






一、前提
前端:
1.版本号机制
要用前缀定义组件名称,避免冲突;或者加scoped。。

2、sass结构化机制
3、插件机制
在vue中,通过渐渐全局注册,在app对象下compoment方法来进行,如下:

让插件生效,找到main.js,使用app.use(需要注册的插件)
一定在启动的时候就自动加载js中的install方法,再把app实例对象当做以第一个参数传递给install方法
4、组件通讯
自定义属性要在setup里面写definePros
5、项目初始化
cnpm i
npm run serve
npm run build
后端:
go mod tidy
二:项目实战介绍开始
本质:
服务端写接口:路由-->访问某个模块数据表-->使用gorm映射go对应的结构体中-->返回
客户端调接口:根据服务端提供的接口路由-->发起请求-->ginsever接收请求获取参数--执行路由方法--返回路由定义模块的数据--end
为什么做路由组
定义中间件方便拦截
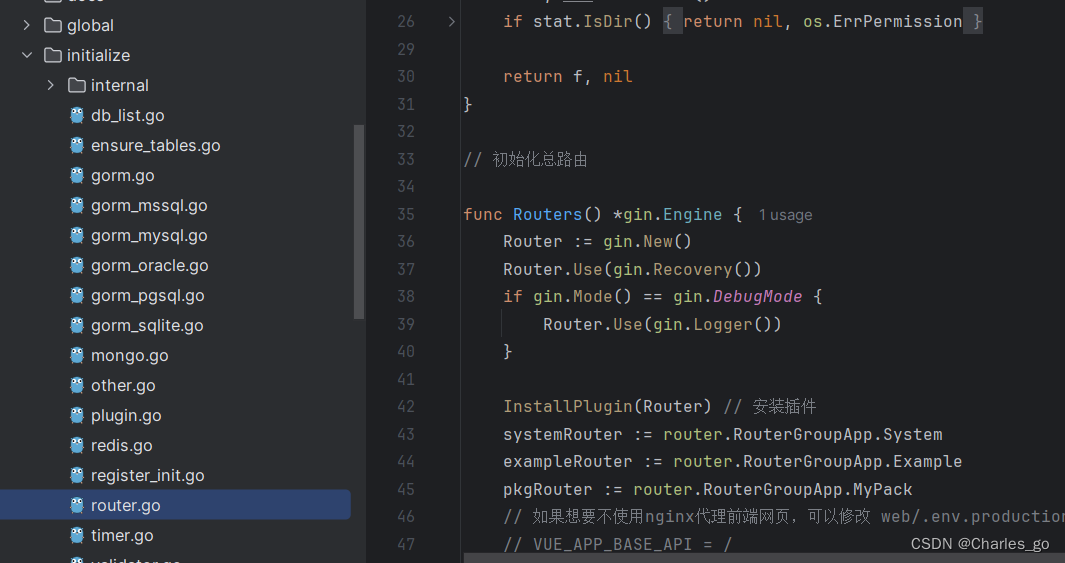
路由如何配置中间件(统一拦截)
命名空间(路由组):例如 userRouterGroup 中间件 user/list,user/get
courseRouterGroup 中间件 course/list,course/get。
有可能会有私有的路由组作了鉴权private,公开的路由组没有鉴权
参数的获取request---Req
单参数,对象参数,路径参数
返回response--VO
统一返回。喜欢用对象参数。
gorm
对数据进行curd和分页相关操作
api
暴露接口
docs
swagger暴露接口的目录,需要执行命令生成doc.go文件
global
这个全局定义
所有初始化只能用在main函数;要么就是用模块的init方法,然后导入到mian所在的包。
initialize
数据库,日志,缓存,等等
都得在main驱动和加载
middleware
中间件,鉴权拦截jwt,casbin权限拦截。防止泄露。
resource
代码自动构建
model
数据库表映射
router
提供对外接口
service
提供curd给api操作
source
数据初始化
utils
可以在这里面收集一些
三、GVA开发文章模块
流程:
建表,model,service,router,注册router,swagger生成路由接口,前端开始调用接口,开始编写对应菜单,定义模块对应spa页面和组件,完成curd操作 。
自动创建表automigrate,只会怎加列,不会更改列,不会更改类型,不会删列。
建表规则:
使用InnoDB
合理命名,数据类型合理长度,不要有空列,要有默认值和注释
gorm官方文档:模型定义 | GORM - The fantastic ORM library for Golang, aims to be developer friendly.
增删改查直接看文档。我查询的时候更喜欢用原生sql语句。
对于列的精度问题,money decimal.Decimal ·gorm:"type:decimal(10,2);"·
可以空字符串,但是不要空列。为后续的索引不要失效,索引可能命中不到。
id,parent_id 分类;sorted字段,分类排序,为什么不用创建时间,因为创建时间是固定的,不能改时间。
多对多关系,要使用中间表,不用的话会造成冗余。


