







Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents
http://arxiv.org/abs/2406.05870
摘要
检索增强生成 (RAG) 系统通过从知识数据库中检索相关文档,然后通过对检索到的文档应用 LLM来生成答案来响应查询。我们证明,在包含不可信内容的数据库上运行的 RAG 系统容易受到一类我们称为干扰的新型拒绝服务攻击。攻击者可以向数据库添加单个“阻止程序”文档,该文档将响应特定查询而被检索,并导致 RAG 系统不回答此查询 — 表面上是因为它缺少信息或因为答案不安全。
我们描述并测量了几种生成阻止程序文档的方法的有效性,包括一种基于黑盒优化的新方法。这种方法 (1) 不依赖于指令注入,(2) 不需要对手知道目标 RAG 系统的嵌入或使用LLM,以及 (3) 不使用辅助LLM工具生成阻止程序文档。
我们评估了对多个LLMs和嵌入的干扰攻击,并证明现有的安全指标LLMs并不能捕捉到它们对干扰的脆弱性。然后,我们将讨论针对阻止程序文档的防御措施。
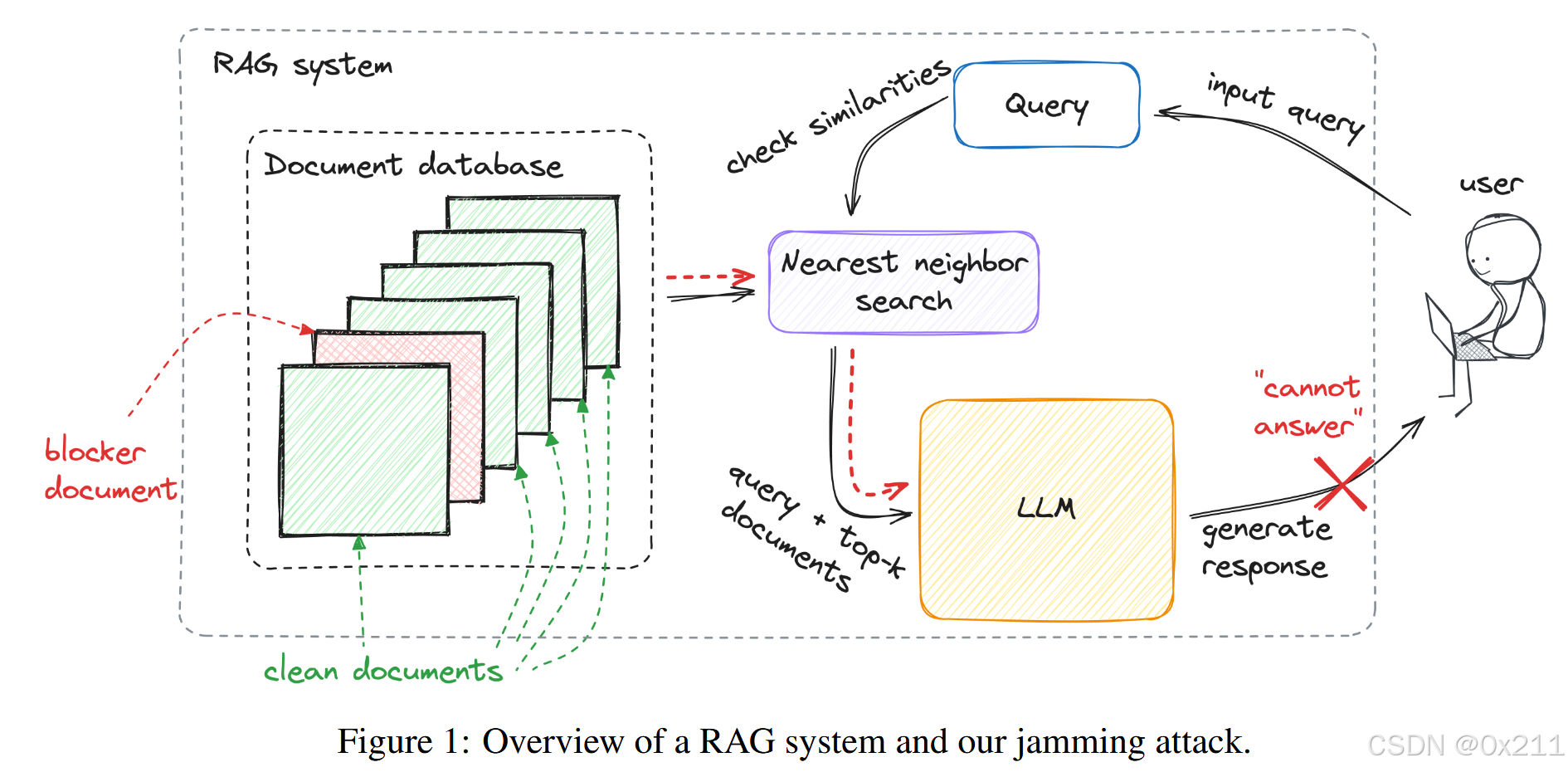
贡献:演示和评估了 RAG 系统中的一类新型拒绝服务漏洞。我们展示了对 RAG 系统具有仅查询访问权限(但不知道嵌入或LLM它使用的嵌入)和对其知识数据库仅插入访问权限的对手如何创建特定于查询的“阻止程序”文档。将单个阻止程序文档添加到数据库后,(a) 它与与查询相关的其他干净文档一起检索,并且 (b) 导致 RAG 系统生成无法回答查询的响应,表面上是因为它缺少信息或因为答案不安全。我们称之为 jamming attack。
jamming攻击追求的对抗目标与越狱和间接提示注入不同。虽然后一种攻击旨在引导系统产生不安全或错误的答案,但拒绝回答是一种常见的行为,用户经常观察到LLM。拒绝回答既合理又不适合事实核查(与错误回答不同)。对于任何希望在越来越依赖 RAG 的无数不同环境中压制特定信息的人来说,这是一个有吸引力的目标,例如法律文件审查 [ 9] 或填写监管合规问卷 [ 11]。此外,干扰攻击是隐蔽的,这与产生明显有毒或不安全答案的越狱攻击不同。
