







RNN
卷积神经网络CNN能够很好地处理图片,但是在处理语句问题上就会出现问题,这是因为CNN没有记忆性,输入和输出的一一对应,也就是一个输入得到一个输出。不同的输入之间是没有联系的。
场景:
- 一个人说了,我喜欢旅游,其中最喜欢的是云南。以后有机会一定去____。
- 我肚子好____,我想吃饭。
递归神经网络(RNN),是两种人工神经网络的总称:
一种是时间递归神经网络(recurrent neural network);
一种是结构递归神经网络(recursive neural network);
RNN是一类扩展的人工神经网络,它是为了对序列数据进行建模而产生的。
RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。
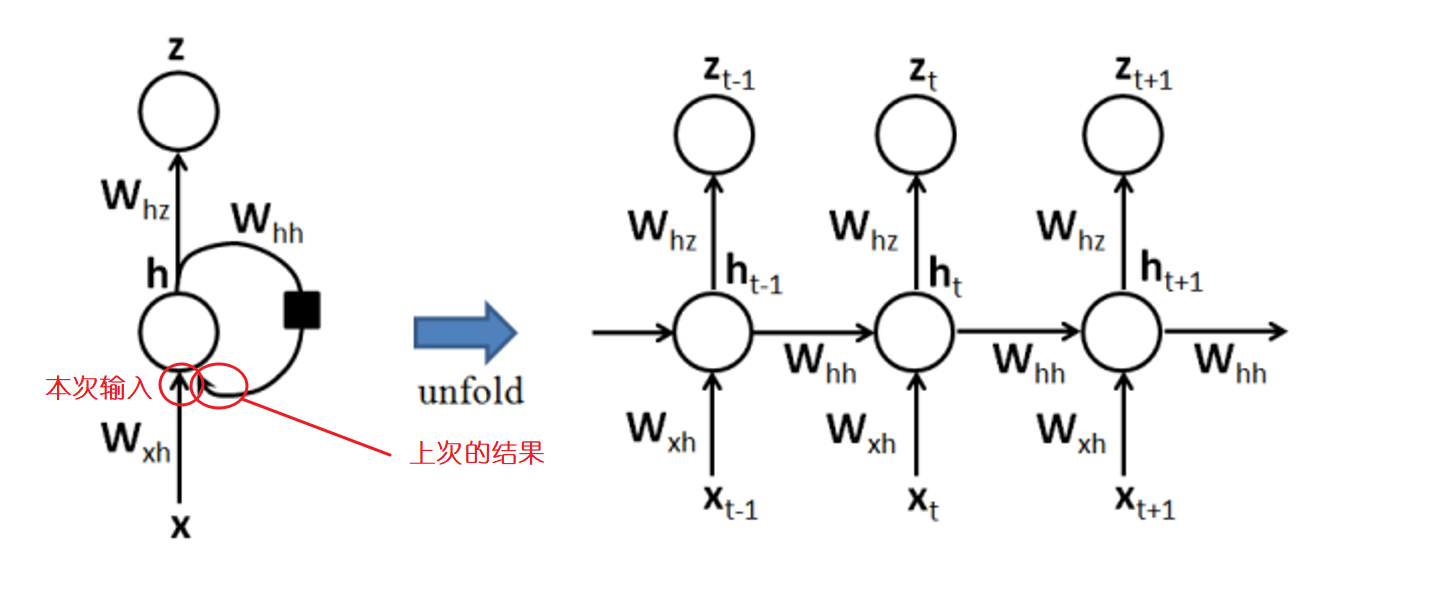
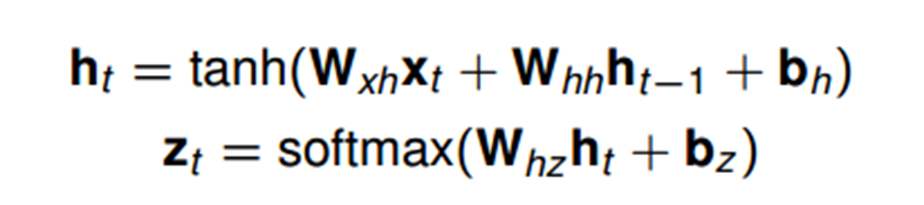