服务:
如果在方法前面加了限定

那么只能通过结构体XkBssService的实例调用它,如果不加则用包名调用它。
实例用小写
api调用:
新手期来说,对数据先不做校验,不过后期为了安全性,一定要对数据进行校验。
断点技巧:
如果要用断点,必须用debug模式启动,不能用小三角。在启动阶段不用打断点,怕阻断了启动。在左下角查看 点击 view Breakpoints,清空所有断点。
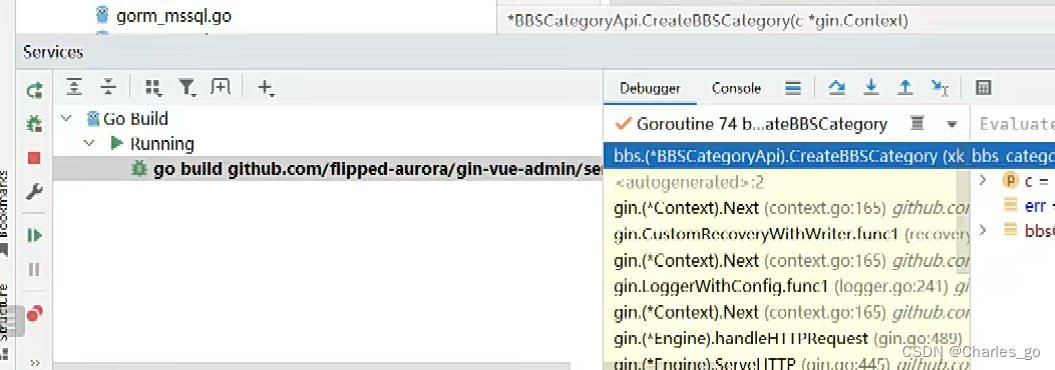
点折线往下step over 是下一步,点往下的是下一个断点。
后端返回的数据需要倒腾:
只返回需要的数据,不要把数据全部返回。
分页查询:
前端:写好api,然后设置请求分页参数,数据加载,生命周期初始化数据加载。
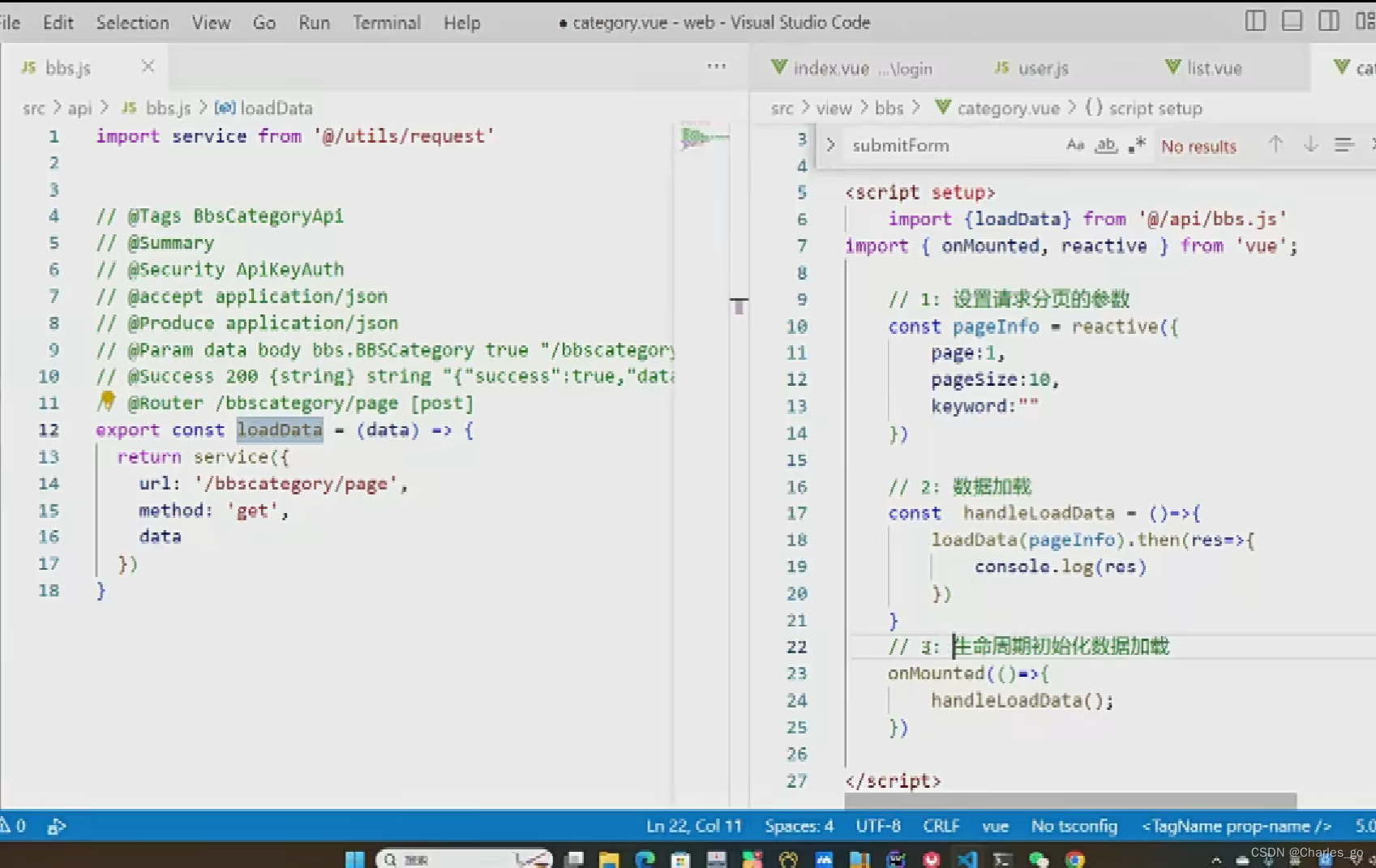
scope代表整行的数据对象,scope.row 数据都打印出来。
table组件
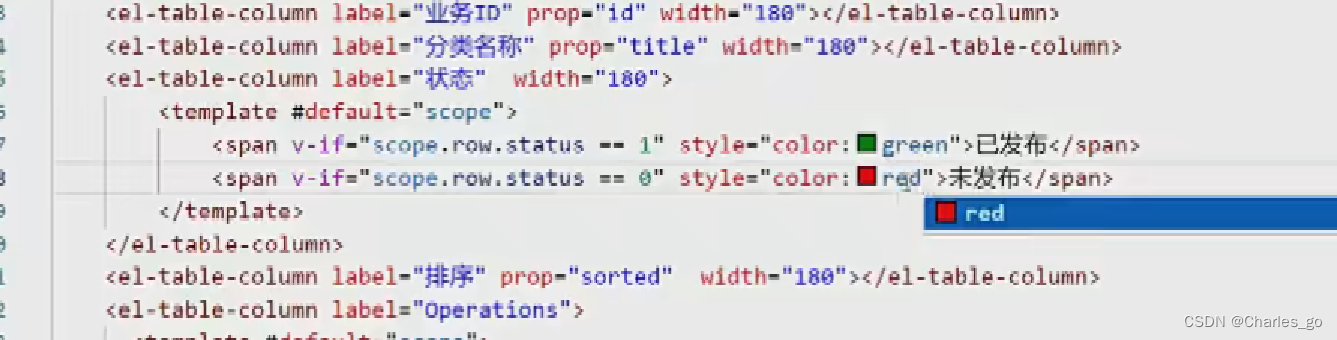
可以把固定宽度去掉,那么就是均分。
分页组件
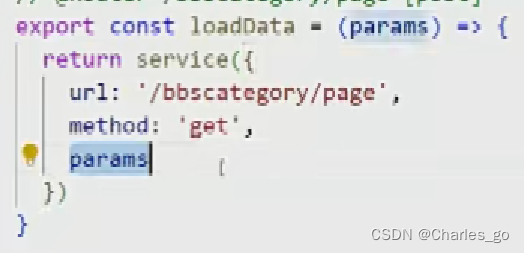
get请求,params传参,后端shouldbindquery
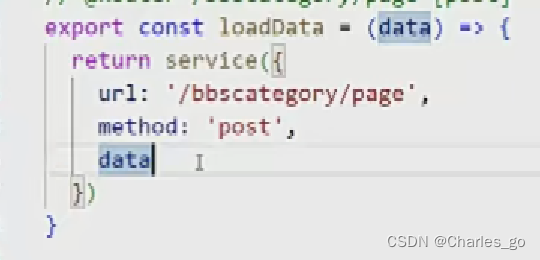
post,data,后端shouldbindjson
不要修改form标签,gva都用了大写的ID作为参数。不能改gva_model
vue中调用api
异步:async+await+try+cach,await 阻断,没有就直接往 下了。

关于这个参数注入的问题,c.shouldbindquery和c.shouldbindjson
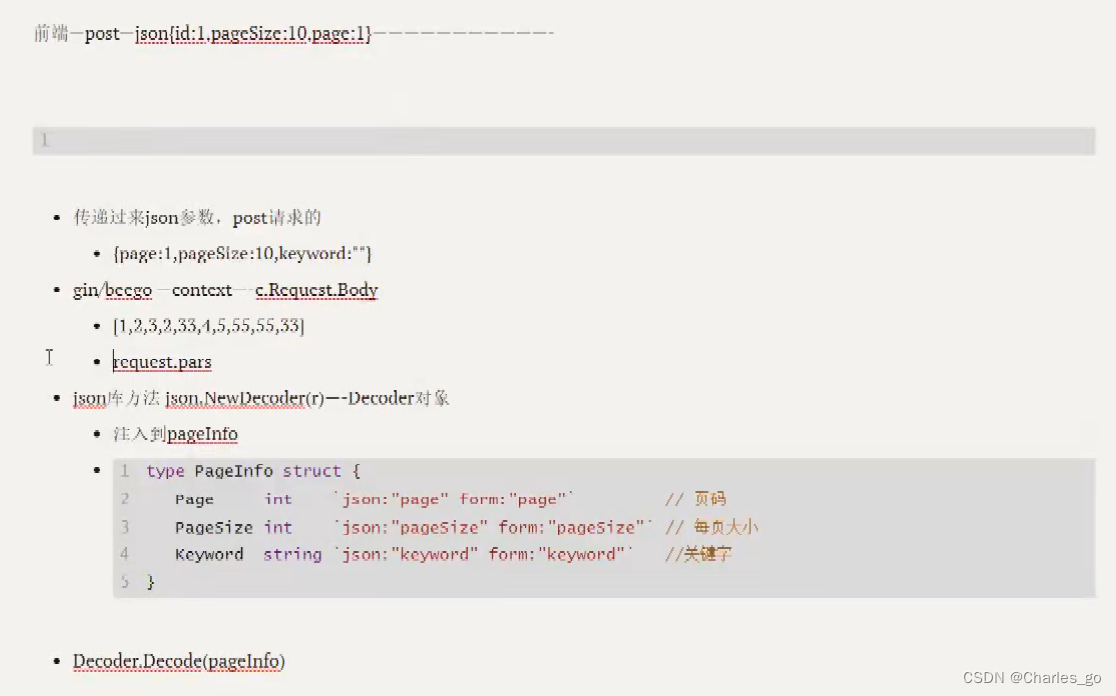
编码,解码,反射。一定要对于好前端传过来的字段名和go中结构体对应的json标签。不然拿不到。
post+json
get写参数要parms

这两个sql语句是不一样的, 第一个是先把id和title找出来的结果,再去找or。而第二句是先把括号后面的结果查出来,然后id=1去过滤。
索引命中?索引不能断层。解决方法:不要建复合索引,如果非要建的话,直接建两个单独的索引。
分类菜单的处理
二级或者多级。递归+tree,表格tree。
表该怎么设计:

