







神经网络模型
1.人工神经网络
人工神经网络:
大量的神经元以某种连接方式构成的机器学习模型。
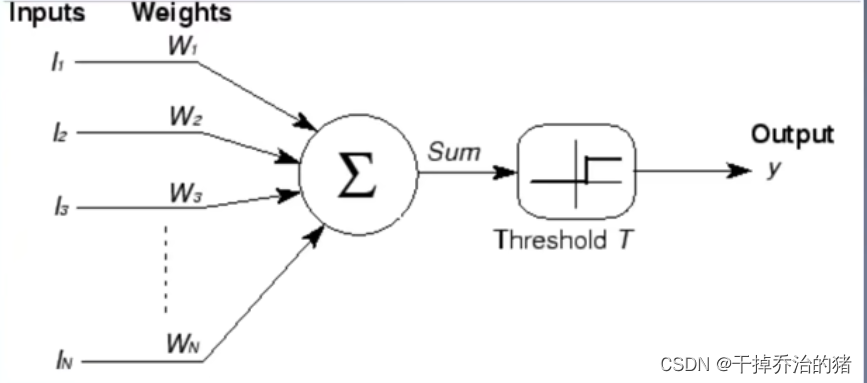
模型:M-P模型
公式:
y = f ( ∑ i = 1 n I i w i ) \color{red}y = f(\displaystyle\sum_{i=1}^{n}{I_i}w_i) y=f(i=1∑nIiwi)
参数:
I i : \color{green}{I_i}: Ii: 输入的样本数据
w i : \color{green}{w_i}: wi: 权重
f : \color{green}{f}: f: 激活函数
y : \color{green}{y}: y: 输出数据
2.感知机:
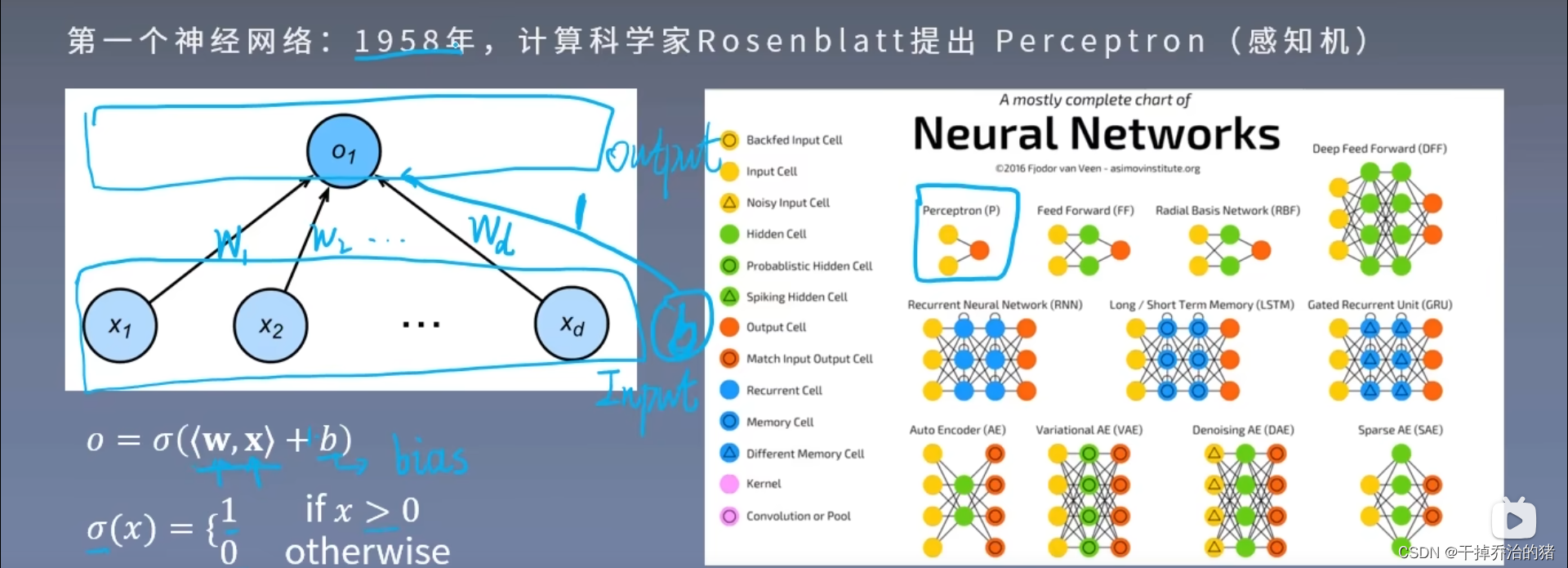
感知机:
Percepttron(感知机)是第一个神经网络
模型:
公式:
O = σ ( < w , x > + b ) \color{red}O=\displaystyle\sigma(<w,x>+b) O=σ(<w,x>+b)
σ = { 1 , x > 0 0 , o t h e r w i s e \color{red}\displaystyle\sigma=\begin{cases}1,\quad x> 0 \\\\0,\quad otherwise\end{cases} σ=⎩ ⎨ ⎧1,x>00,otherwise参数:
O : \color{green}O : O:输出数据
σ : \color{green}\displaystyle\sigma : σ: 激活函数
w : \color{green}w : w:权重
x : \color{green}x : x:输入数据
b : \color{green}b : b:bias,偏置
多层感知机
多层感知机:
在单层神经网络基础上引入一个或多个隐藏层,使神经网络有多个网络层。
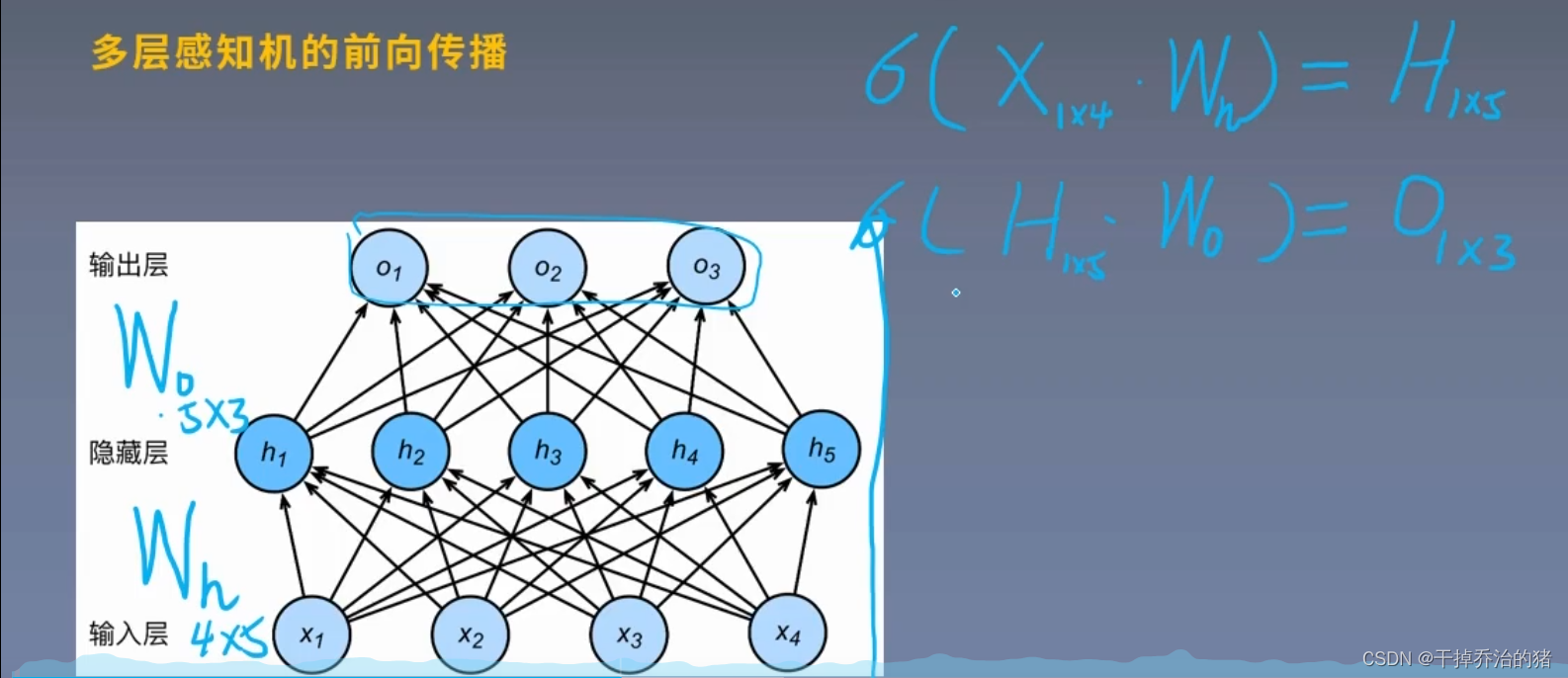