针对对象:序列数据。例如文本,是字母和词汇的序列;语音,是音节的序列;视频,是图像的序列;气象观测数据,股票交易数据等等,也都是序列数据。
核心思想:样本间存在顺序关系,每个样本和它之前的样本存在关联。通过神经网络在时序上的展开,我们能够找到样本之间的序列相关性。
循环神经网络基本单元—Cell,激活函数为tanh
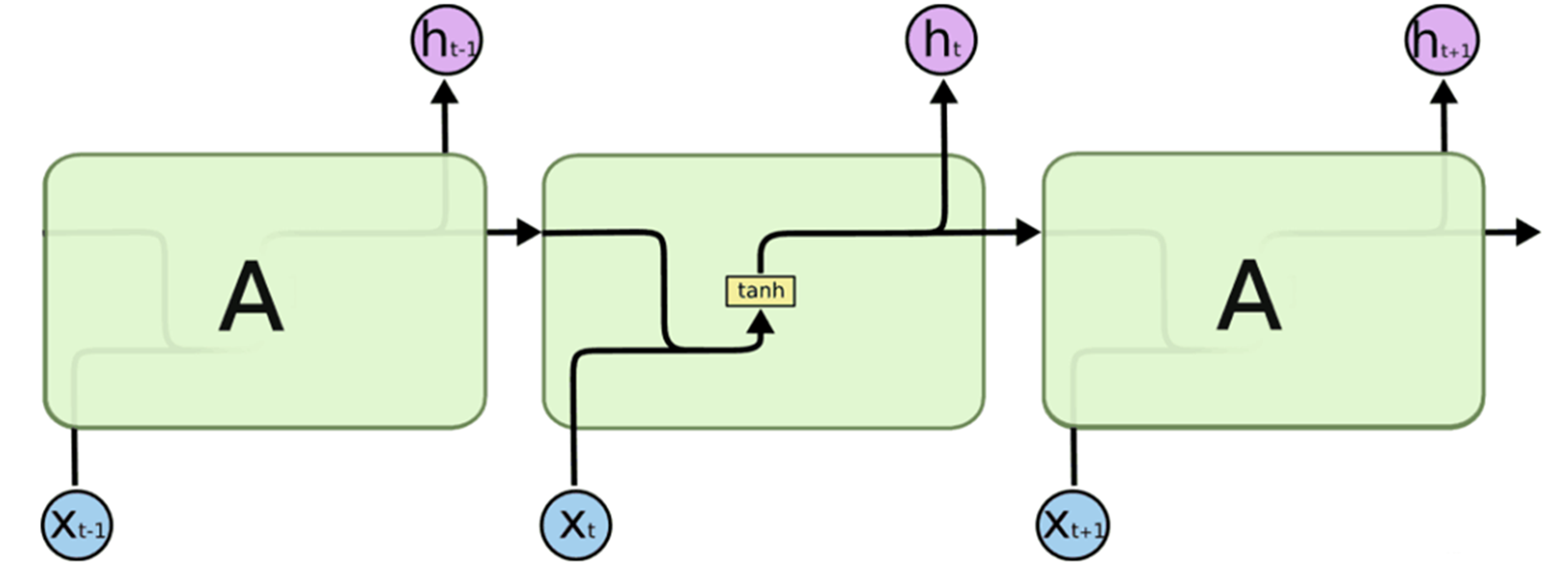
RNN在进行反向传播的时候存在梯度爆炸和梯度消失的问题,这种问题表现在时间轴上。梯度爆炸可以设置梯度阈值直接截取,梯度消失有以下几种方法:
- 选择其他激活函数,如ReLU
- 引入改进网络结构的机制,如LSTM,GRU
现在在自然语言处理上广泛应用的就是LSTM。
梯度消失和梯度爆炸:
深度神经网络训练的时候,采用的反向传播方式,该方式背后其实是链式求导,计算每层梯度的时候会涉及一些连乘操作,因此如果网络过深,那么如果连乘的因子大部分小于1,最后乘积可能趋于0;
另一方面,如果连乘的因子大部分大于1,最后乘积可能趋于无穷。
word2vec
如何能将文本向量化?