确认未来是否能使用多表,不确认的话建议是单表。
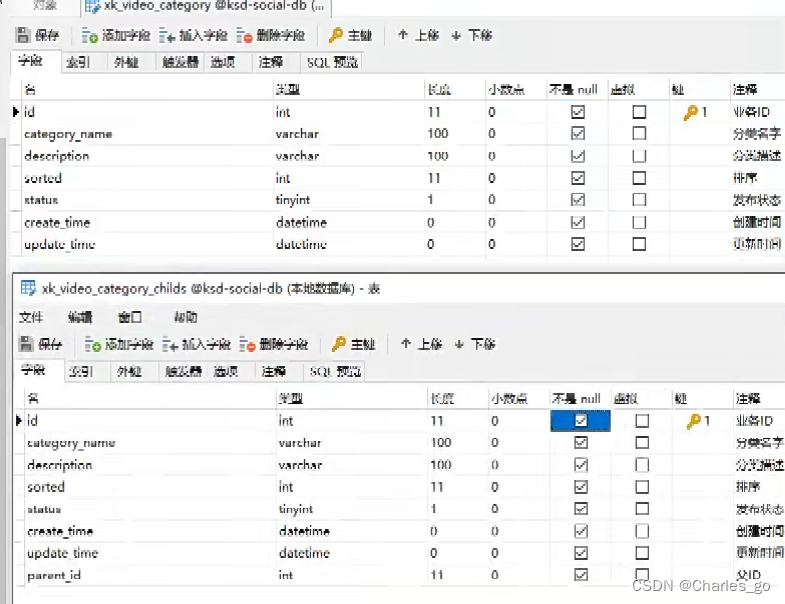
设计父表,子表复制父表(字段)外加一个parent_id,这样两个表就可以连起来。
三级结构也可以这样子,但是如果多级呢?我觉得有点繁琐。所以可以把表合成在一个表(主键和外键放在一张表)。合在一张表,在数据量不大的时候可以。但在数据量大的时候,还是得用两张表。
例子:评论与回复(本身都是评论)先加载主评论,然后异步点击(查看更多)加载回复。sql:between and 的速度很快。
怎么把子数据放在每个父元素的下面
查出一级(数组)
那个childrens就是子数据
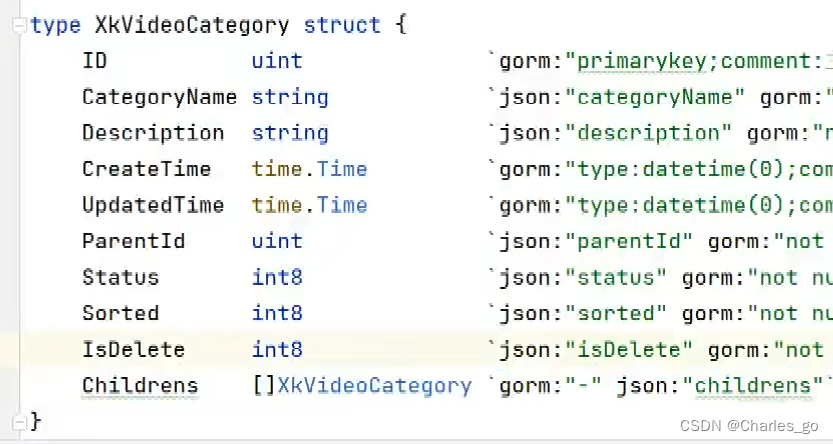
gorm:“-” 说明这个字段不参与数据库处理,无读写。