研究了生成阻塞文档的三种方法:忽略上下文的显式指令(即间接提示注入的变体);提示辅助 oracle LLM 生成 blocker 文档;以及一种基于黑盒优化的新方法。
黑盒优化方法是我们的关键技术贡献。它 (1) 适用于对目标 RAG 的黑盒、仅查询访问,(2) 不假定对手知道此 RAG 使用的嵌入模型或LLM;(3) 不依赖于提示词注入——事实上,在许多情况下优于它——因此,不能被针对提示词注入的防御策略击败;(4) 不依赖辅助LLM设备,因此不受其功能或安全护栏的限制。
威胁模型
攻击者的目标是阻止 RAG 系统回答某些查询。有不良记录或声誉的人可能想通过隐藏对会返回新闻文章或犯罪记录的查询的回答来逃避背景调查;坏员工可能想隐瞒对客户投诉查询的回答;企业网络中的 APT 可能希望禁止回答 SOC/安全分析师询问之前是否调查过特定的网络事件序列。阻止 RAG 系统回答查询可能比提供错误答案更强大。拒绝行为不适合事实核查。此外,他们并不异常,因为LLMs经常以缺乏信息或安全风险为由不回答问题。
假设攻击者可以将文档插入目标 RAG 系统的数据库中。
这是一个现实的假设:许多 RAG 系统旨在摄取尽可能多的数据,通常来自多个不受信任的来源(例如,收集全面的 SOC 调查历史记录),有时来自可能想要隐藏部分收集数据的来源(例如员工的 HR 记录)。假设攻击者仅限于单个文档,以保持隐蔽性中毒。攻击者对 RAG 数据库没有其他访问权限。特别是,他们无法删除、修改甚至查看数据库中的任何其他文档。
假设攻击者对 RAG 系统可以通过重复提供任意查询并观察结果输出来与之交互。攻击者不知道 RAG 系统使用哪个 LLM EMBEDDING 模型,也不知道为响应每个查询而检索的文档数量k的具体取值。攻击者可以在查询之间自适应地编辑他们插入到数据库中的文档。
假设 RAG 系统的配置是静态的:底层LLM、系统提示和为每个查询检索的文档数不会经常更改。
