







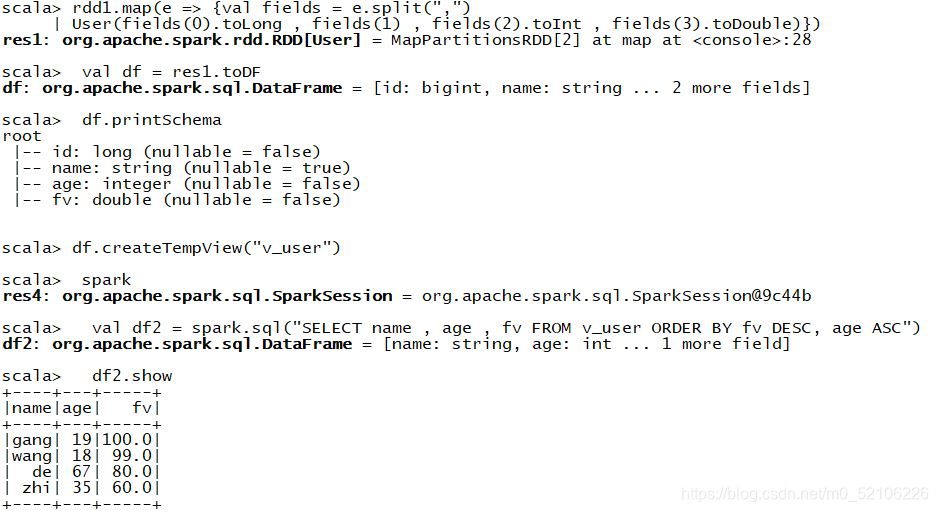
在spaek-shell端演示
1.val rdd1 =sc.textFile(“hdfs://linux01:8020/1.txt”)
2.case class User(id:Long , name:String , age:Int , fv:Double)
3.rdd1.map(e => {val fields = e.split(",")
User(fields(0).toLong , fields(1) , fields(2).toInt , fields(3).toDouble)})
4.val df = res1.toDF 转成dataframe
5.df.printSchema
6.df.createTempView(“v_user”) 注册成视图(一个特殊的表)
7.spark
8.val df2 = spark.sql(“SELECT name , age , fv FROM v_user ORDER BY fv DESC, age ASC”)
9.df2.show
desc是倒叙
asc是正序

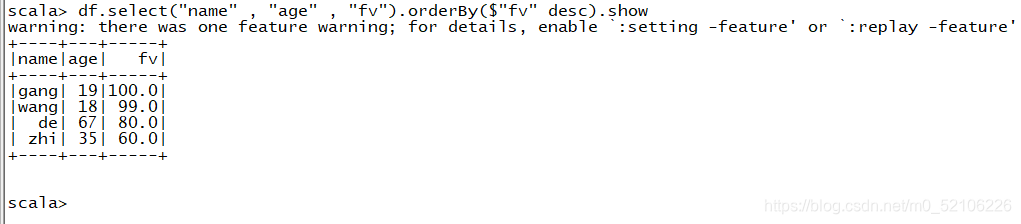
还有一种方法
df.select(“name” , “age” , “fv”).orderBy($“fv” desc).show
使用多种方法创建DateFrame
第一种将RDD关联Case class创建DateFrame
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
//将RDD关联Case class创建DateFrame
object DataFrameCreatDemo01 {
def main(args: Array[String]): Unit = {
//创建SparkConf,然后创建SparkContext
//使用SparkContext创建RDD
//调用RDD的算子(Teansformation和Action)
//释放资源sc.stop
//创建SparkSession(是对SparkContext的包装和增强)
val spark = SparkSession.builder()
.appName("DataFrame")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/1.txt")
val userRDD: RDD[User] = rdd1.map(e => {
val fields = e.split(",")
User(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//导入隐式转换
import spark.implicits._
//将RDD转成特殊的数据集
val df: DataFrame = userRDD.toDF
//使用两种风格的API
//SOL风格
df.createTempView("v_user")
val df2 = spark.sql("select id,name , fv from v_user order by fv")
//show只是默认显示20 行,如果想看更多可以向括号里写
df2.show()
//DSL(特定领域语法)
//不用注册视图
val df3 = df.select("id", "name", "fv") orderBy($"fv".desc, $"age".desc)
df3.show()
}
}
case class User(id:Long , name:String , age:Int , fv: Double )
将RDD关联scala class创建DataForame
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import scala.beans.BeanProperty
//将RDD关联scala class创建DataForame
object DataFrameCreatDemo02 {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和加强)
val session = SparkSession.builder()
.appName("DataFrameCreatDemo02")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1 = sc.textFile("hdfs://linux01:8020/1.txt")
val PersonRDD = rdd1.map(e => {
val fields = e.split(",")
new Person(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
// PersonRDD.persist(StorageLevel.DISK_ONLY)
// PersonRDD.count()
//将RDD转换成特殊的数据集 参数一rdd 参数二类型
val df = session.createDataFrame(PersonRDD, classOf[Person])
//SQL风格
df.createTempView("v_user")
val df2 = session.sql("select id ,name , fv from v_user order by fv desc ,age asc")
df2.show()
}
}
class Person(//因为没有get和set方法所以打上注解
@BeanProperty
val id :Long,
@BeanProperty
val name: String,
@BeanProperty
val age :Int,
@BeanProperty
val fv :Double
)
最正宗的 将RDD中的数据转成row,并关联schema
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
//将RDD中的数据转成row,并关联schema
object DataFrameCreatDemo03 {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session = SparkSession.builder()
.appName("DataFrameCreatDemo03")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1 = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id",LongType),
StructField("name",StringType),