笑死,看教学视频,post写出了get。和我一样找了半天。
element 数据树形菜单结构。
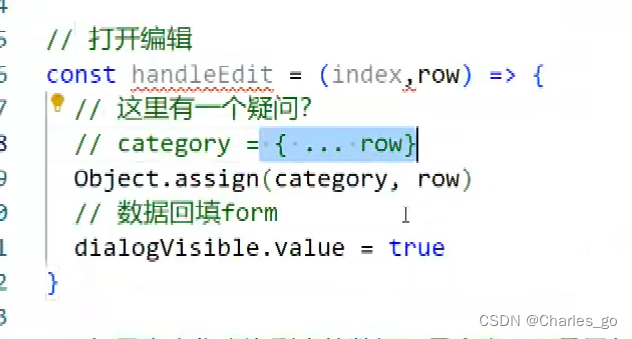
如果打开编辑,输入的时候(还没有点确定)也把展示的内容改了,那要用对象object可以解决这个问题。把row的数据拷贝一份给category,这样两个对象实例,编辑就不会应row的响应式。
有个问题分页查询的时候,如果是查询1000个组,每个组又有十条,那么就是要查询10000次;这样不合理,解决办法可以查一次把10000条数据查出来,然后再分类。
MYSQL优化:
创建索引,他这个索引名字有吗要加_idx,方便识别。
在你查询语句前加上一句explain 可以看到分析
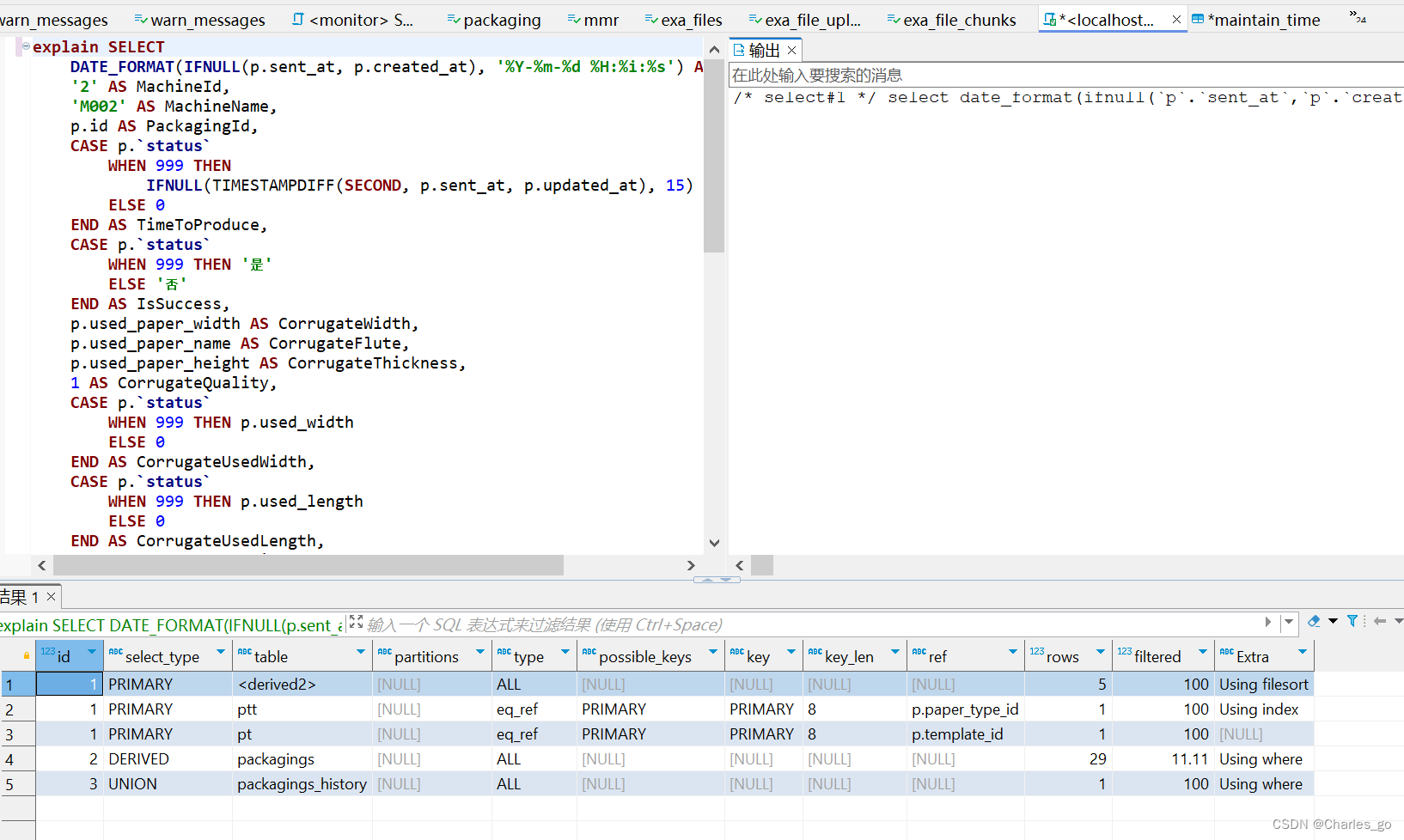
Extra 列中的信息通常包含性能提示,例如 Using filesort 表示需要进行额外的排序。
Using filesort表示MySQL需要额外的排序操作,这通常不是最佳性能。Using index表示查询直接使用索引来获取数据,这通常比全表扫描更快。possible_keys列显示了MySQL可能用于查找的索引。key列显示了MySQL实际选择的索引。key_len显示了被选择的索引的长度。
以后用go连接任何东西,都是tcp/ip。三个握手。优化使用:连接池。如果不用连接池,每次连接都得创建connect 消耗大;用了连接池,相当于创建好了connect对象,你去拿,用完就放回去。不用重复创建。
查出来了如何用代码维持住关系
我们已经把所有的数据查了出来,一般都是后端将数据处理好,发给前端展示。
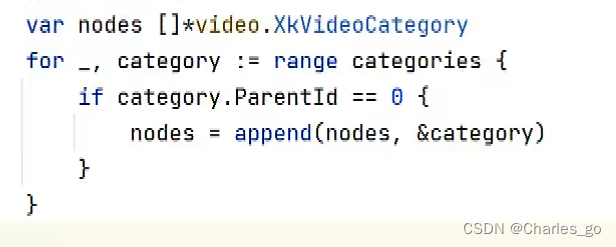
先找出parent_id=0的找出来(找出父类):遍历,然后用apeend添加进容器里。
第一个图是错的,一直传递第一个等于0的值。因为append是拷贝,所以不用&category,用category。
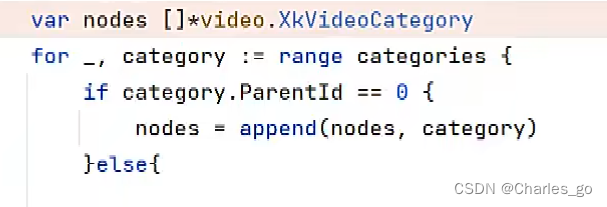
开始遍历父类
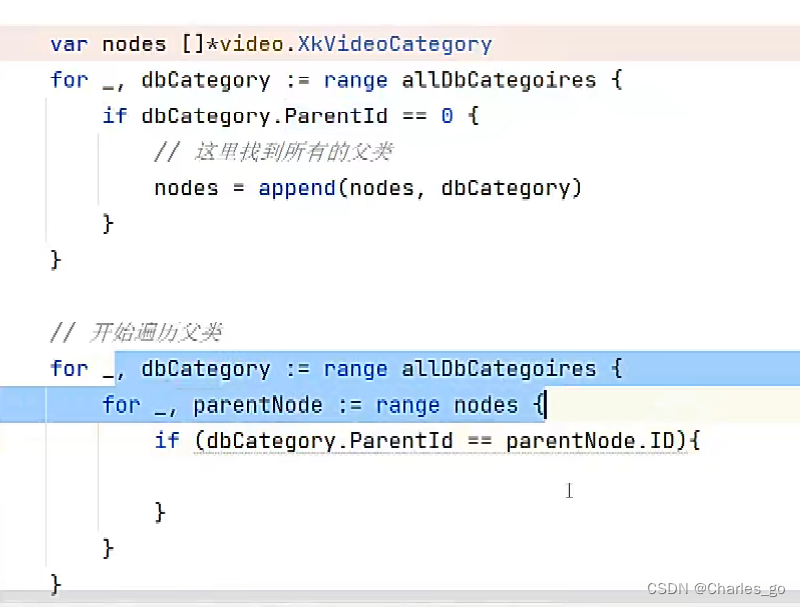
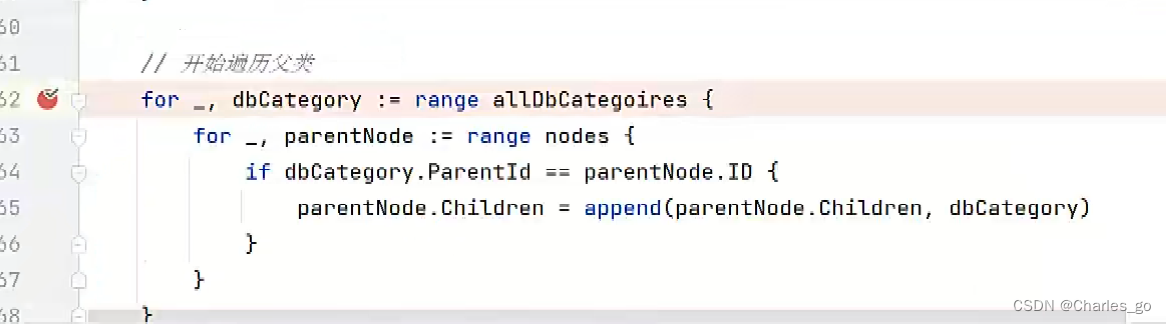
先两级完成功能,才考虑递归。
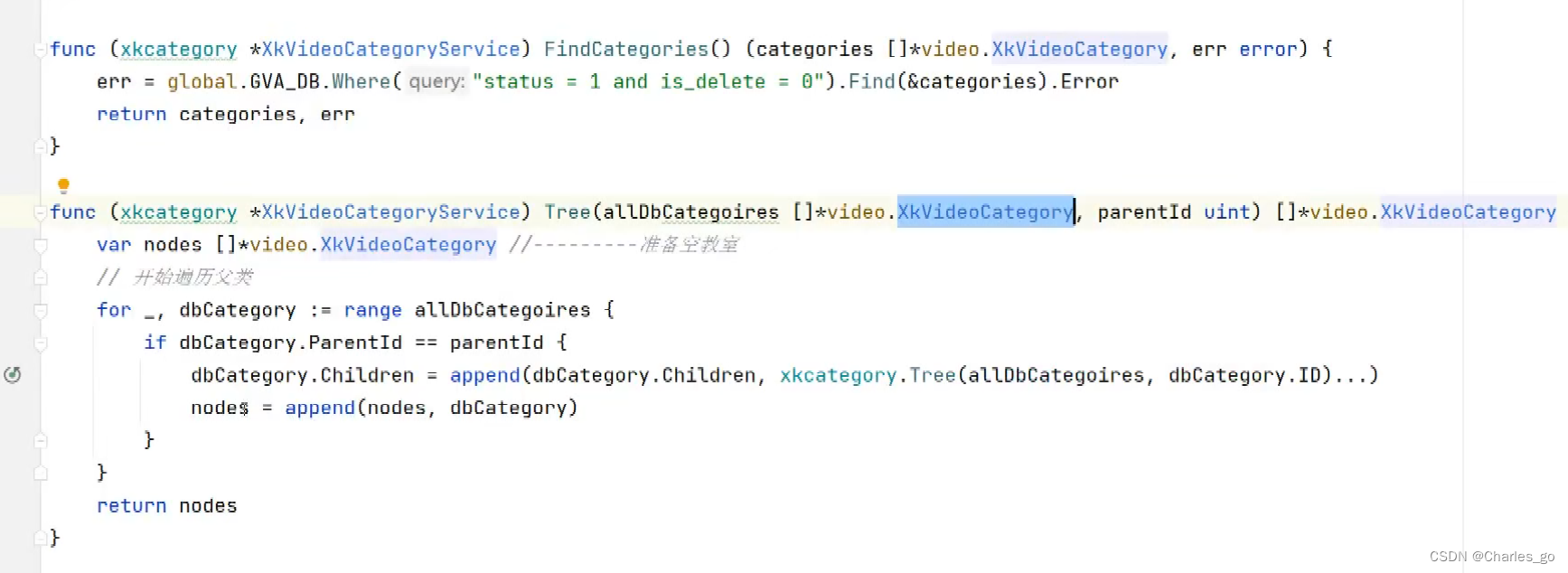
这个是多级版本。改的话把切片换成你需要的。 递归,自调tree。优化:递归比写死的二级查询好,还想优化丢到缓存。先写到数据库再到缓存失败则回滚。如果问几十万条怎么办?你可以访问他子分类和主分类的数据链是什么样子的?给主分类建索引查完主,再查子吧。用异步的方式,点的时候再加载出来子分类。加个分页。
这样写才对要有三个点
newNodes:=[]string{"1","2","3"}
nodes=append(nodes,newNodes...)
没有三个点是错的
newNodes:=[]string{"1","2","3"}
nodes=append(nodes,newNodes)element组件的表格树支持无限递归。
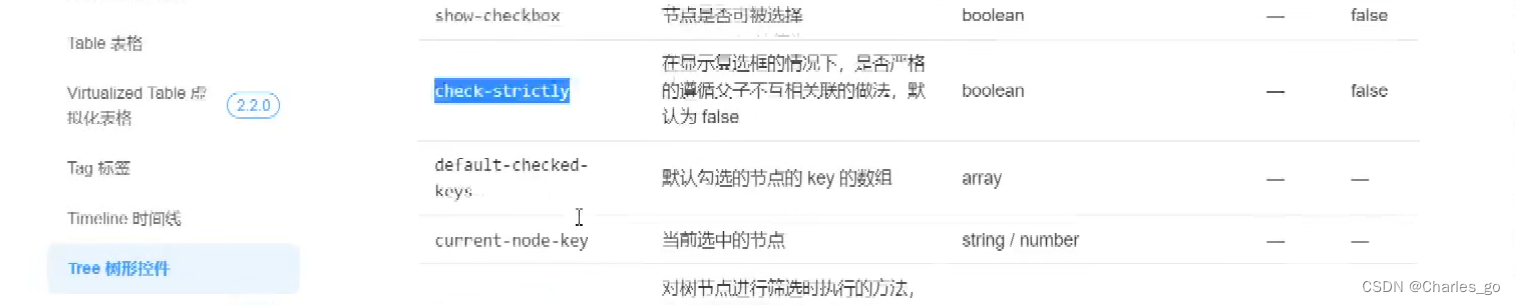
选哪个是哪个。
如何批量选中,加一个checkids,
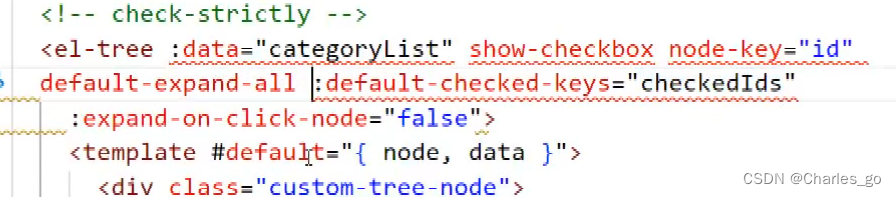