1.多层感知机的前向传播
模型图:
公式:
H 1 × 5 = σ ( X 1 × 4 ⋅ W h ( 4 × 5 ) ) \color{red}H_{1×5}=\displaystyle\sigma({X_{1×4}\cdot W_{h(4×5)}}) H1×5=σ(X1×4⋅Wh(4×5))
O 1 × 3 = σ ( H 1 × 5 ⋅ W o ( 5 × 3 ) ) \color{red}O_{1×3}=\displaystyle\sigma(H_{1×5 }\cdot W_{o(5×3)}) O1×3=σ(H1×5⋅Wo(5×3))参数:
H 1 × 5 : \color{green} H_{1×5}: H1×5: 隐藏层的输出
X 1 × 4 : \color{green} X_{1×4}: X1×4: 输入数据(将输入数据组合成一个1×5的矩阵)
W 5 × 3 : \color{green} W_{5×3}: W5×3: 权重矩阵
O 1 × 3 : \color{green} O_{1×3}: O1×3: 输出数据(最后输出一个1×3的矩阵)2.多层感知机的激活函数
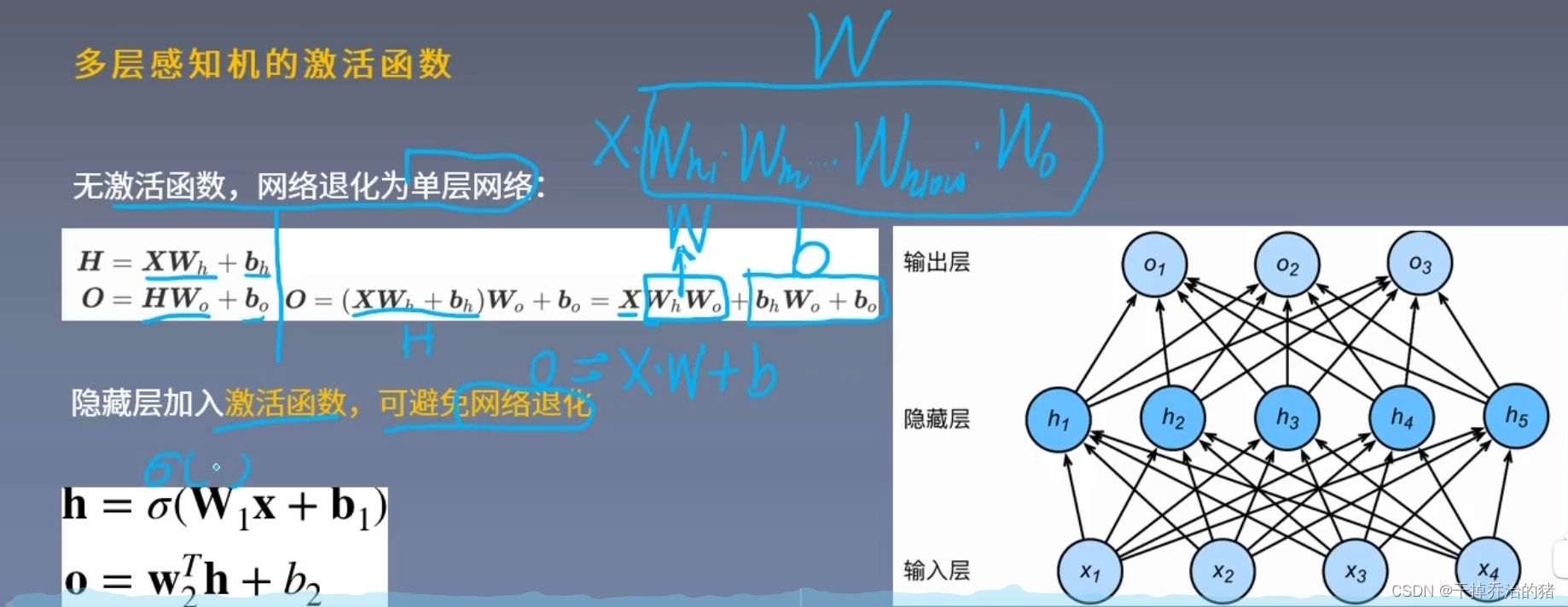
此处主要是为了证明激活函数的意义!---->加入激活函数可避免网络退化为单层网络
模型图:
公式推导:
H = X W h + b h \color{red}H = XW_h+b_h H=XWh+bh ---->隐藏层的输出
O = H W o + b o \color{red}O = HW_o+b_o O=HWo+bo ---->输出层的输出
O = X W b W o + b o = X W h W o + b o \color{red}O = XW_bW_o+b_o = XW_hW_o+b_o O=XWbWo+bo=XWhWo+bo
由于 W h 和 W o \color{red}W_h 和W_o Wh和Wo可以看成一个整体 W \color{red}W W,所以网络退化成单层网络了!
