






来源哔哩哔哩技术公众号。
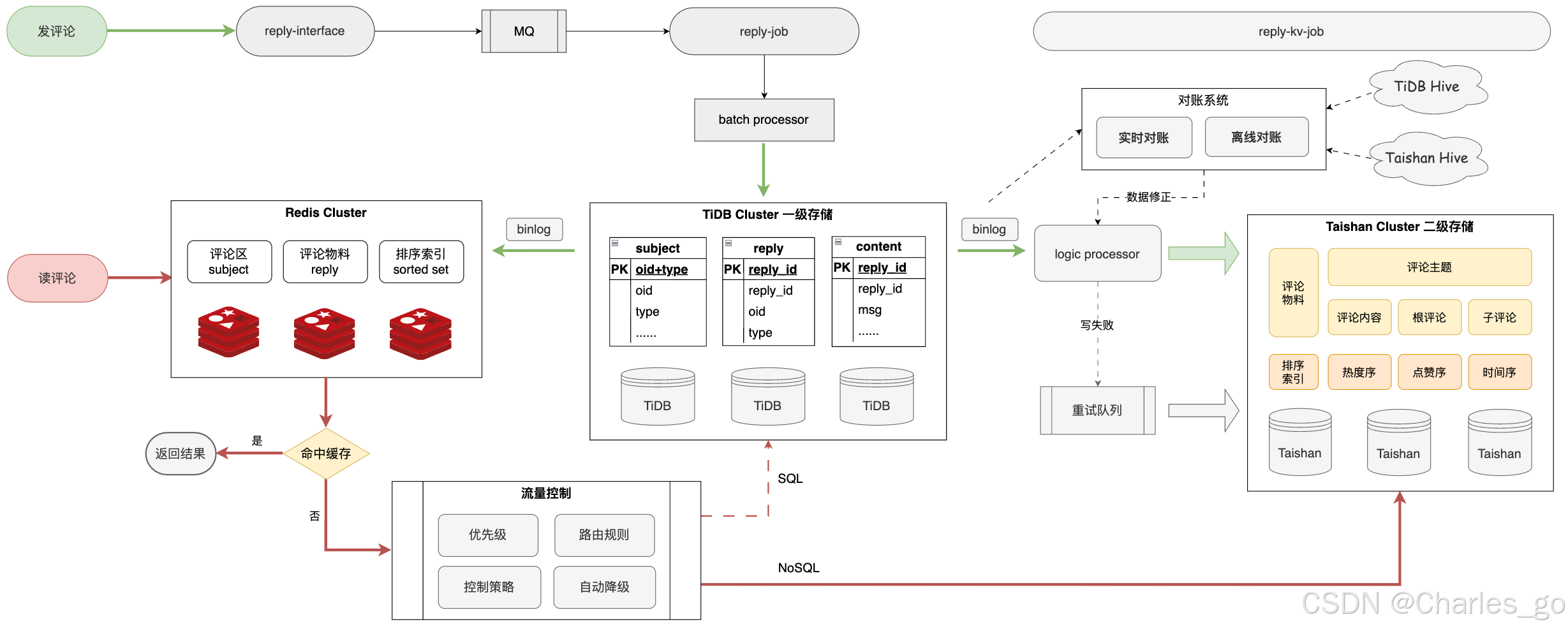
1. 发评论流程
-
发评论:
- 用户通过
reply-interface发送评论。 - 评论数据通过消息队列(MQ)传递到
reply-job。 reply-job处理评论数据,并将其批量处理(batch processor)后写入 TiDB Cluster。
- 用户通过
-
TiDB Cluster:
- 评论数据被存储在 TiDB Cluster 中的多个表中:
subject表:存储评论的主题信息。reply表:存储评论的基本信息。content表:存储评论的具体内容。
- TiDB Cluster 通过 binlog 同步数据到其他存储系统。
- 评论数据被存储在 TiDB Cluster 中的多个表中:
2. 读评论流程
-
读评论:
- 用户请求读取评论。
- 请求首先访问 Redis Cluster 中的缓存数据。
- 如果缓存命中,则直接返回结果。
- 如果缓存未命中,则通过 SQL 查询 TiDB Cluster 或 NoSQL 数据库(如 Taishan Cluster)获取数据,并更新缓存。
-
Redis Cluster:
- 评论区(
subject)、评论物料(reply)和排序索引(sorted set)存储在 Redis Cluster 中。 - Redis 用于快速读取和缓存数据,提高响应速度。
- 评论区(
3. 数据同步与处理
-
TiDB Cluster 一级存储:
- TiDB Cluster 作为一级存储,存储评论的原始数据。
- 通过 binlog 同步数据到二级存储系统。
-
Taishan Cluster 二级存储:
- 二级存储系统(Taishan Cluster)存储评论的详细信息和排序索引。
- 包括评论主题、评论内容、根评论、子评论、热度序、点赞序、时间序等。
-
对账系统:
- 对账系统包括实时对账和离线对账。
- 实时对账和离线对账分别使用 TiDB Hive 和 Taishan Hive 进行数据处理和校验。
4. 重试机制
- 重试队列:
- 如果在处理过程中发生写失败,数据会被放入重试队列。
- 重试队列确保数据最终能够被正确处理和存储。
5. 流量控制
- 流量控制:
- 通过优先级、路由规则、控制策略和自动降级等机制来控制流量。
- 优先级:确保高优先级的请求优先处理。
- 路由规则:根据规则将请求路由到合适的处理节点。
- 控制策略:限制请求的并发数,防止系统过载。
- 自动降级:在系统压力过大时,自动降级部分非关键功能,保证核心功能的正常运行。
6. 数据处理与逻辑处理
- 逻辑处理器:
- 逻辑处理器处理复杂的业务逻辑,如数据校验、排序等。
- 逻辑处理器将处理后的数据写入二级存储系统。
7. 数据修正
- 数据修正:
- 通过对账系统发现的数据不一致问题,可以通过数据修正流程进行修正。
- 数据修正流程确保数据的一致性和准确性。
总结
- 高可用性:通过 Redis Cluster 和 TiDB Cluster 提供高可用性和快速响应。
- 数据一致性:通过 binlog 同步和对账系统确保数据的一致性。
- 可扩展性:通过分层存储和流量控制机制,确保系统的可扩展性和稳定性。
- 容错机制:通过重试队列和数据修正流程,确保数据处理的可靠性。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









