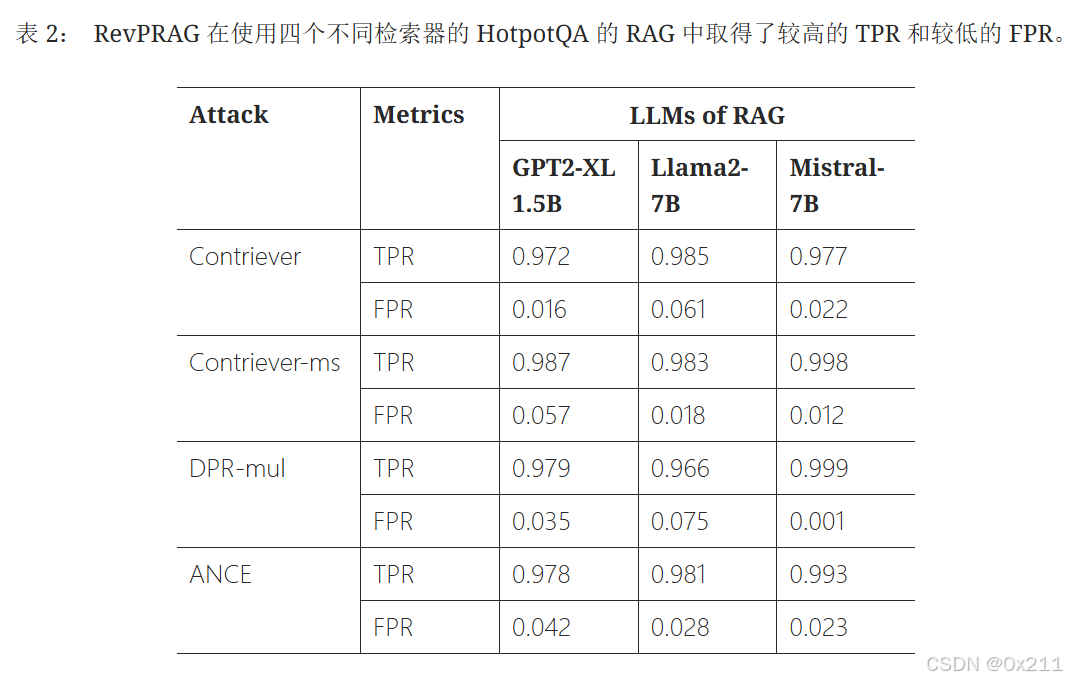
结果表明,我们的方法在使用各种检索器和大型语言模型的 RAG 中始终取得了较高的 TPR 和较低的 FPR。 例如,当使用 GPT2-XL 1.5B 时,RevPRAG 在 RAG 中取得了 97.2%(使用 Contriever)、98.7%(使用 Contriever-ms)、97.9%(使用 DPR-mul)、97.8%(使用 ANCE)的 TPR,以及 1.6%(使用 Contriever)、5.7%(使用 Contriever-ms)、3.5%(使用 DPR-mul)和 4.2%(使用 ANCE)的 FPR。
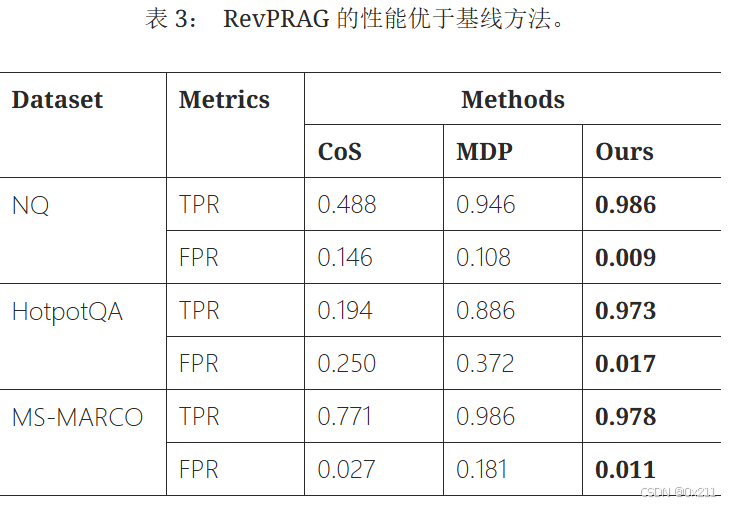
基于推理链分析的后门检测方法 Chain-of-Scrutiny (CoS) 表现出有限的有效性。 我们认为这是因为 CoS 专门用于检测大型语言模型中的后门攻击,它依赖于从触发器到目标输出的捷径。 这与 RAG 不同,在 RAG 中,后门攻击是通过将中毒文本注入知识数据库来执行的。 其次,MDP 达到了良好的 TPR,但也表现出相对较高的 FPR,高达 37.2%。 然而,MDP是一种基于输入的方法,其重点在于检测输入是否被投毒。 相反,我们的方法集中于确定RAG生成的响应是否正确或被投毒,因为我们观察到RAG响应的正确性(或不正确性)在指示投毒攻击方面提供了更大的鲁棒性。
消融
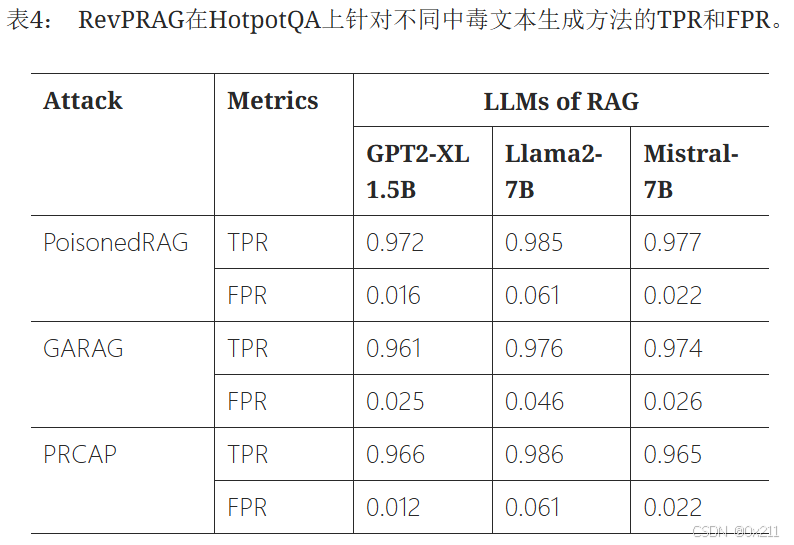
当面对不同策略生成的中毒文本时,RevPRAG始终能够获得较高的TPR和较低的FPR。 例如,对于使用PoisonedRAG生成的中毒文本,RevPRAG在使用GPT2-XL 1.5B时达到97.2%、使用Llama2-7B时达到98.5%、使用Mistral-7B时达到97.7%的TPR。
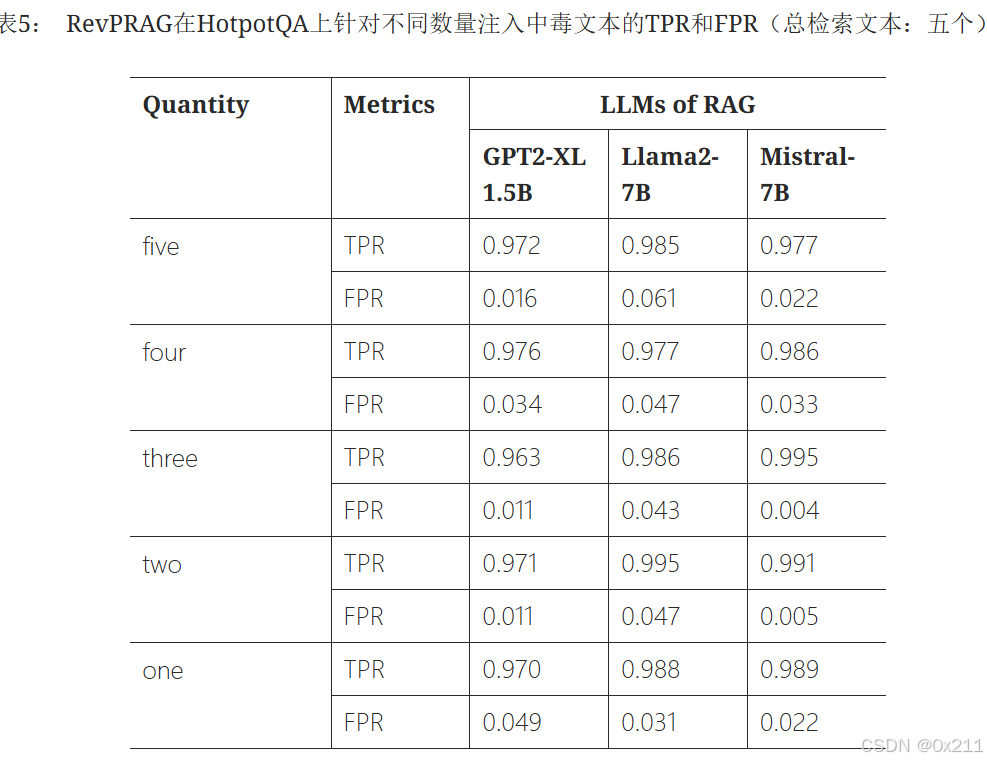