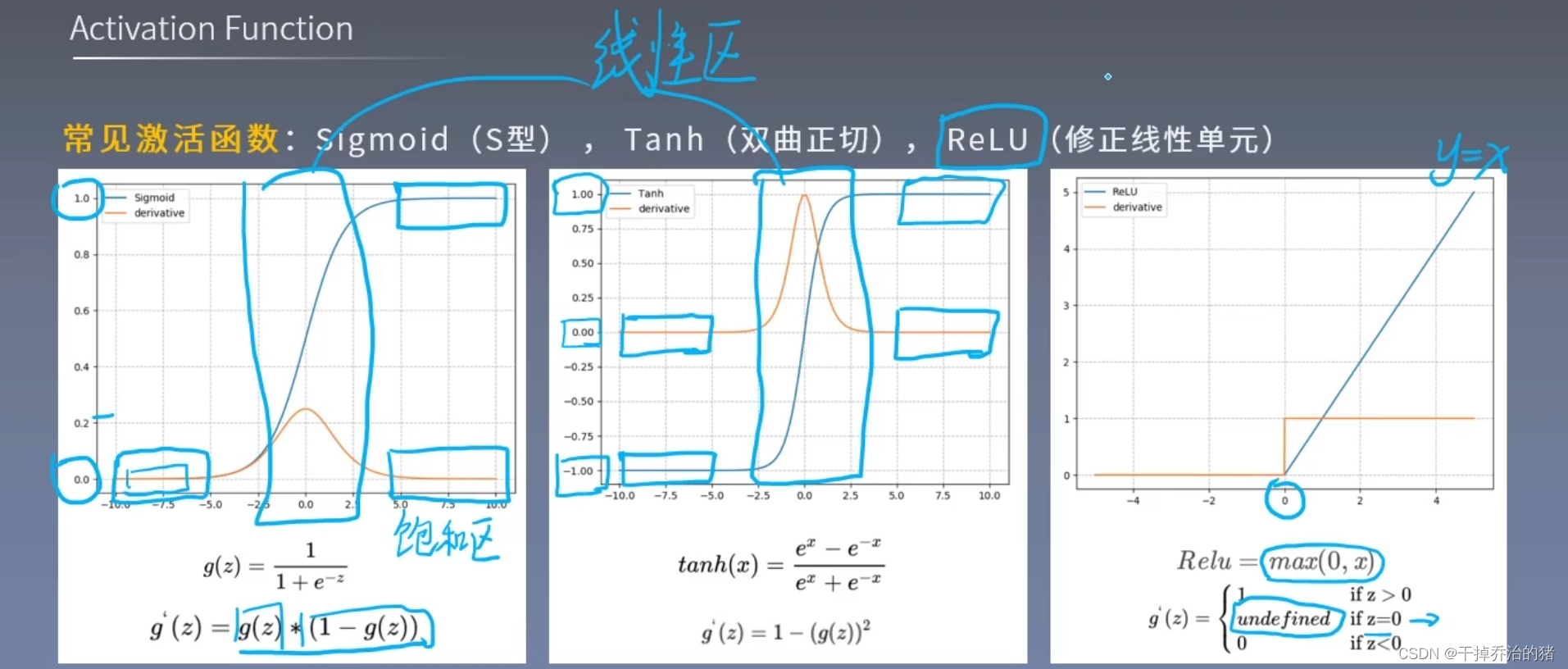
激活函数
激活函数的作用:
激活函数的性质:
激活函数的类型:
目前最常用的激活函数为ReLu激活函数,因为sigmoid函数和Tanh激活函数存在饱和区,从而使梯度接近零,导致在反向传播过程中梯度变化非常小,使得权重更新缓慢,,网络难以学习。


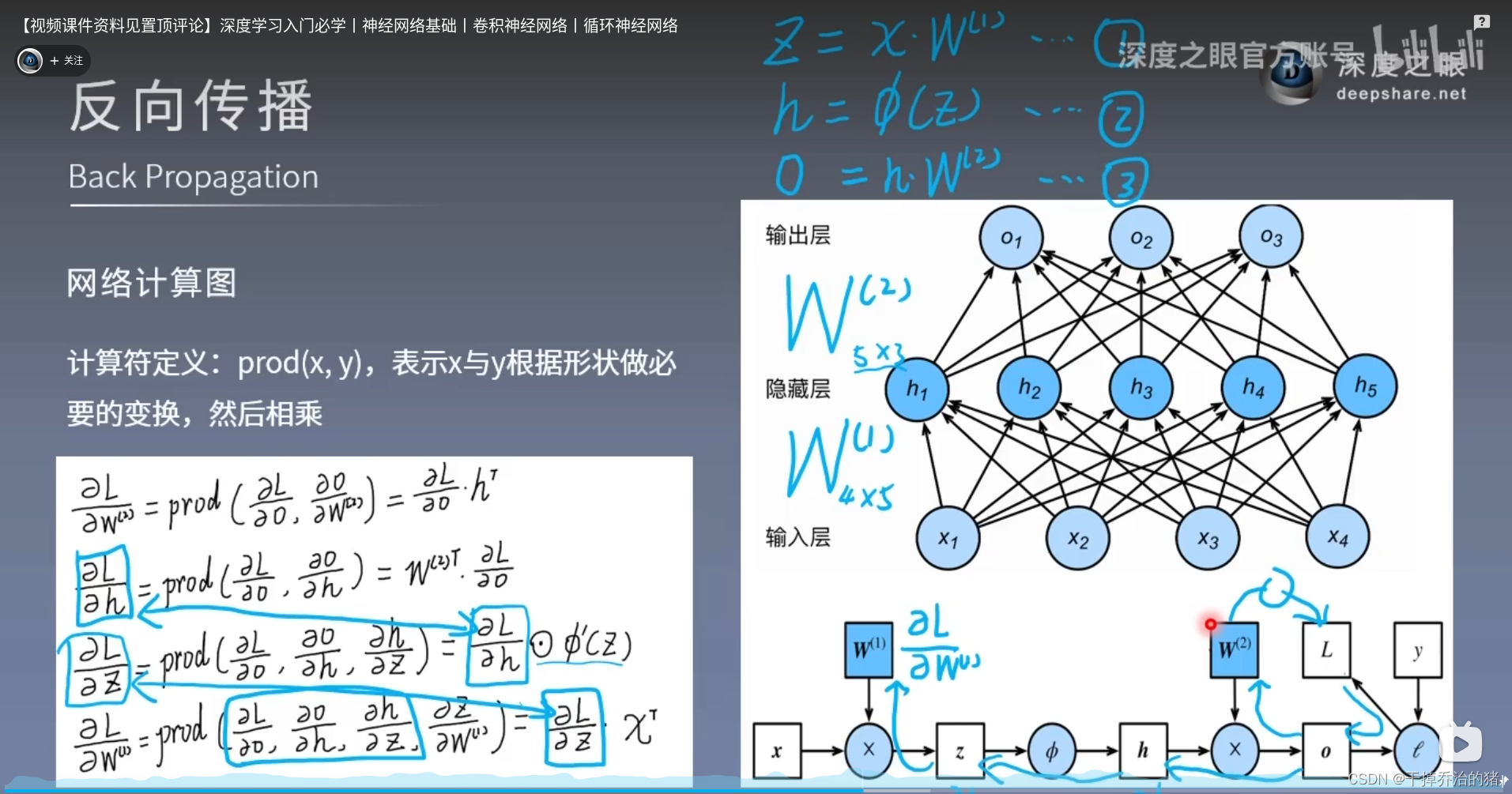
反向传播算法
链式求导法则:y = f ( u ) , u = g ( x ) \color{red}\ y=f(u),u=g(x) y=f(u),u=g(x)
∂ y ∂ x = ∂ y ∂ u ∂ u ∂ x \color{red}\frac{\partial y}{\partial x} =\frac{\partial y}{\partial u} \frac{\partial u}{\partial x} ∂x∂y=∂u∂y∂x∂u1. 前向传播:
输入层数据(样本X数据)开始从前往后,数据逐步传输到输出层
1-2.前向传播公式推导:
z = x ⋅ W 1 \color{red}z = x \cdot W^1 z=x⋅W1.