categoryTreeRef=ref() 响应式。然后就可以点它的属性,value。

把所有的节点都选中。
文本编辑器
下载
wangEditor5文档
https://www.wangeditor.com/v4/ https://www.wangeditor.com/v4/
https://www.wangeditor.com/v4/
两个都要安装
v4版本。
打开这个编辑器,有时候出不来这个编辑器,可以用延时重新加载一次,但不合理。打开组件的时候是需要时间的。合理:要用到nextTick()监听组件是否加载完毕。

状态
前端:switch
写一个upadata。传一个id和status,后面根据id来更新。用save,如果里面有id则是更新,没有id的话就是保存。使用精准覆盖。写一个resp结构对应数据库的表,直接覆盖
文件上传
本地:
临时目录的作用就是为了:缓冲,保证上传的文件信息一定在成功且有效的才会复制到真是的目录中。避免用户上传失败或者突然之间断开等问题。
前端控制:file文件框中的name=“file”非常的重要。一般都写:file 但是如果未来有一天又些控件更改了你要知道怎么去处理==。不能随便改这个file,前端改后端也要改。
参考代码:https://gin-gonic.com/zh-cn/docs/examples/upload-file/single-file/
分布式:oss。
购买阿里云oss。可以建bucker,但是访问不到文件显示因为没有购买流量包。购买本地冗余存储,和下行流量(预览作用)
对象存储 go的sdk。连接,拿到client对象。

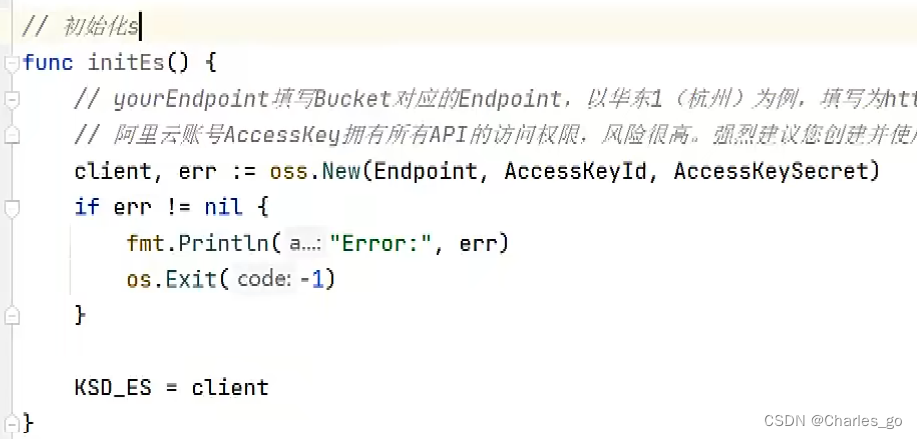
I要大写。InitEs
如果运行给阻断了,查看是否被杀毒软件阻断了。
其他的看官方文档就好。go
定义文件路径
文件流读取。