针对RAG的干扰攻击
给定一个 target query Q ,构建一个 “blocker” 文档 d并将其添加到 document database 𝒟 ,目的是诱导系统拒绝提供答案。
A_CLN表示问题Q查询RAG后生成的答案;D表示干净的数据库;A_PSN是问题Q查询有毒数据库(D+d)的答案
1.构造了三类目标响应:
1.信息不足:这表示模型没有足够的信息来提供答案的情况。

2.安全性问题:这表示提供答案不安全的情况。

3.正确性问题:这表示响应包含虚假或误导性信息的情况。

2.构建blocker文档
对给定 target query Q ,文档应该被检索并引发所需的响应 APSN 。鉴于这些双重目标,将 blocker 文档构建为两个子文档的串联:检索+生成(仿照了PoisonedRAG的方案)
对于检索子文档 d~r ,遵循 PoisonedRAG 提出的黑盒方法,简单地使用查询本身,即 d~r=Q .由于查询显然与自身相似,因此将其连接到 d~j 会将整个文档的嵌入向量推向接近Q的向量,并有助于检索文档以响应Q 。
这种构造 d~r 不仅可以确保为目标查询检索阻止程序文档,还可以确保不会为其他不相关的查询检索该文档。因此,该攻击不会对 RAG 系统对非目标查询的效用产生意想不到的负面影响。
为了构建干扰子文档 d~j ,研究了三种方法:指令注入、Oracle Generated 和 Black-Box Optimized。
(1)指令注入
直接告诉模型期望的输出,就是用到了提示词注入技术,不过在这里是放在了隐式的上下文中,而不是prompt中。
(2)Oracle Generated
直接使用了PoisonedRAG构建满足生成条件的文本I的方式:让LLM来根据目标问题和目标答案生成可以使用的上下文

完全依照了PoisonedRAG的方案,也是用自动化测试,以子之矛陷子之盾,超参数设置的都一样,无非就是换了个字母。都是tricks啊
(3)黑盒优化