h = ϕ ( z ) \color{red}h = \phi (z) h=ϕ(z)
O = h ⋅ W 2 \color{red}O = h \cdot W^2 O=h⋅W22.反向传播:
反向传播: 损失函数开始从后向前,梯度逐步传输至第一层
2-1.网络计算图
公式推导:∂ L ∂ W 2 = p r o d ( ∂ L ∂ O , ∂ O ∂ W 2 ) = ∂ L ∂ O ⋅ h T \color{red} \frac{\partial L}{\partial W^2} = prod(\frac{\partial L}{\partial O},\frac{\partial O}{\partial W^2}) = \frac{\partial L}{\partial O} \cdot h^T ∂W2∂L=prod(∂O∂L,∂W2∂O)=∂O∂L⋅hT
∂ L ∂ h = p r o d ( ∂ L ∂ O , ∂ O ∂ h ) = W T \color{red}\frac{\partial L}{\partial h} = prod(\frac{\partial L}{\partial O},\frac{\partial O}{\partial h}) = W^T ∂h∂L=prod(∂O∂L,∂h∂O)=WT
∂ L ∂ z = p r o d ( ∂ L ∂ O , ∂ O ∂ h , ∂ h ∂ z ) = ∂ L ∂ h ⋅ ϕ ( z ) ′ \color{red}\frac{\partial L}{\partial z} = prod(\frac{\partial L}{\partial O},\frac{\partial O}{\partial h},\frac{\partial h}{\partial z}) = \frac{\partial L}{\partial h} \cdot \phi(z)' ∂z∂L=prod(∂O∂L,∂h∂O,∂z∂h)=∂h∂L⋅ϕ(z)′
∂ L ∂ W 2 = p r o d ( ∂ L ∂ O , ∂ O ∂ h , ∂ h ∂ z , ∂ z ∂ W 2 ) = ∂ L ∂ z ⋅ x T \color{red}\frac{\partial L}{\partial W^2} = prod(\frac{\partial L}{\partial O},\frac{\partial O}{\partial h},\frac{\partial h}{\partial z},\frac{\partial z}{\partial W^2}) = \frac{\partial L}{\partial z} \cdot x^T ∂W2∂L=prod(∂O∂L,∂h∂O,∂z∂h,∂W2∂z)=∂z∂L⋅xT2-2.梯度下降法
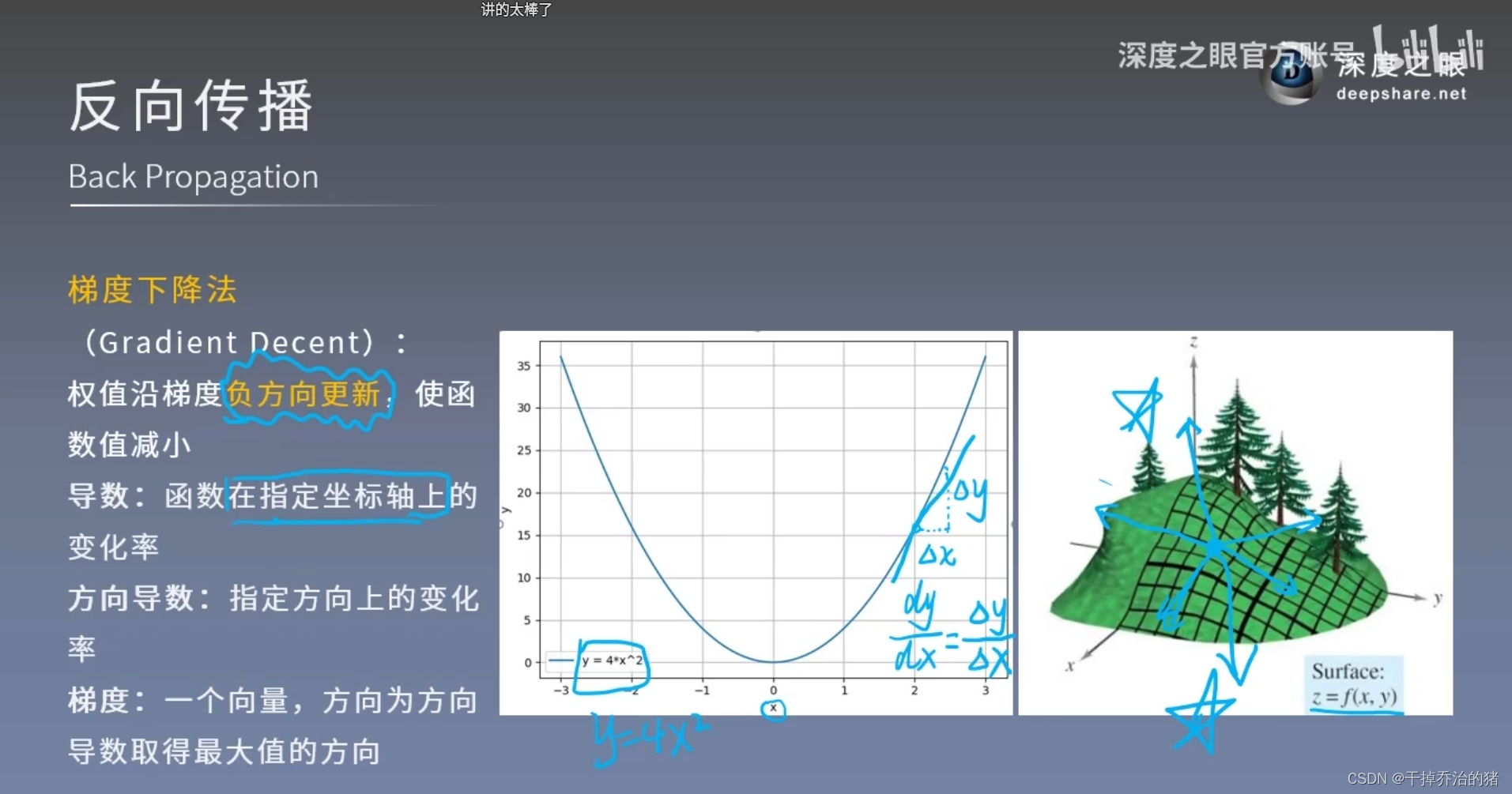
通俗解释:梯度下降方法相当于“下山”策略:
1.“山谷的底部”相当于“函数的最小值,
2.“地面的倾斜程度”相当于“梯度”,