先open读到文件内容,然后丢到Putobject流化。
删除则从桶的路径开始删掉。
bucketname这级目录后面不要加斜线
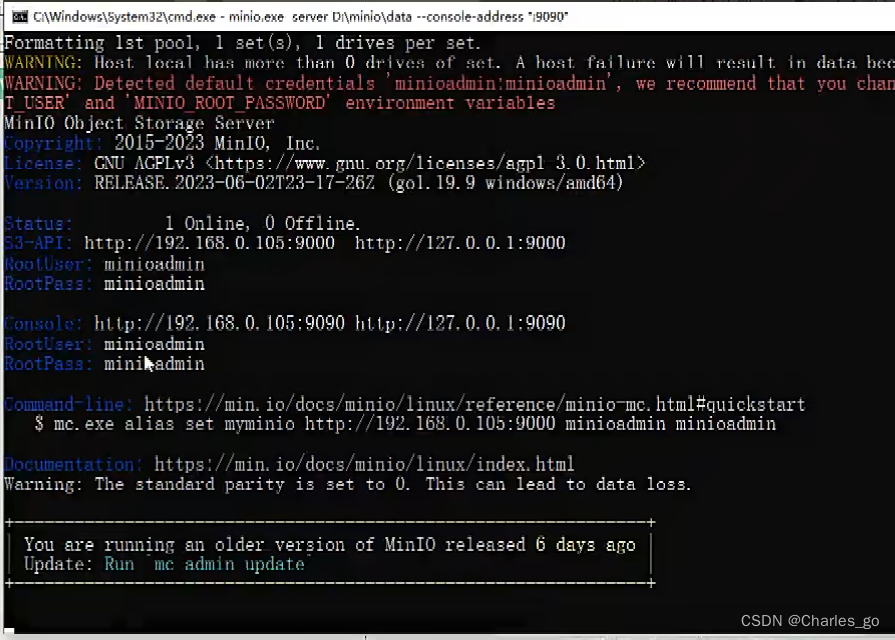
自建minio
查看文档
一些争议:
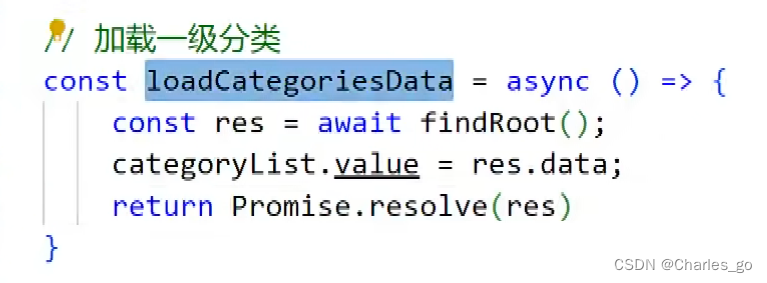
Promise.resolve() 被用于返回一个已解决的 Promise 对象。然而,在这个特定的代码片段中,使用 Promise.resolve() 是多余的,因为 async 函数本身返回的就是一个 Promise 对象。当 async 函数执行完毕,它的返回值将自动被包装在一个 Promise 中。
const loadCategoriesData = async () => {
const res = await findRoot();
categoryList = res.data;
return res;
// 直接返回,无需 Promise.resolve()
}关于日期时间问题
遇到创建和更新时间维护问题,一般是数据维护,另一种是gorm框架维护。最笨的是代码维护。
1.代码维护
保存的时候设置保存时间createTime
更新的时候设置更新时间updateTime
在creat和updatae里加一个time.now。经常会忘记时间的跟新。
在数据库查询的时候,排序会影响性能,应该在业务层排序
2.数据库方案
有个类型是timestamp
前端在做更新或者添加的时候,不要传时间。
3.用Gorm框架
约定使用CreateAt、UpadteAt。gorm在创建的时候会自动填充时间。
关于gorm中删除问题
逻辑删除,软删除。
1.什么样的表不用软删除:中间表、评论、不重要的表
2.用软删除:用户表订单表,基础表。设置delete_time为当前时间。
可以查询被软删除的数据,db.unscoped.
状态方案
0和1,我觉得很low。
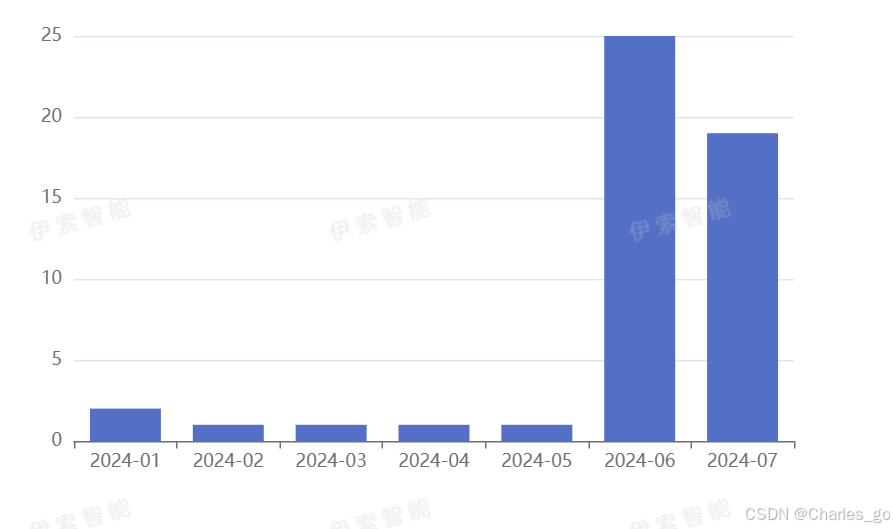
报表
echarts
1.sql
select DATE_FORMAT(created_at,'%Y-%m')from packagings limit 10;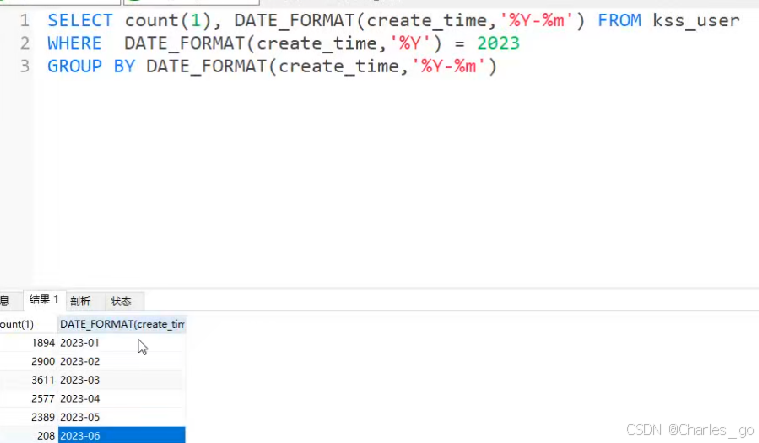
select template_id,count(template_id) FROM packagings group by template_id
select date_format(created_at,'%Y-%M'),count(created_at) FROM packagings group by date_format(created_at,'%Y-%M')
count不统计空列。
2.echarts
3.在前端补数据
不消化服务器资源。
查询用raw。
自己写一个
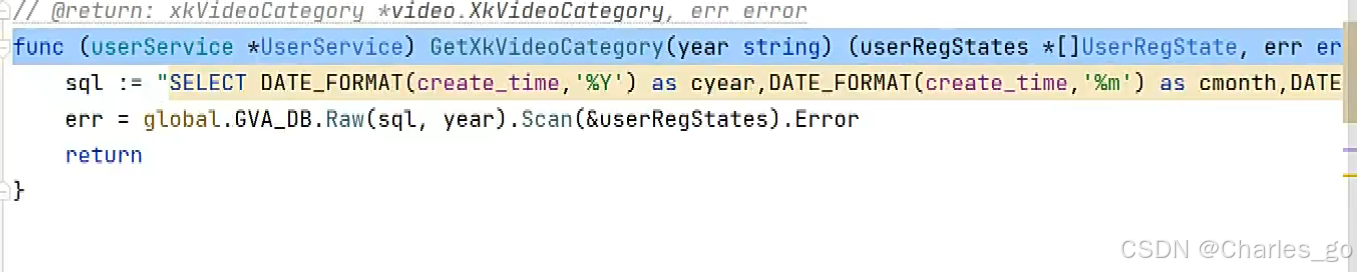
type UserRegSate struct {
Ym string `json:"ym"`
Cnum string `json:"cnum"`
}
func (PackagingService *PackagingService) GetxKVIDEO(year string) (UserRegSate *[]UserRegSate, err error) {
sql := "select date_format(created_at,'%Y-%M') as ym,count(created_at) as cnum FROM packagings where date_format(created_at,'%Y')=? group by date_format(created_at,'%Y-%M')"
err = global.GVA_DB.Raw(sql, year).Scan(&UserRegSate).Error
return
}
func (resourceApi *PackagingApi) GetxKVIDEO(c *gin.Context) {
year := c.Query("year")
if year == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "year parameter is required"})
return
}
userdata, err := PackagingService.GetxKVIDEO(year)
if err != nil {
// 如果发生错误,返回错误响应
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
response.OkWithData(userdata, c)
}