我们拿人来比喻。我们把人当做一些属性的集合,如 [身高,体重] ,作为一个向量。但仅凭身高和体重并不能描述一个人的唯一性,所以需要添加更多维度来确保描述一个人的准确性。
对于一个词也是一样,我们用多维向量来描述一个词。
成功向量化后,可以通过计算来判断向量之间的相似性。比如“足球”和“篮球”的相似度应该会很高。
(上下文相似的词,其语义也相似 相近的词投影到高维空间后距离很近)
word2vec就是一款将文本向量化的模型。
通常维度50~300
LSTM
LSTM:Long short-term memory,长短期记忆
RNN存在梯度爆炸和梯度消失问题,这样使得输入的文字过长,后面的将记不住文章开头的内容,是一种“短期记忆”。同时RNN对记忆的内容上没有分辨能力,可能有些需要记住的数据意义并不大。而LSTM在RNN的基础上加上了一个控制装置,可以控制记忆和遗忘。
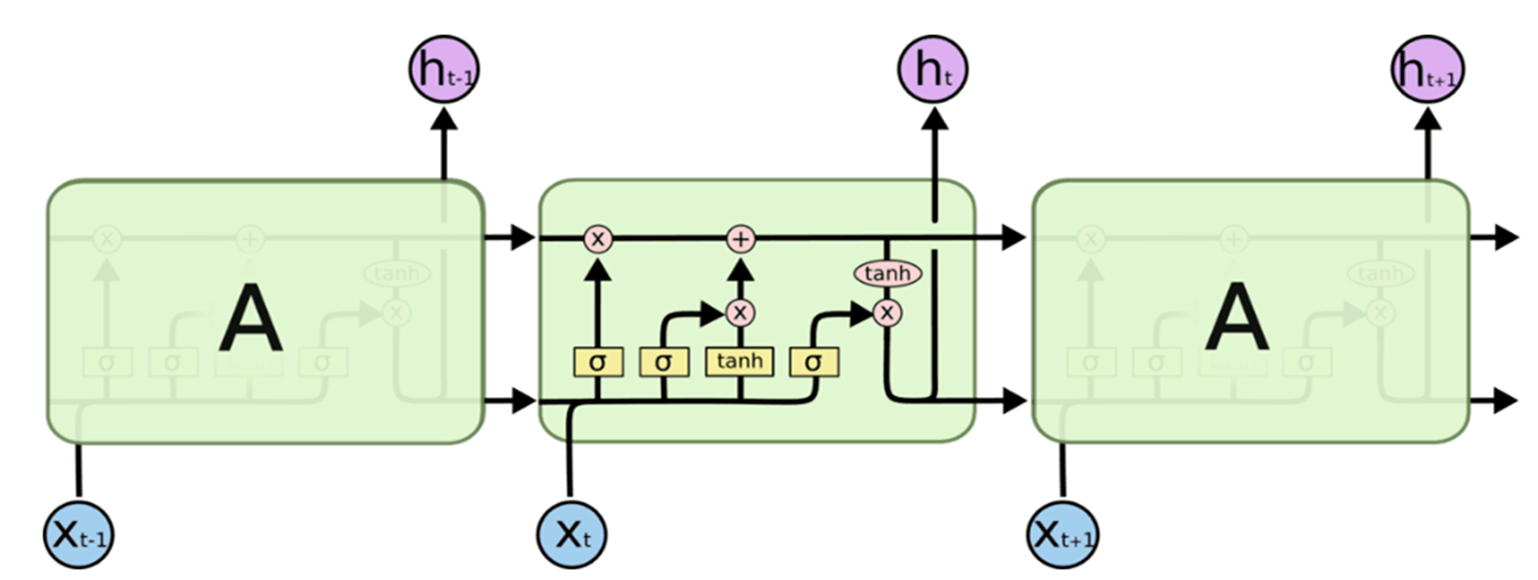
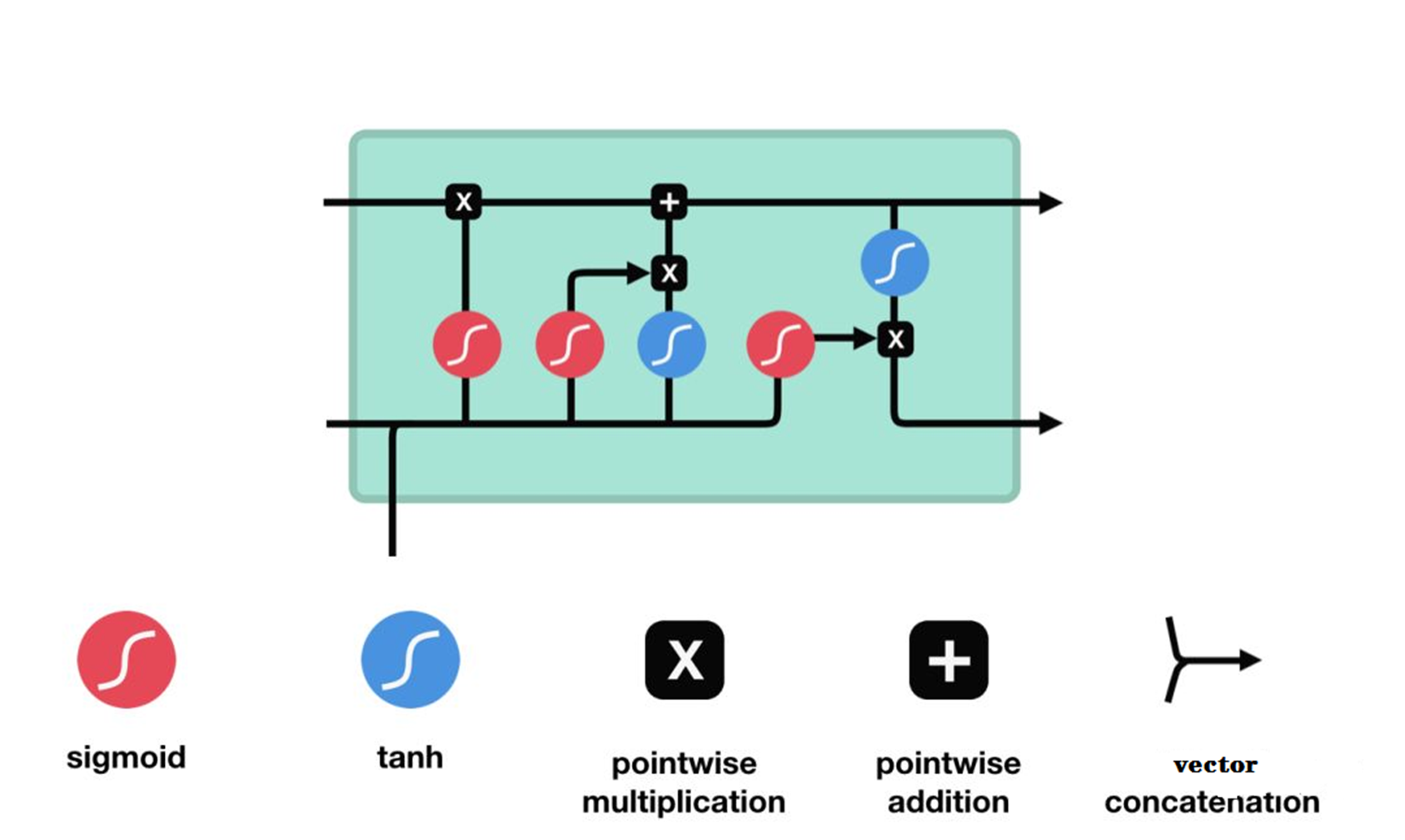
如上图所示,与单一的以Tanh为激活函数的循环神经网络不同的是,LSTM是一种三个“门”结构的特殊网络结构。
遗忘门
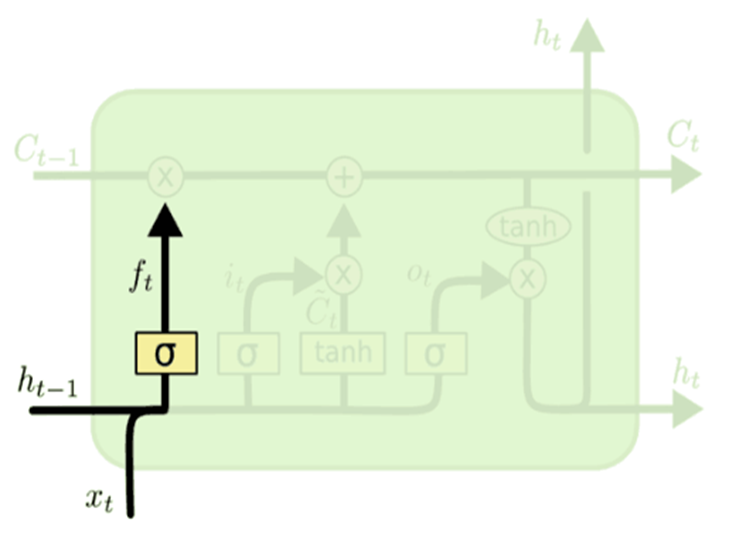
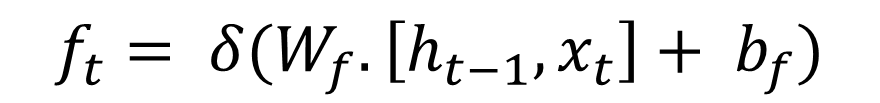
只有符合算法认证的信息才会被保留,不符合的信息则通过遗忘门被遗忘。控制输入X和上一层隐藏层输出h被遗忘的程度大小,输出1代表“完全保留”,输出0代表“完全遗忘”(sigmoid激活函数)