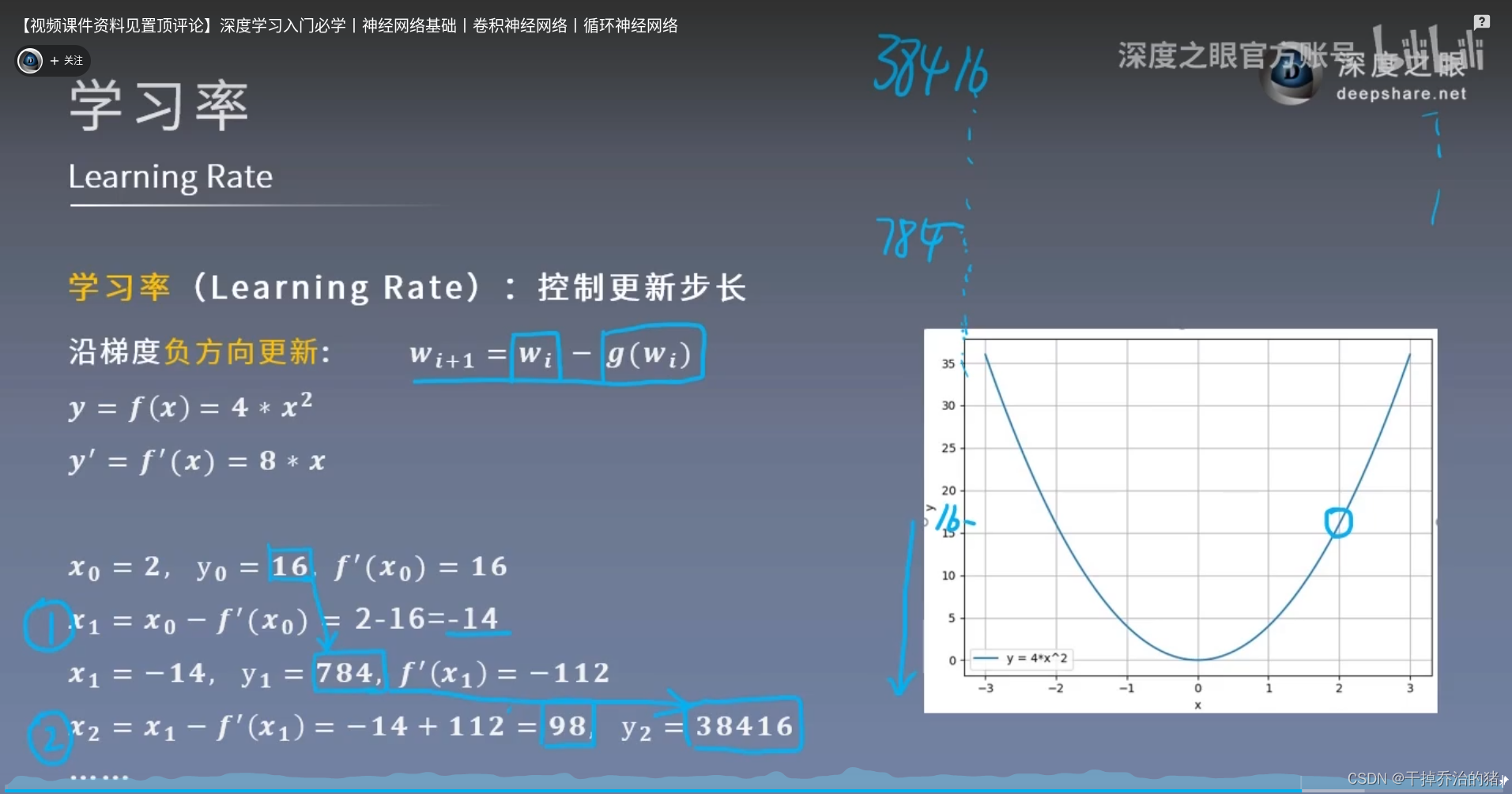
3.“学习率”相当于每次“移动的距离”2-3.学习率
学习率的作用:1.这是针对损失函数来说的。
2.学习率的作用是确保在梯度下降过程中,我们能够沿着损失函数的负梯度方向有效地更新模型的参数,从而逐步减小损失函数的值,逼近全局或局部最小值。
3.这个过程是为了找到一组参数,使得模型能够尽可能准确地预测或分类新的数据。

损失函数
1.损失函数的定义
解释:
1. 损失函数描述的是单样本的差异值
2. 代价函数描述的是总体样本的差异值
3. 目标函数强调的是整个训练过程,它由代价函数和正则项构成1.cost描述模型与标签的差异,使模型输出与标签值更接近,减小cost的值。
2.Regularzition Term(正则项):使模型不要太复杂,减小模型的过拟合2.MSE和CE损失函数
1. MSE:常用于回归任务中。
2. CE:常用于分类任务中。2-1.MSE(均方误差)
公式:
M S E = ∑ i = 1 n ( y i − y i p ) 2 n \color{red}MSE=\frac{\sum_{i =1}^n(y_i-y_i^p)^2}{n} MSE=n∑i=1n(yi−yip)2
参数:
y i : \color{green}y_i: yi:真实值
y i p : \color{green}y_i^p: yip:预测值
M S E : \color{green}MSE: MSE:输出与标签值之差的平方的均值2-2.CE(交叉熵)
