






参考视频与文献:
python与人工智能-KNN算法实现_哔哩哔哩_bilibili
机器学习——K近邻算法(KNN)及其python实现_清泉_流响的博客-优快云博客_python实现knn
机器学习之KNN算法(python代码实现)_卷不动的程序猿的博客-优快云博客_knn与随机森林对比python代码
k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。
k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。k近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。k值的选择、距离度量及分类决策规则是k近邻法的三个基本要素。
此时K=3,待确定的样本寻找离它最近的三个样本
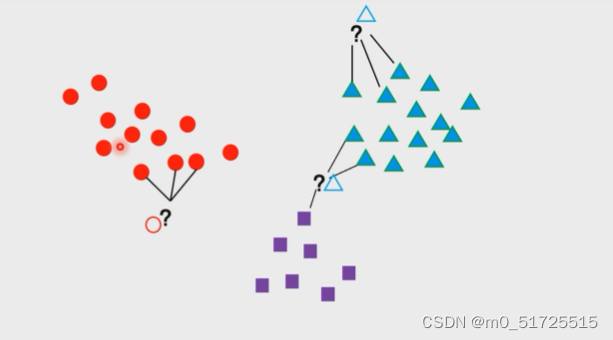
kNN(k-Nearest Neighbors,k近邻)是机器学习中非常基础的一种算法,算法原理简单而且容易实现,结果精度高,无需估计参数,无需训练模型,而且不仅可以用于分类任务,还可以应用到回归问题。作为开始学习机器学习的入门是一个很好的选择。
俗话说:近朱者赤,近墨者黑,物以类聚,人以群分。KNN算法就是这样。它使相同类别的样本在特征空间中聚集在一起。
分类时一般采用多数表决投票法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。
简单来说就是计算输入数据D与所有样本点的距离,然后取最小的前k个样本的标签的统计即可。
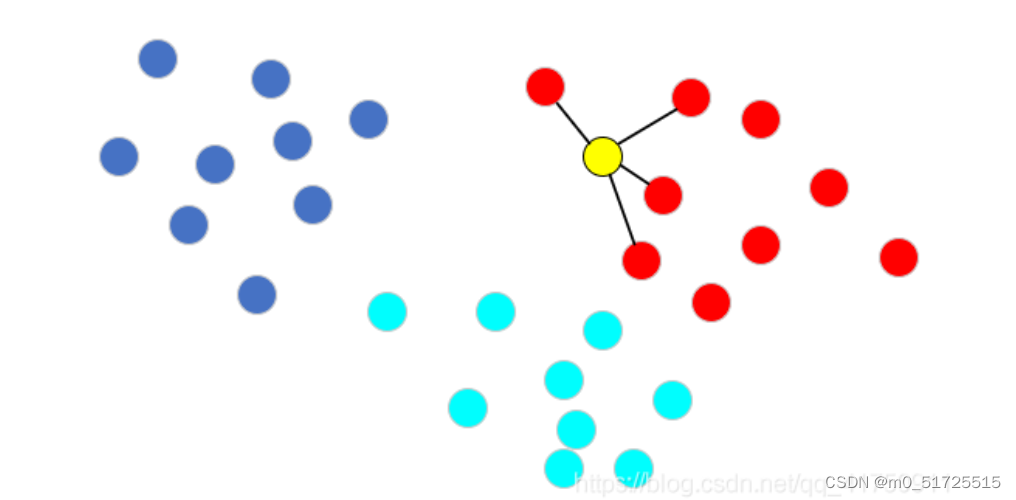
如下图,现在有三种颜色的点分布在二维空间中,对应了分类任务中的训练样点的三个类别。现在我们希望推测图中黄色圆的那个点是属于那个类别,那么knn算法将计算该点与所有训练样点之间的距离,并且挑选出距离最小的k个样点(此处k=4,根据实际需要自定义),那么黄色点的类别将通过图中连接的4个点来判断。很明显,这4个点均为红色类别,那么黄色点被推测为红色类别。
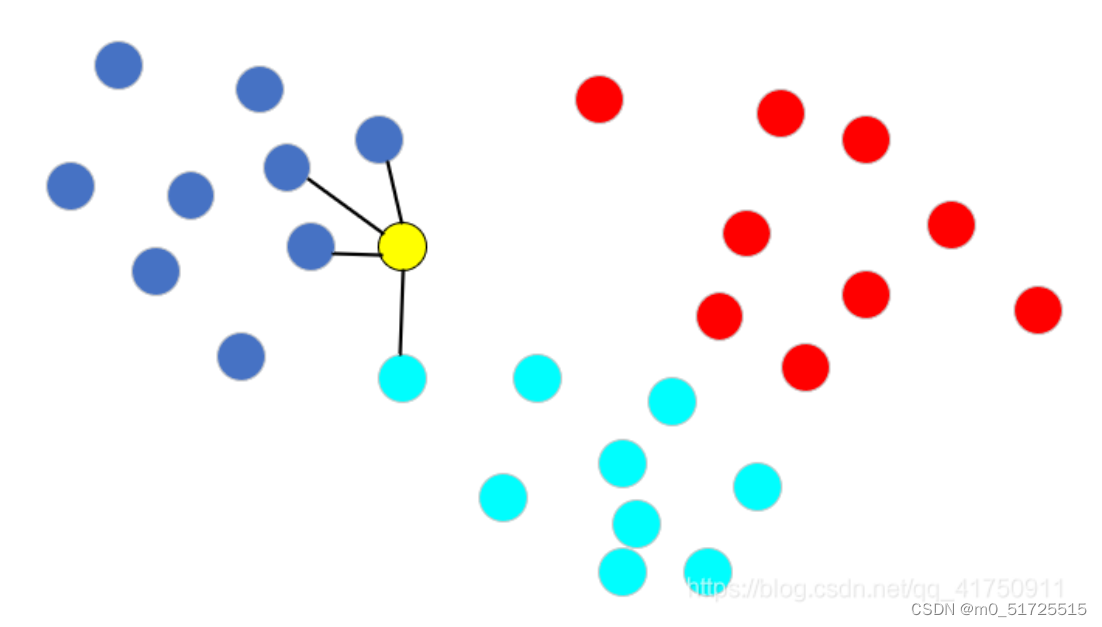
同理,再看下图所示,此时这4个样本点包含了2个类别,针对这样的情况,knn算法通常采用投票法来进行类别推测,即找出k个样本点中类别出现次数最多的那个类别,因此黄色点的类型被推测为蓝色类别。
KNN算法的主要实现步骤:
- 计算测试数据与各训练数据之间的距离。
- 按照距离的大小进行排序。
- 选择其中距离最小的k个样本点。
- 确定K个样本点所在类别的出现频率。
- 返回K个样本点中出现频率最高的类别作为最终的预测分类。
K-Means与KNN
初学者很容易把K-Means和KNN搞混,两者其实差别还是很大的。
K-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。
当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻(nearest neighbors)的思想。

















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