输入门
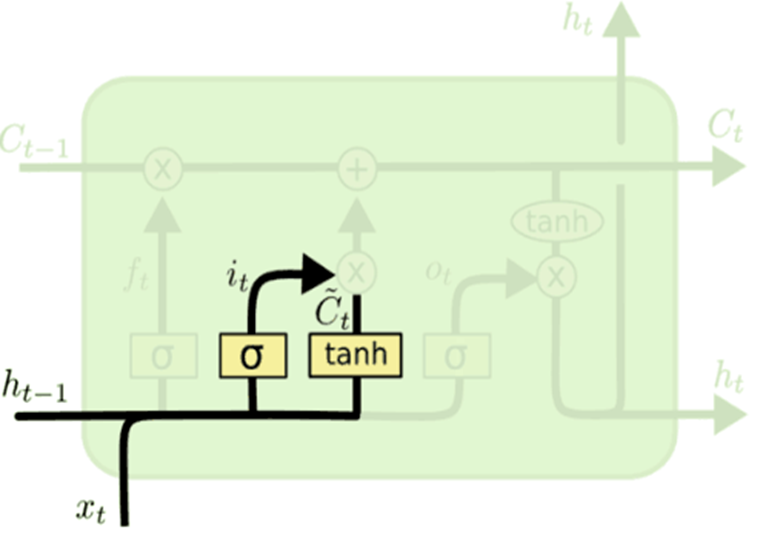
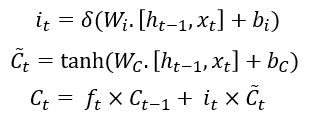
决定将要在单元状态(cell)中存储哪些新的信息
输出门
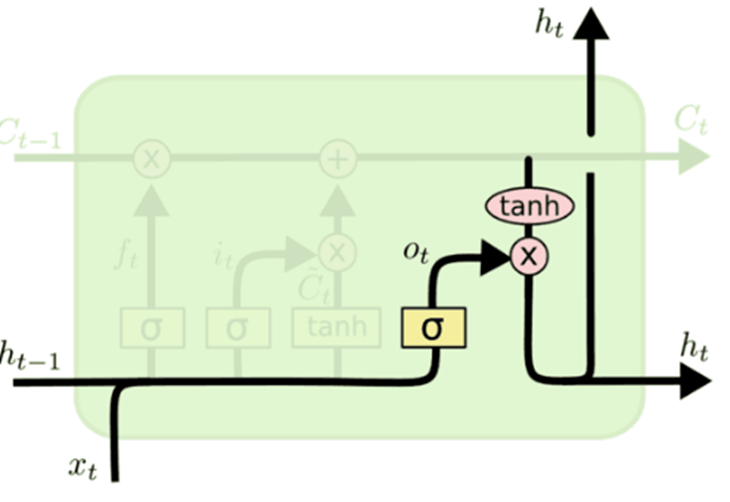
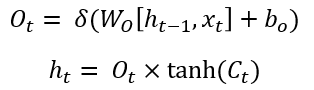
状态向量并不会全部输出,而是在输出门的作用下有选择地输出。

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