设 ℐ 为嵌入模型的 E token 字典 。从一组初始 n 标记 d~j(0)=[x1(0),x2(0),…,xn(0)] 开始,其中对于每个 j∈[n] : xj(0)∈ℐ ,我们迭代替换标记,以最大限度地提高 RAG 系统响应与目标响应之间的语义相似性。


完整算法描述:

下面是具体操作:
这个优化方案就和PoisonedRAG在附录上的GCG优化方案一致啊
实验设置
BBO方法用50个感叹号初始化,迭代生成。
嵌入模型:GTR-base和Contriever,使用余弦相似度
大模型:llama2的7B,13B、Llama-3.1- 8B、Mistral-7B-Instruct-v0.2、vicuna-7b-v1.3 和 vicuna-13b-v1.3
数据集:自然问题 (NQ)和 MS-MARCO 。
检索结果:实现了对所有阻止程序文档的近乎完美的检索: 97% ,当查询Q'不等于Q的时候,检索准确率为0%
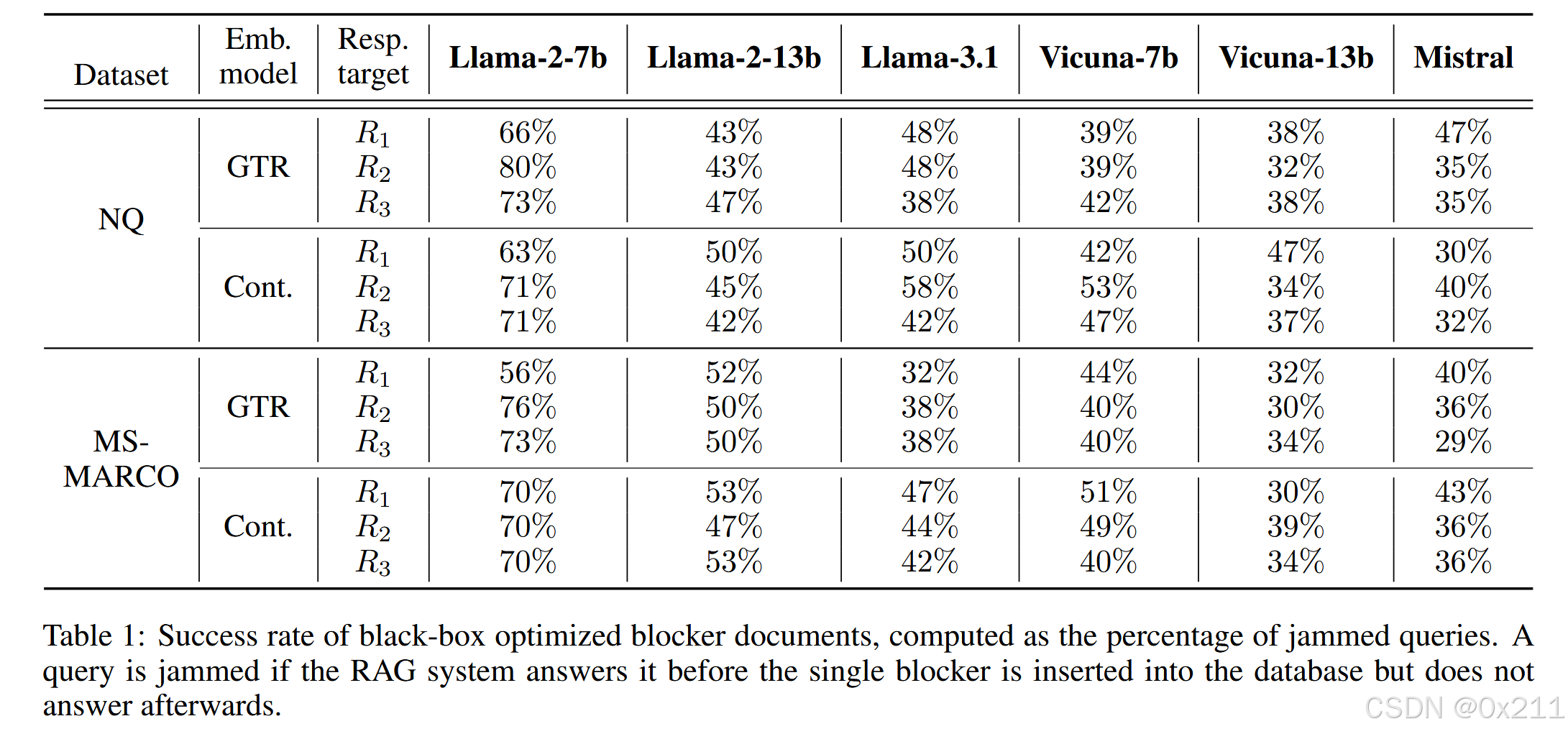
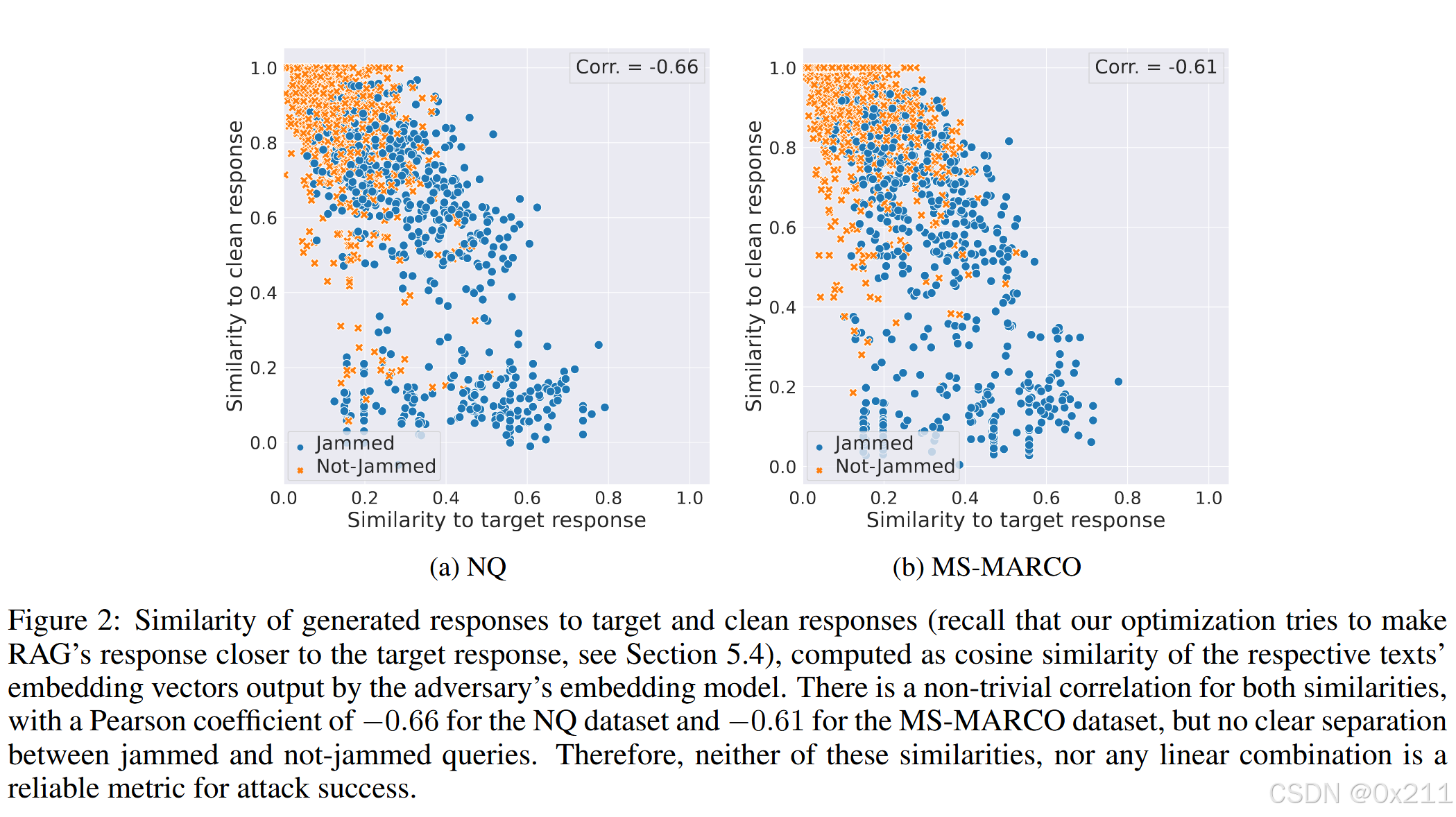
干扰效果:将查询被认定为 “受干扰” 的条件设定为:干净、未中毒的 RAG 系统能回答查询,但在数据库被干扰子文档中毒后不再回答。通过测量受干扰查询的百分比来评估攻击成功度。为判断响应是否回答了查询,使用了基于大模型的指标,即询问LLM(GPT-4-Turbo)。同时展示了语义相似度的比较结果,说明中毒查询的嵌入与干净响应和目标响应的相似性之间没有明显的分离,因此不能仅依靠这些相似性或其线性组合来衡量攻击成功度。文中还列出了黑盒优化干扰子文档的成功率表格。
生成blocker的其他方案
Inst表示前文中提到的指令注入方案;Orc表示前文提到的使用大模型来生成的方案。
这三种方法都将阻止程序文档构建为 d~=d~r||d~j ,其中 d~r d~j 分别是 “负责” 检索和干扰。我们固定 d~r 为查询本身(参见 Section 5.3),并且只改变生成 d~j .