StructField("age",IntegerType),
StructField("fv",DoubleType)
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
//打印字段名称和字段类型
df.printSchema()
df.show()
}
}
通过DJSON文件创建DataFrame
import org.apache.spark.sql.{DataFrame, SparkSession}
//通过DJSON文件创建DataFrame
object CreatDataFreamFromJSON {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
//RDD数据从哪里读取
//schema:字段名,类型(json文件中自带schema属性)
val df: DataFrame = spark.read.json("D:\\ideawork\\spark\\src\\main\\scala\\cn\\_51doit\\demo05DateFrame\\user.json")
// df.createTempView("v_user")
//_corrupt_record脏数据
// val df2 = spark.sql("select name , fv ,age from v_user where _corrupt_record is null")
// df2.show()
//DSL方法 要给$这个特殊的方法导包
import spark.implicits._
val df2 = df.select("name", "fv", "age").where($"_corrupt_record".isNull)
df2.show()
}
}
将读到的数据写成JSON文件
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
//将RDD中的数据转成row,并关联schema
object WriteToJSON {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session = SparkSession.builder()
.appName("DataFrameCreatDemo03")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1 = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id",LongType),
StructField("name",StringType),
StructField("age",IntegerType),
StructField("fv",DoubleType)
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
//把获得的数据转成json写本地
df.write.json("d:/aaa/222/out")
session.stop()
}
}
通过csv文件创建DataFrame
import org.apache.spark.sql.SparkSession
//通过csv文件创建DataFrame
object CreatDataFreamFromCSV {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和加强)
val spark = SparkSession.builder()
.appName(this.getClass.getCanonicalName)
.master("local[*]")
.getOrCreate()
//RDD数据从哪里读数据
//schema:字段名称,类型(csv文件自带schema属性)
val df = spark.read
.option("header", "true") //将第一行当作表头
.option("inferSchema", "true") //推断数据类型
.csv("D:\\ideawork\\spark\\src\\main\\scala\\cn\\_51doit\\demo05DateFrame\\user.csv")
//修改名称
//val df2 = df.toDF("name", "age", "fv")
df.show()
df.printSchema()
Thread.sleep(100000000)
}
}
将读到的数据写成csv文件
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
//将RDD中的数据转成row,并关联schema
object WriteToCsv {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo01")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型,没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id", LongType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv", DoubleType),
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
//以csv格式写出括号里写出路径
df.write.csv("d:/aaa/222/outcsv2")
session.stop()
}
}
通过JDBC文件创建DataFream(从mysql中读文件)
import java.util.Properties
import org.apache.spark.sql.SparkSession
object CreatDataFreamFromJDBC {
def main(args: Array[String]): Unit = {
//通过JDBC文件创建DataFream
//创建SparkSession(是对SparkContext的包装和增强)
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
//获取连接数据库的用户名密码
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//一定要有schema信息
//在执行时调用read.jdbc方法一定要获取数据库表的信息
//read.jdbc是在Driver端跟数据库查询,返回指定表的schema信息
val df = spark.read.jdbc("jdbc:mysql://localhost:3306/doit_19?characterEncoding=utf-8", "tb_user", properties)