公式:
H ( p , q ) = − ∑ i = 1 n p ( x i ) l o g q ( x i ) \color{red}H(p,q) = -\sum_{i=1}^np(x_i)logq(x_i) H(p,q)=−i=1∑np(xi)logq(xi)
参数:
p : \color{green}p: p:标签的真实值
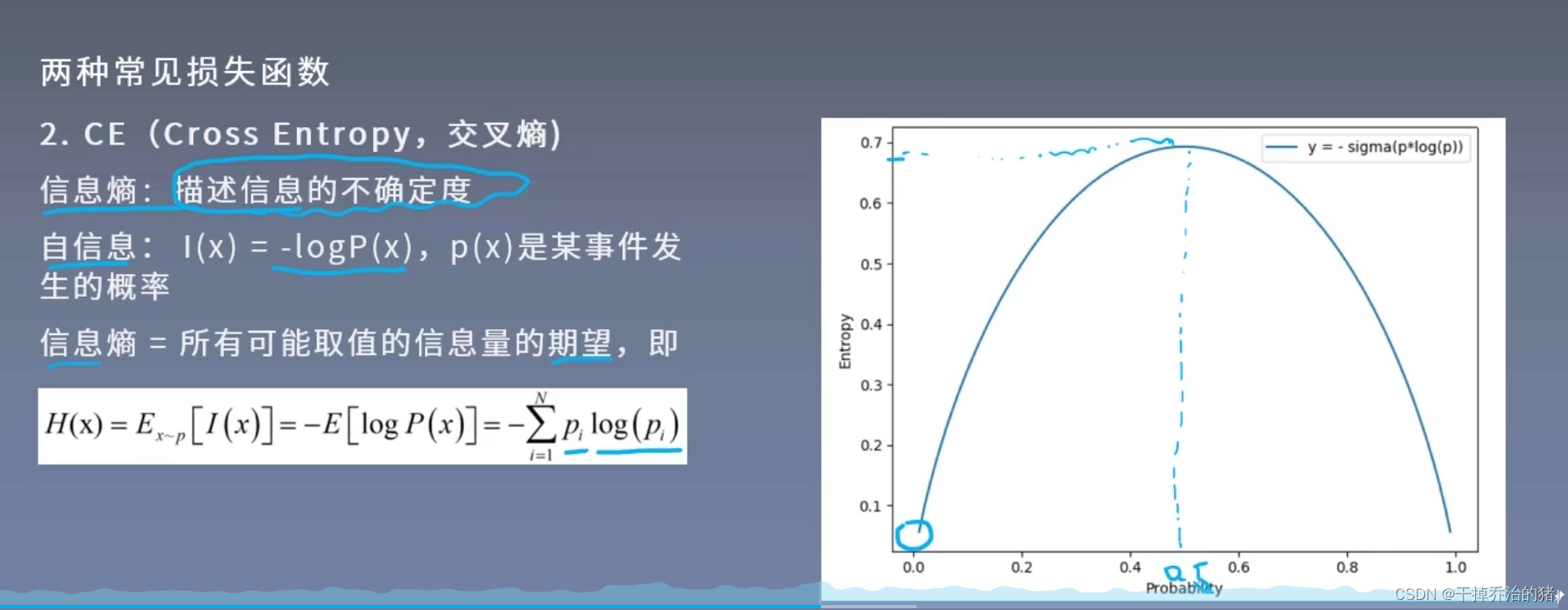
q : \color{green}q: q:model的输出值信息熵:
通俗解释:
1.系统中存在很多不确定的结果
2.每种结果出现的概率大致相同
3.说明混乱程度越大,信息熵就越大相对熵/交叉熵和信息熵之间的关系
通俗解释:1.信息熵:衡量信息不确定的指标,比如 非常不确定的事情信息熵就很大
2.相对熵:衡量两个概率分布之间的差异
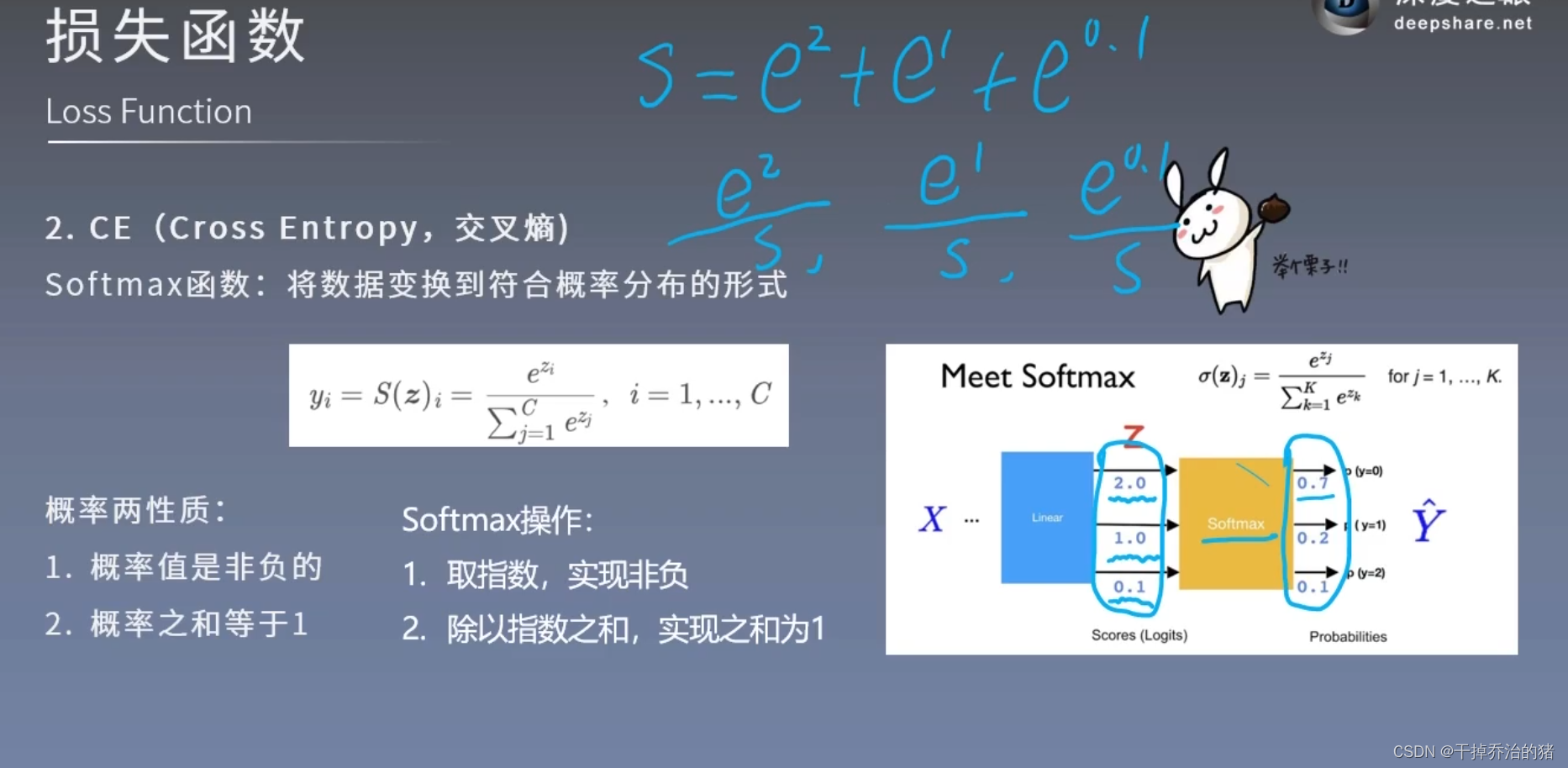
3.交叉熵:衡量模型预测的概率分布和真实标签之间的概率分布的差异,属于相对熵的一种形式!softmax函数
softmax函数就像一个“转换器”,可以把模型的原始输出转换成一个概率分布



权值初始化
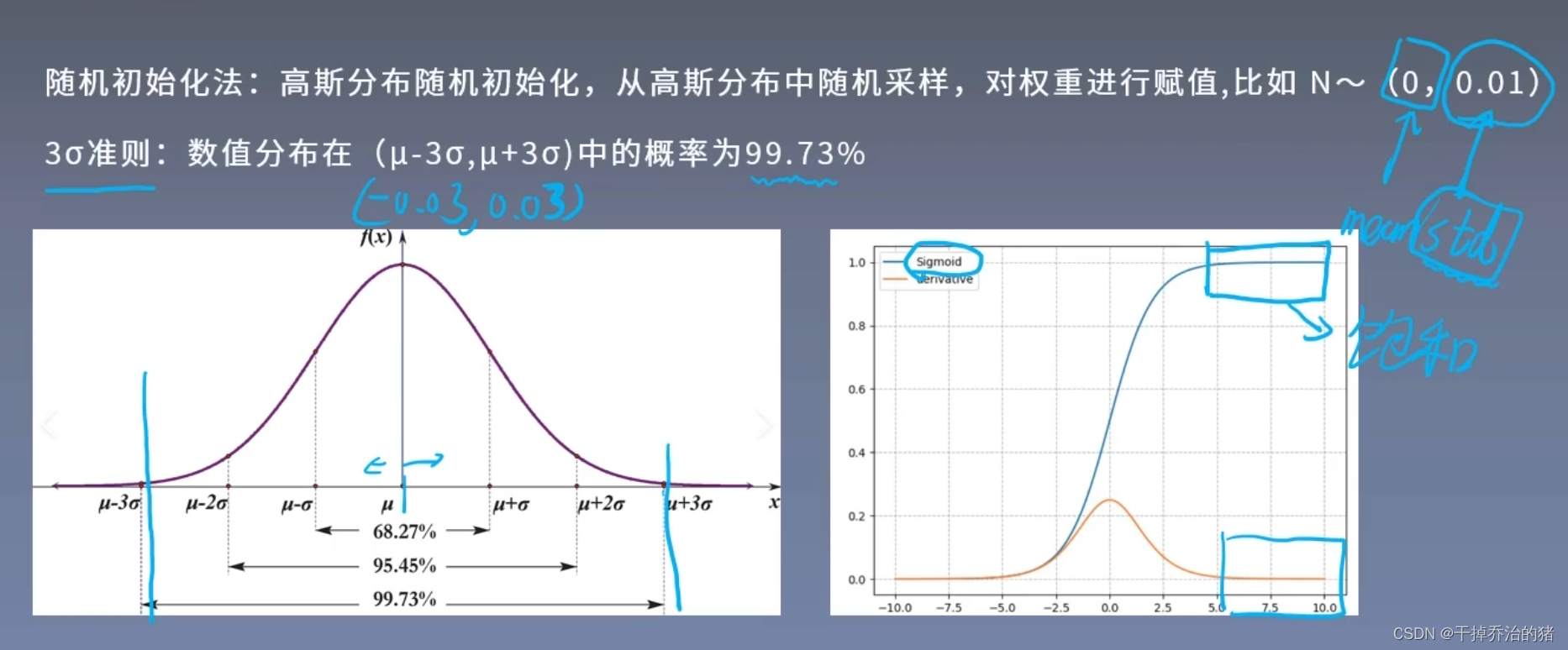
高斯分布:
1.均值:使权重围绕一个中心值(均值为0)随机分布
2.标准差:控制权重分布的离散程度
公式:
W = N ( μ , σ 2 ) \color{red}W = N(\mu,\sigma^2) W=N(μ,σ2)