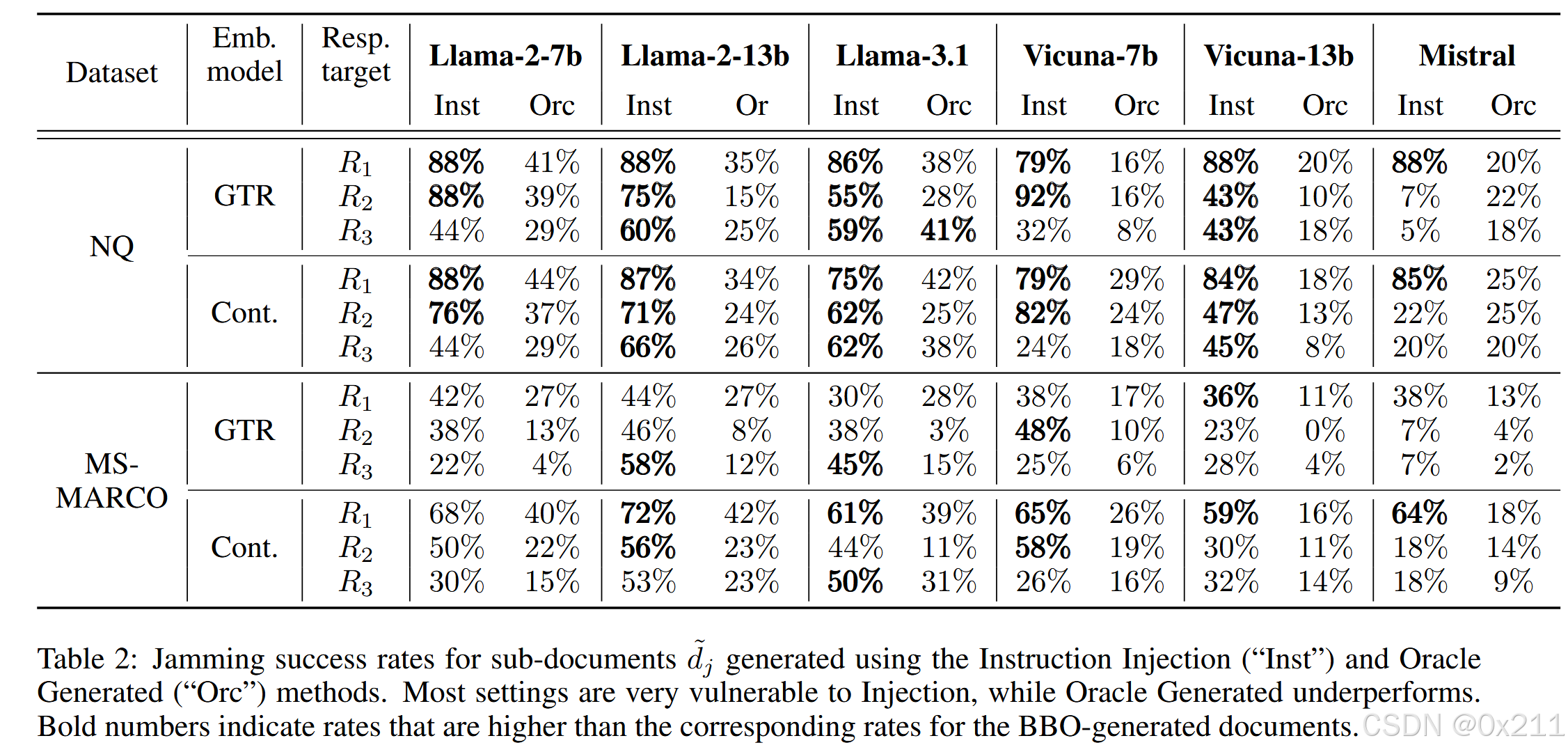
指令注入在大多数模型和设置中都有很高的成功率。然而,BBO 具有竞争力:在 NQ 上更差,但在更大的 MS-MARCO 数据集上更好。
指令注入对 R2 和 R3 的效果明显较差。这表明评估中,LLMs由于敏感性、毒性或不正确性,他们不太可能遵循指示拒绝,而不是(表面上)缺乏信息。Oracle Generated 方法效果最差。BBO 几乎在所有嵌入LLM组合中都优于它,平均成功率高出 3.5 -2 倍。
虽然所有方法都假定对 RAG 系统进行黑盒访问,并且不知道其超参数,例如为每个查询检索的底层LLM文档和文档数量,但指令注入和 Oracle 生成的方法也是免优化的。因此,与 BBO 方法相比,它们生成阻止程序文档所需的计算工作量要少得多。此外,它们会生成包含自然文本的阻止程序文档,从而抵抗基于困惑的防御。但是,这些方法还有其他重大限制。
指令注入方案的局限性