df.show()
Thread.sleep(100000000)
}
}
将读到的数据写到mysql中
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
//将RDD中的数据转成row,并关联schema
object WriteToJDBC {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session: SparkSession = SparkSession.builder()
.appName("WriteToJDBC")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型,没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id", LongType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv", DoubleType),
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//ErrorIfExists如果输出的目录或表已经存在就报错
//Append 追加
//Overwrite 将原来的目录或数据库表删除,然后在新建目录或表将数据写入
//Ignore 没有就写入,有就什么都不做
df.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/doit_19?characterEncoding=utf-8", "tb_doit19", properties)
session.stop()
}
}
将从hdfs上读到的文件改成parquet格式写如本地
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
object WriteToParquet {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo01")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型,没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id", LongType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv", DoubleType),
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
df.write.parquet("d://aaa//222//par")
session.stop()
}
}
读取本地的parquet文件
import org.apache.spark.sql.SparkSession
object CreateDataFrameFromParquet {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val df = spark.read.parquet("d://aaa//222//par")
df.show()
df.printSchema()
Thread.sleep(1000000)
}
}
JSON的
优点,
数据中自带schema,数据格式丰富,支持嵌套类型。
缺点:传输、存储了很多冗余的数据
name,age,fv,gender
laozhao,18,9999.99,male
lauduan,18,999.99,male
CSV:
特点:数据存储相对比较紧凑
缺点:schema信息不完整,数据格式比较单一
Parquet是SparkSQL的最爱
数据中自带schema(头尾信息:数据的描述信息),数据格式丰富,支持嵌套类型。数据存储紧凑、列式存储(支持压缩)、查询快(按需查询、快速定位)
从hdfs上读取文件以orc的格式写入本地
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
object WriteToOrc {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val session: SparkSession = SparkSession.builder()
.appName("DataFrameCreateDemo01")
.master("local[*]")
.getOrCreate()
val sc = session.sparkContext
val rdd1: RDD[String] = sc.textFile("hdfs://linux01:8020/1.txt")
//row的字段没有类型,没有名称
val rowRDD: RDD[Row] = rdd1.map(e => {
val fields = e.split(",")
Row(fields(0).toLong, fields(1), fields(2).toInt, fields(3).toDouble)
})
//关联schema(字段名称,数据类型,是否可以为空)
val schema = StructType(
Array(
StructField("id", LongType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("fv", DoubleType),
)
)
//将RowRDD和StructType类型的Schema进行关联
val df = session.createDataFrame(rowRDD, schema)
df.write.orc("d://aaa//222//orc")
session.stop()
}
}
从本地读取orc格式的文件
import org.apache.spark.sql.{DataFrame, SparkSession}
//通过csv文件创建DataFrame
object CreateDataFrameFromOrc {
def main(args: Array[String]): Unit = {
//创建SparkSession(是对SparkContext的包装和增强)
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val df: DataFrame = spark.read.orc("d://aaa//222//orc")
df.show(2)
df.printSchema()
Thread.sleep(10000000)
}
}

















 9050
9050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