注入的中毒文本越多,RAG处理时检索到它们的可能性就越高。即使注入的中毒文本数量不同,RevPRAG也能始终获得较高的TPR和较低的FPR。
在RevPRAG中,支持数据在模型的学习过程中起着关键作用。 它提供标记信息和特定任务的知识,使模型即使在数据有限的情况下也能进行有效的推理和学习。 我们实验了从50到250不等的各种支持集大小,以检查它们对RevPRAG性能的影响。 此评估是在Llama2-7B上使用不同的数据集进行的。结果表明,改变支持集大小不会显著影响模型的检测性能。
结论与局限性
发现RAG中正确和中毒的响应在大语言模型(LLM)激活方面表现出明显的差异。 基于这一见解,我们开发了RevPRAG,这是一个检测流程,它利用这些激活来识别由恶意文本注入知识库引起的RAG中毒响应。 我们的方法在使用五个不同的大语言模型和四个不同的检索器对三个数据集进行的RAG实验中均展现出强大的性能。 实验结果表明,RevPRAG实现了极高的准确率,真阳性率接近98%,假阳性率接近1%。 消融研究进一步验证了其在检测不同类型和级别中毒攻击下中毒响应的有效性。 总体而言,我们的方法能够准确地区分正确和中毒的响应。
- 这项工作并没有提出针对RAG中毒攻击的特定防御方法。 相反,我们的重点在于及时检测大语言模型 (LLM) 生成的中毒响应,旨在防止此类攻击对用户造成潜在危害。
- 我们的方法需要访问LLM的激活情况,这需要LLM是一个白盒模型。 虽然这可能对用户带来一定的限制,但我们的方法可以被LLM服务提供商广泛采用。 提供商可以实施我们的策略,以确保其服务的可靠性并增强与用户的信任。
- 我们的方法主要关注确定RAG生成的响应是正确的还是中毒的,而没有深入更细致的区分。 我们研究的主要目标是保护用户免受RAG中毒攻击的影响,而对RAG响应的更详细分类将在未来的工作中进行探讨。

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