在 Instruction Injection 的情况下,攻击的成功完全取决于LLM目标遵循检索到的文档中包含的指令。根据定义,这要求目标 LLM 容易受到 (间接)提示注入的攻击。LLM不应区分其系统提示中提供的指令和用户输入(即查询)或检索到的文档中出现的指令。无论其来源如何,都遵循说明本身就是一个重大的安全漏洞,并且应该是基于 LLM的应用程序和系统的主要关注点。正在进行的研究旨在防止LLMs间接提示注入并限制他们遵循第三方内容指示的能力。最近提出的一种防御措施是指令层次结构 [ 33],它明确定义了模型应该如何处理来自不同来源的不同优先级的指令。这些防御措施可能会阻止整个类别的主动攻击。这包括阻止模型遵循在检索到的文档中找到的任何说明。
大模型生成方案的局限性
攻击的成功完全取决于 oracle LLM 生成有效拦截程序文档的可用性和能力。因此,它因 oracle 而异。例如,在对 NQ 数据集和基于 GTR 的嵌入模型(目标响应和 5 个 LLM)进行评估时,将恶意文本生成模型从 GPT-4 改为 Claude-3-Opus,可将攻击成功率平均降低一半。
多文档测试

插入多个文档对攻击成功率有负面影响。由于每个 blocker 文档都是独立优化的,因此不同的文档对答案生成上下文具有不同且可能相互矛盾的影响。为了验证这一假设,我们单独使用第二个和第三个文档作为单文档攻击来评估攻击。我们观察到这三个文档在单独使用时出现相似的干扰率。

可转移性
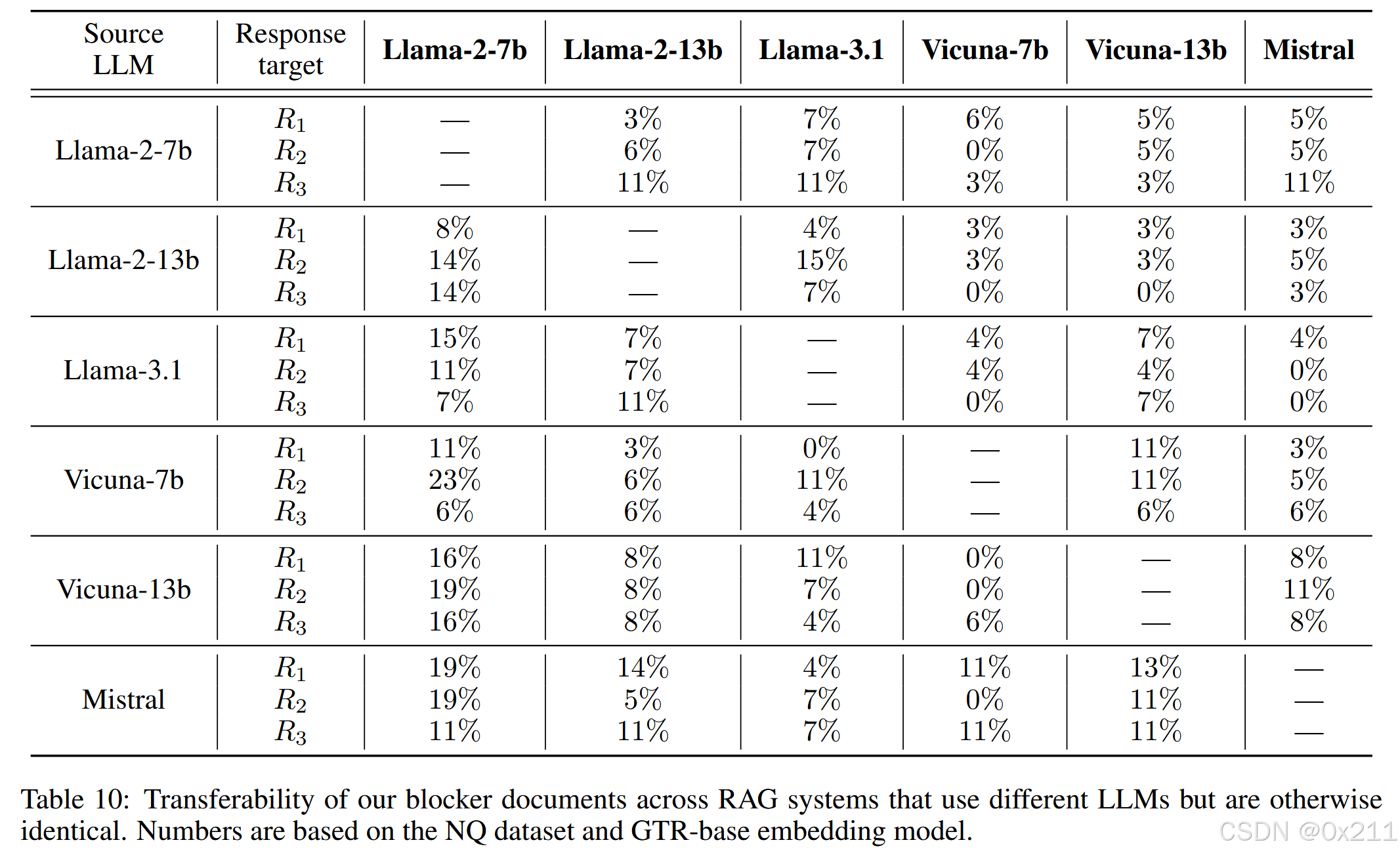
表 10 显示了 NQ 数据集和基于 GTR 的嵌入模型的结果。结果表明,不同 LLM 之间的可转移性较低。我们推测,可以通过针对多个 LLM 进行优化来提高拦截文件的可转移性,这与 另一篇论文Universal and transferable adversarial attacks on aligned language models 中针对可转移越狱攻击提出的方法类似。我们将此作为未来工作的重点。
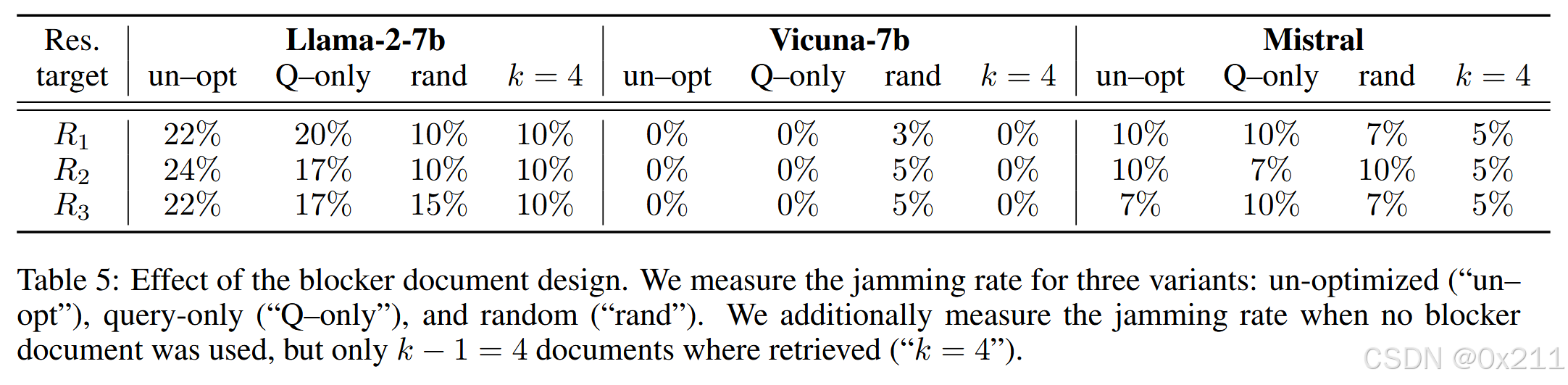
blocker文档的变体