packagingRouter.GET("GetxKVIDEO", packagingApi.GetxKVIDEO) //测试报表前端,前端接收数据,二维变成一维。
//测试用的报表
export const userRegState=(year)=>{
return service({
url:'/packaging/GetxKVIDEO?year='+year,
method:'get'
})
}
import {userRegState} from "@/api/p_packaging"
const handle1 =async()=>{
const year=2024
const resp=await userRegState(year)
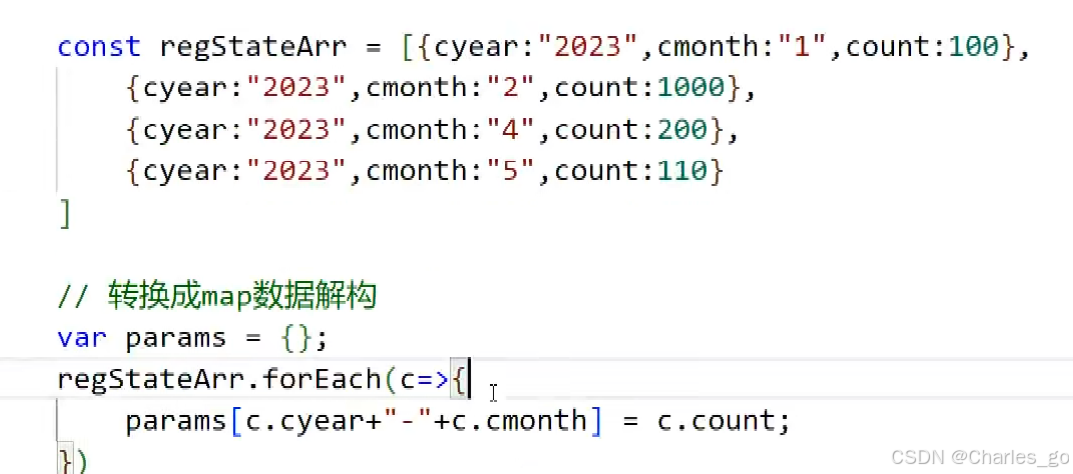
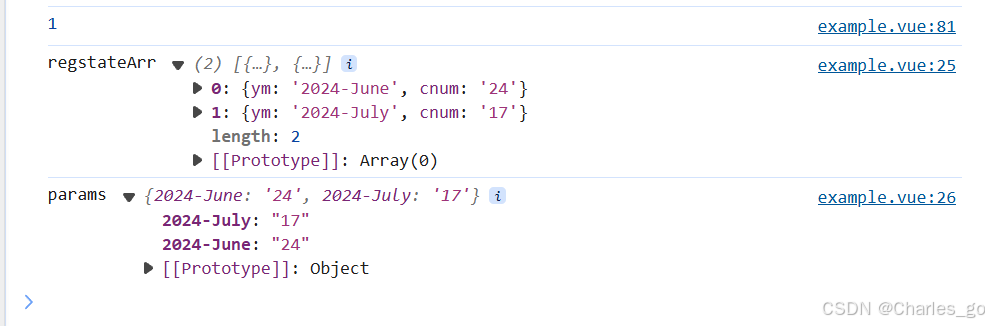
const regStateArr=resp.data;
var params={};
if (regStateArr && regStateArr.length>0){
regStateArr.forEach(c=>{
params[c.ym]=c.cnum;
})
}
console.log("regstateArr",regStateArr)
console.log("params",params)
}
onMounted(()=>{
//统计报表
// handleLoadCharts();
console.log(1)
handle1();
}) 
const handle1 =async()=>{
var myChart = echarts.init(document.getElementById('main'));
const year=2024
const resp=await userRegState(year)
const regStateArr=resp.data;
var params={};
if (regStateArr && regStateArr.length>0){
regStateArr.forEach(c=>{
params[c.ym]=c.cnum;
})
}
console.log("regstateArr",regStateArr)
console.log("params",params)
//每个月
var xdata=[];
//每个月对应的数据
var ydata=[];
if (params && Object.keys(params).length > 0) {
// 遍历 params 对象
for (var key in params) {
if (params.hasOwnProperty(key)) {
// 将键(时间)添加到 xdata 数组
xdata.push(key);
// 将值(数量)转换为数字并添加到 ydata 数组
ydata.push(parseInt(params[key], 10));
}
}
}
console.log("ydata",ydata)
console.log("xdata",xdata)
// 绘制图表
myChart.setOption({
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
xAxis: {
data: xdata
},
yAxis: {},
series: [
{
name: '销量',
type: 'bar',
data: ydata
}
]
});
}
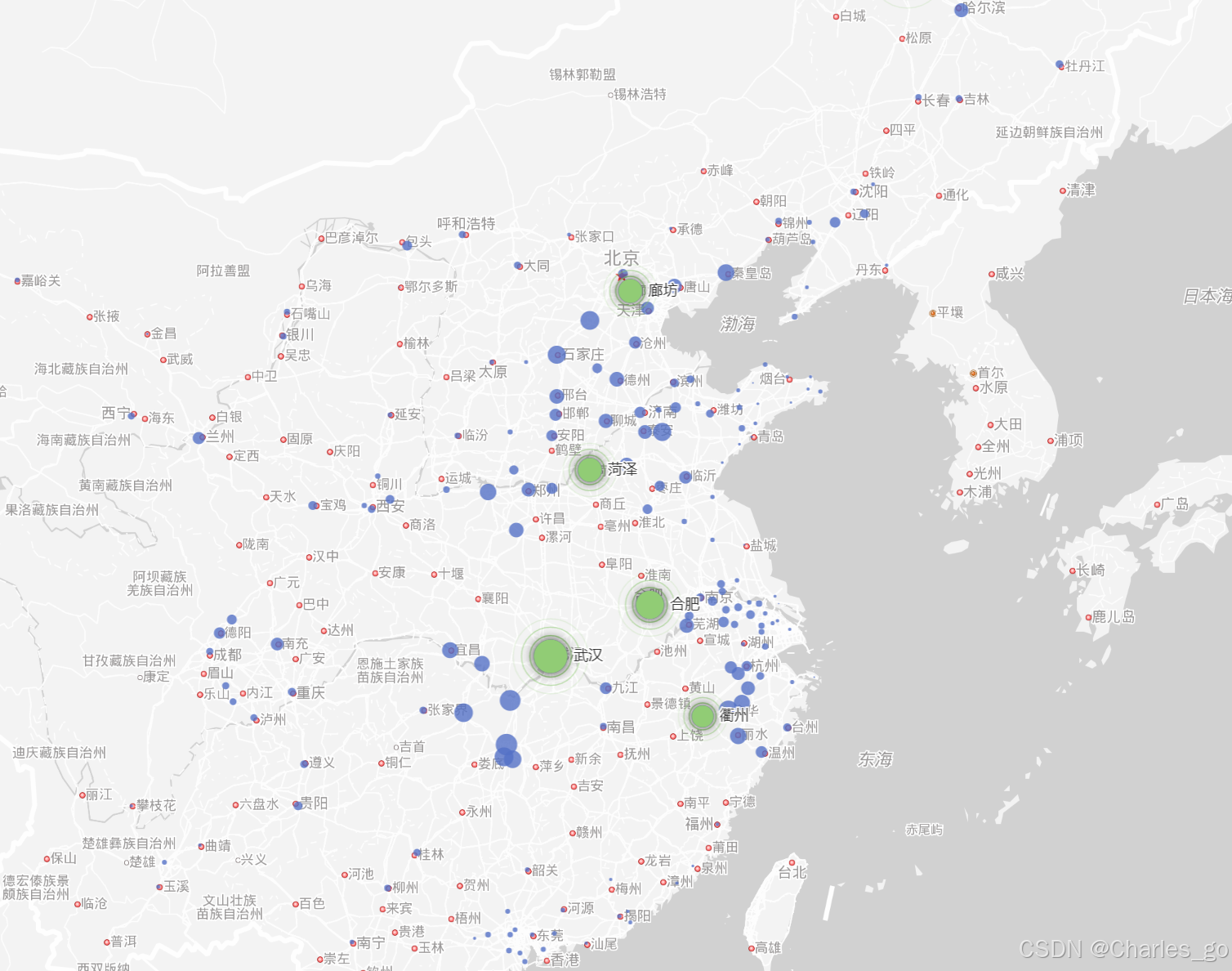
地图展示
1.对接地图
必要参数:城市名字、经度纬度
如何计算两点距离:两点进度和维度 GeoApi实现(redis)
2、具体步骤
引入百度地图,热力图
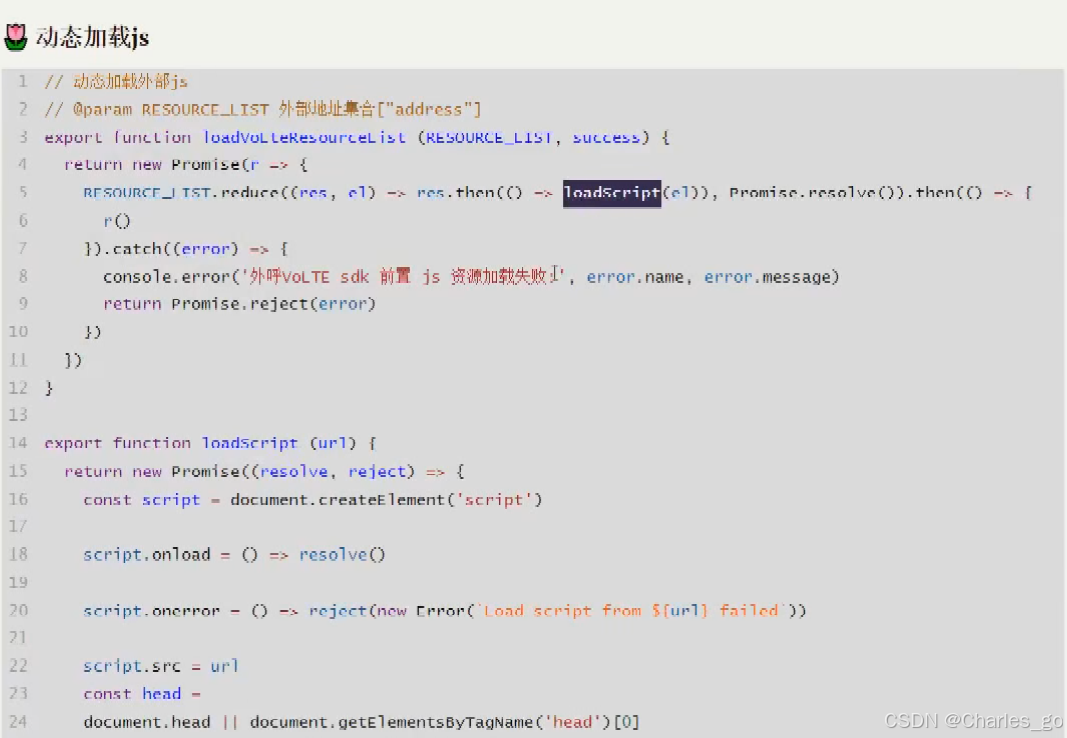
3、如何在自己的spa单页中引入外部的js
全局做法
在vue的项目中index.html文件的head位置,引入外部的script即可。不是最佳。
动态加载js
最好。在utils包下建立一个loadscript.js文件
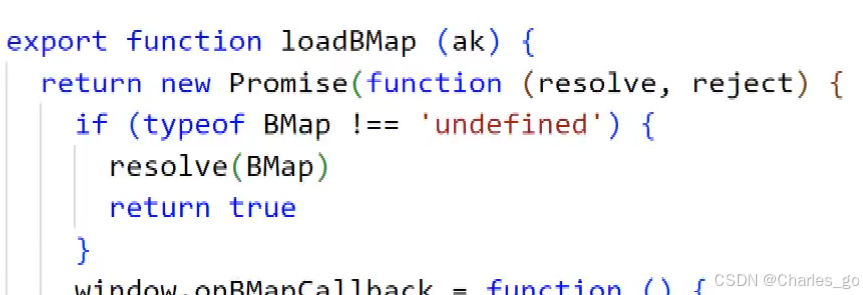
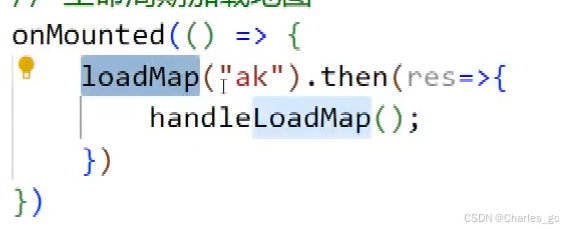
如何获取AK呢?
在百度地图注册账号,找到控制台
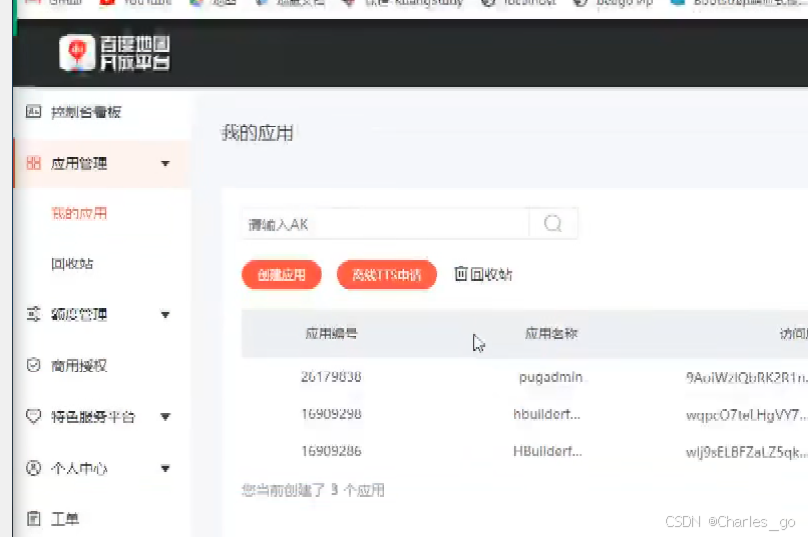
将ak填上去,loadMap
可以做一个监控软件,每秒获取经纬度,然后根据时间两点连成线 。
中国地图:
http://t.csdnimg.cn/GdLfb
geojson 是中国地图每一刻的坐标数据。
建立一个echats.js
从官网上找你要的组件,然后注册进去