参数:
1. μ : \color{green}\mu: μ:分布的均值
2. σ : \color{green}\sigma: σ:分布标准差自适应标准差:
1.Xavier初始化方法
Xavier初始化主要适用于sigmoid和tanh激活函数。
2.kaiming初始化方法(MSRA)
Kaiming初始化主要适用于ReLu激活函数。
两种方法都是根据激活函数的特性来决定的!sigmoid和tanh激活函数中标准差既不能过大也不能过小,所以需要考虑前一层神经元和后一层神经元;而ReLu激活函数中要求标准差足够大,这样才能有利于网络的学习!

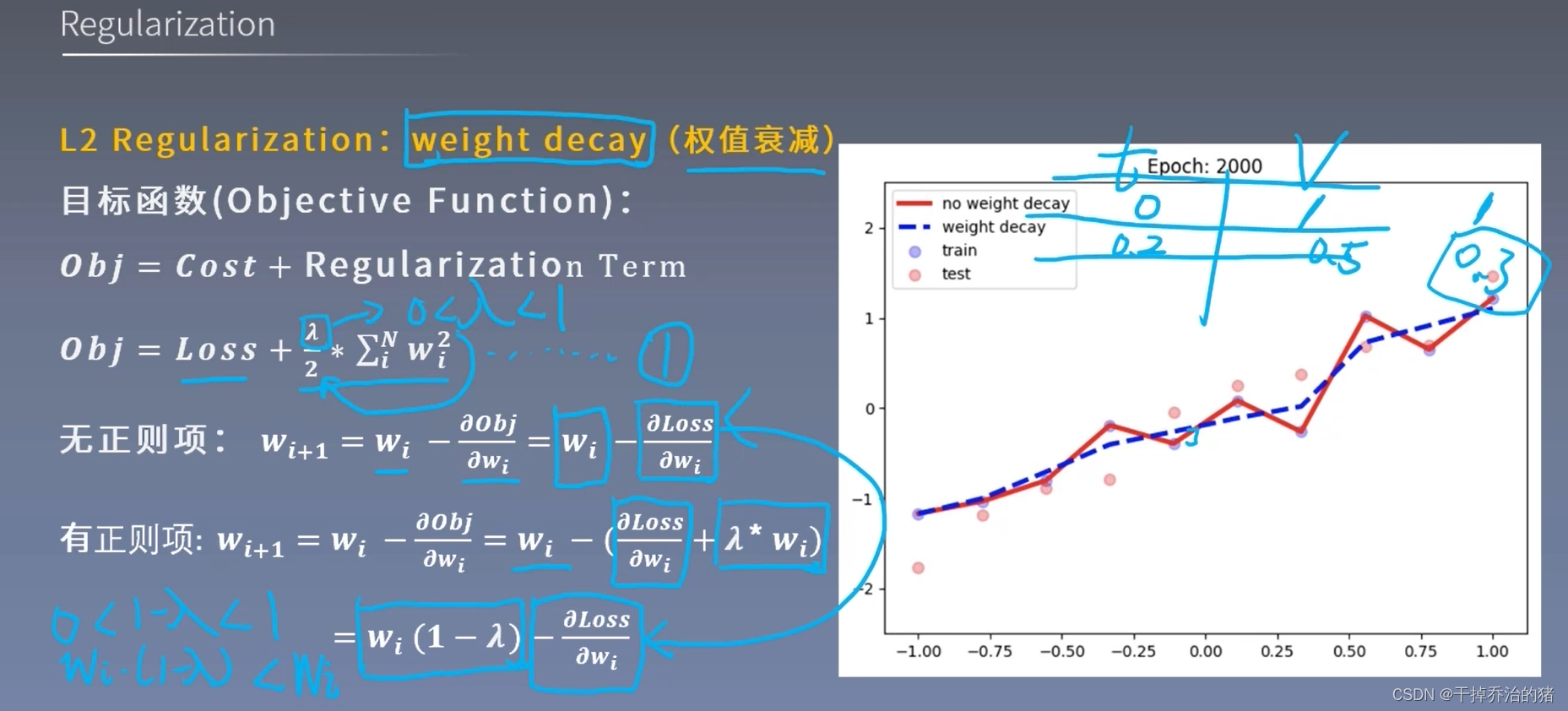
正则化方法
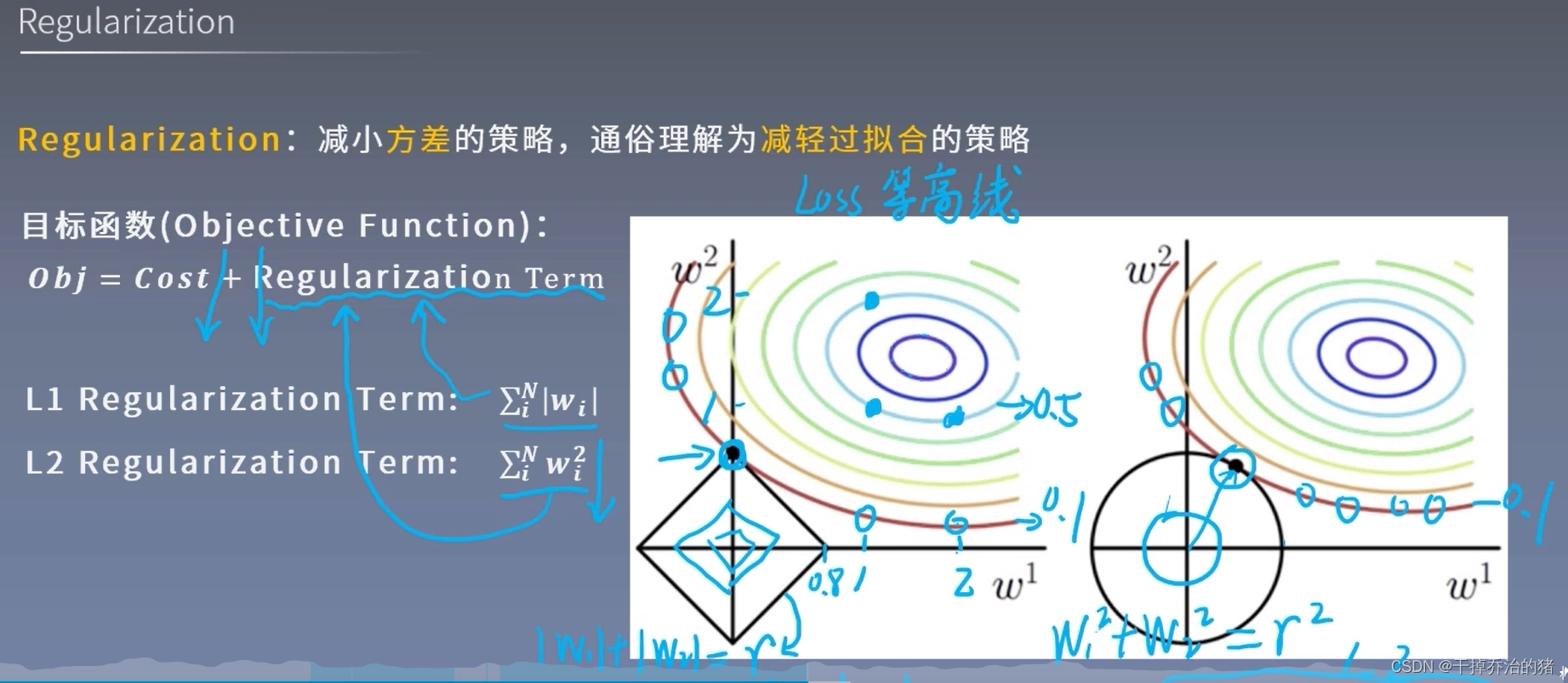
Regularization:
减少方差的策略,减轻过拟合的策略。
L1:
∑ i n ∣ w i ∣ \color{red}\sum_{i}^{n}|w_i| ∑in∣wi∣
L2:
∑ i n w i 2 \color{red}\sum_{i}^{n}w_i^2 ∑inwi2
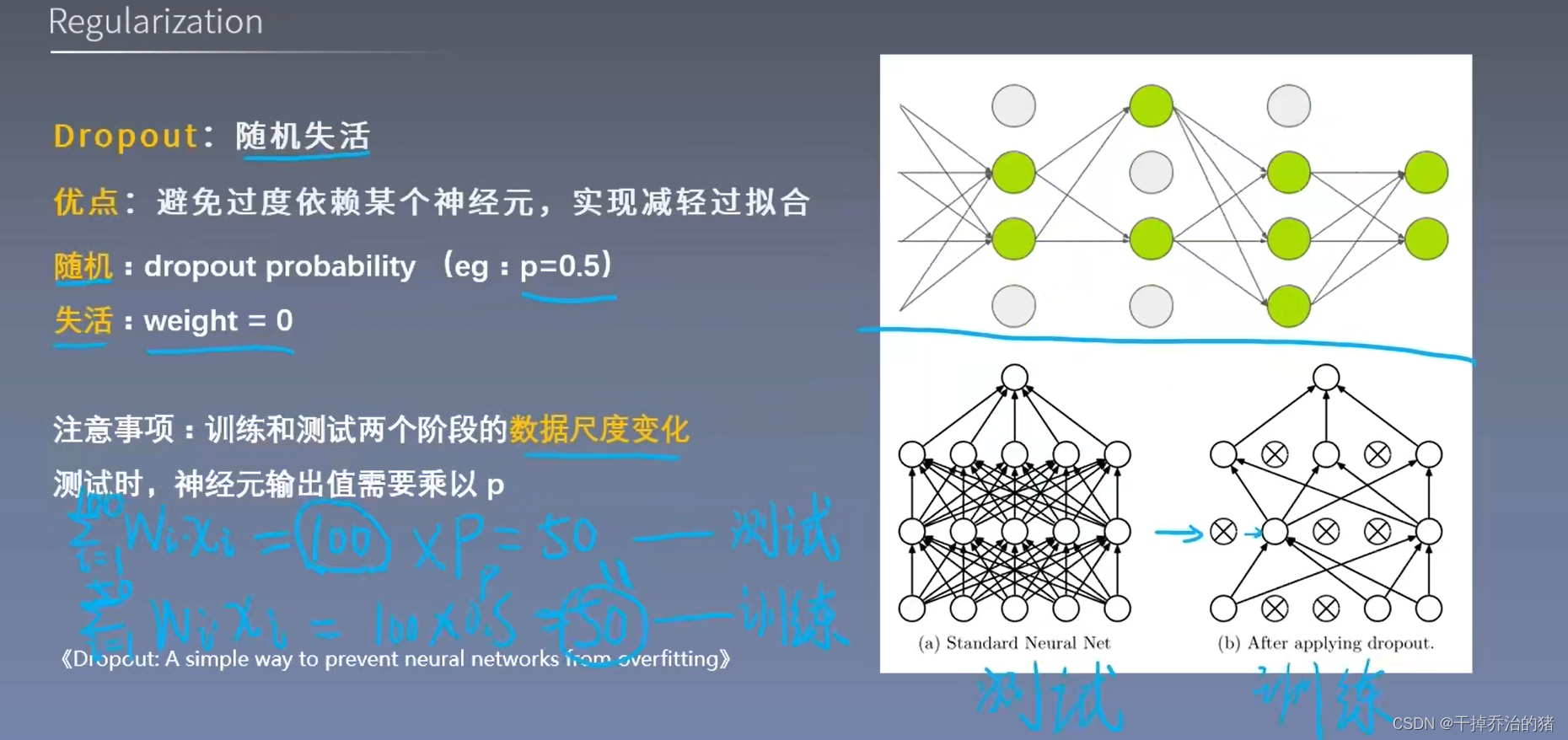
L2的权值衰减避免了模型只在训练数据上表现得好,而在新的数据集上表现差的情况。Dropout:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