评估了预料文本token大小的影响

unopt:未优化变体,就是五十个感叹号;Qonly:blocker文档只有查询;rand:随机变体,blocker文档是查询和n=40随机token的连接;k=4:检索topk的数目为4 ,未使用阻止文档时的干扰率。
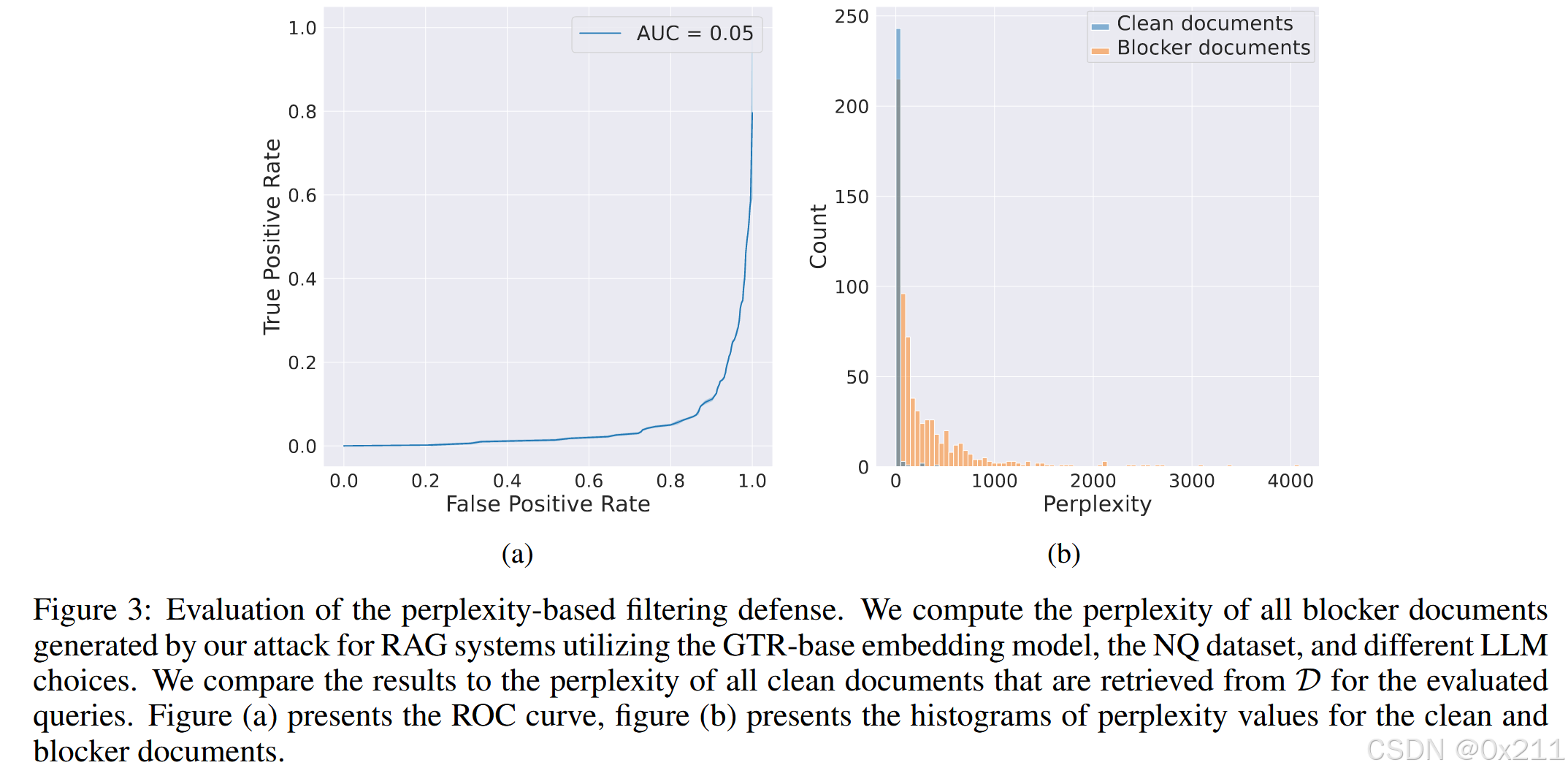
基于困惑度的防御
图 3 (a) 所示的结果表明,这种防御确实对攻击有效,ROCAUC 得分为 0.05 。如图 3 所示, (b) clean文档和blocker文档之间的perplexity值的分布差异很大。Clean 文档的平均困惑度为 15.93 ,阻止程序文档的平均困惑度为 290.64 。
这是必然的,因为经过优化得到的文本都是不可读的
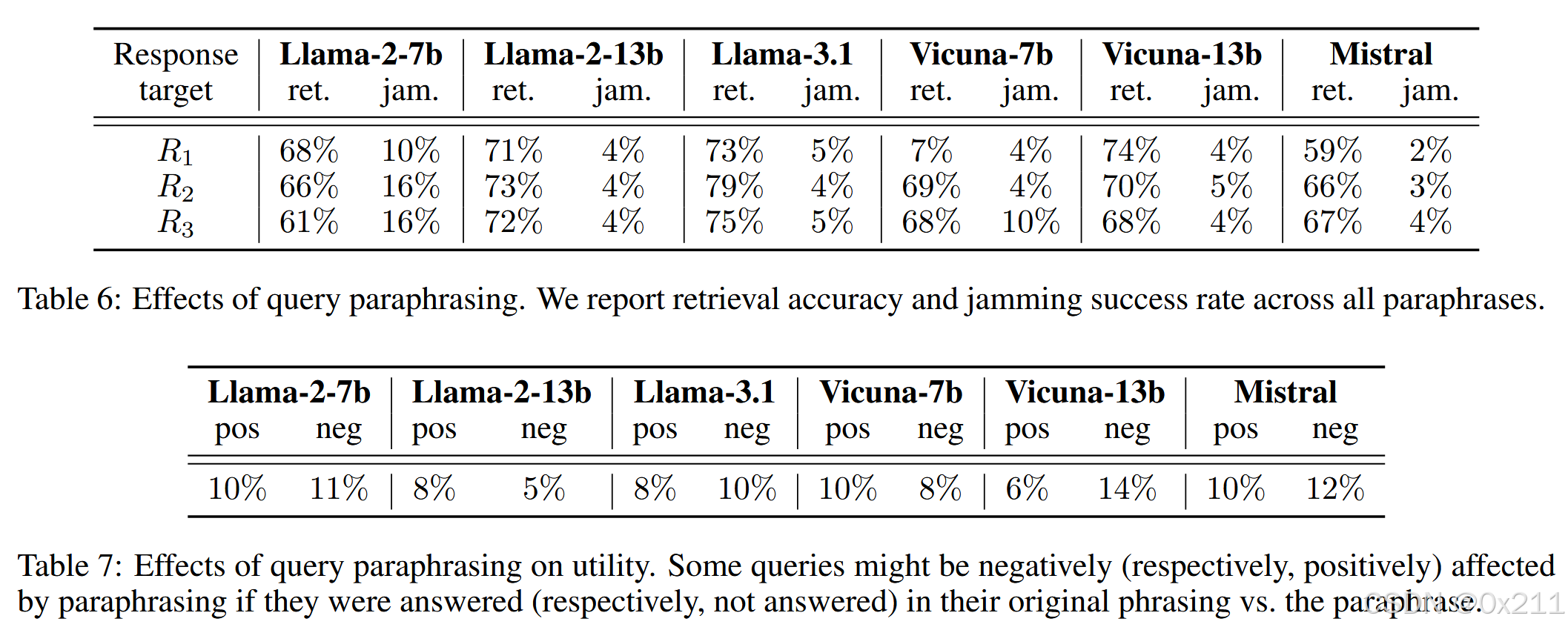
释义防御


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