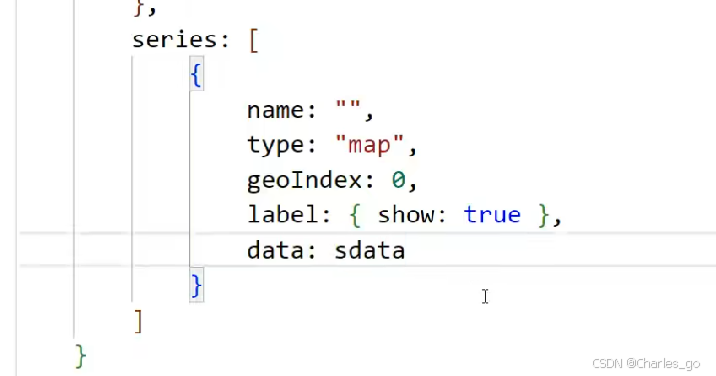 可以在这里加一个后端接口。数据返回格式sdata。
可以在这里加一个后端接口。数据返回格式sdata。
视频上传,大文件上传
断点续传
项目开发流程

视频模块

计划表
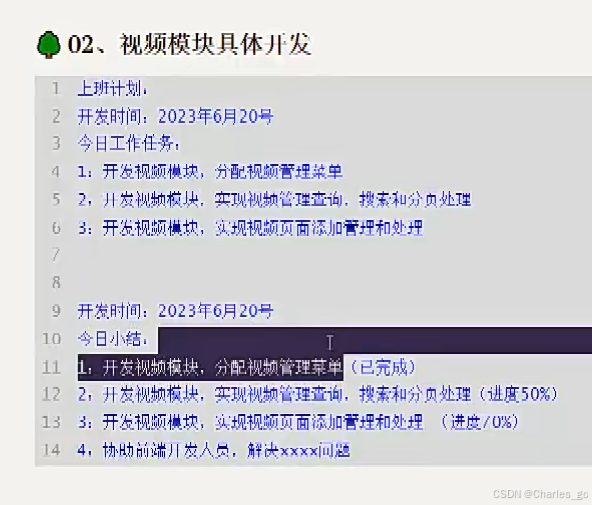
查询



INT
-
int:
- 在32位系统中,
int通常是32位(4字节)宽,其表示范围为-2,147,483,648到2,147,483,647(有符号)。 - 在64位系统中,
int可能仍然是32位,或者在某些语言和平台上可能是64位(8字节)宽。如果是64位,其表示范围为-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
- 在32位系统中,
-
int8(或
signed char在C/C++中):int8是8位(1字节)宽的有符号整数。- 其表示范围为
-128到127。
-
int16(或
short在C/C++中):int16是16位(2字节)宽的有符号整数。- 其表示范围为
-32,768到32,767。
-
int32:
int32是32位(4字节)宽的有符号整数。- 其表示范围为
-2,147,483,648到2,147,483,647。
-
int64(或
long long在C/C++中):int64是64位(8字节)宽的有符号整数。- 其表示范围为
-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
uint8 是一个无符号整数类型,表示8位(1字节)宽的整数。以下是 uint8 的一些关键特性:
- 位数:8位,即1字节。
- 范围:
uint8可以表示的数值范围是从0到2^8 - 1。 - 具体数值:这意味着
uint8的值可以是0、1、2,一直到255。
建表规则
- 字段类型一定要合适,不要使用默认值。因为grom框加已经设定了:string —- varchar(191)
- 表的列尽量不要允许为null。
- 数字列,一定要有一个默认值。(未来你的程序代码中可能不用去维护这个列,但是插入表中的时候就用这个默认值去填充,否则就必须通过代码去维护。)
- 字符串一定是空字符。
- 字段的长度也要考横
查询过程中遇到大字段怎么办
- longtext- text- blob 都是属于超大文本字段,如果你页面不需要就不要返回,因为这中字段在返回消耗很大的内存和处理。你sql执行就会返回的时候就非常的慢。因为你的数据量非常的大,
- 解决方案1:如果不明细查询,页面上返回一定要这些大字段过滤掉。否则就造成数据在渲染的过程会等待很久,甚至可能超时报错。
- 如果开发我们明细查询是一定要返回大字段列的怎么办?
- 拆表,把基础字段放一个表,大字段放到另外一个表中,形成1:1,
- 然后使用异步请求根据id在去从表去把对应大字段列的数据在进行返回
- 解决方案2:
- 查询的过滤掉即可。查询不要携带这些大字段列
- 明细也要过滤掉,然后使用异步请求根据id在去从表去把对应大字段列的数据在进行返回
from 是管query参数,json管body里面的json。
避免每次查询都查大量数据,可以使用分段查询,用时间来查今天的


















 4575
4575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









