











数据的增加
- 按列增加数据
- 按行增加数据
- 增加多行数据
修改数据
- 修改列标题
- 使用DataFrame对象的columns属性直接赋值
- 使用DataFrame对象的rename方法修改列标题
- 修改行标题
- 使用DataFrame对象的index属性
- 修改数据
- 使用DataFrame对象的loc属性和iloc属性
删除数据
- 使用DataFrame对象中的drop()方法
-
df.drop(labels, axis, index, columns, inplace) # 参数说明 # labels:表示行标签或者列标签 # axis: axis=0表示按行删除,axis=1表示按列删除 # index:删除行,默认值为None # columns:删除列,默认值为None # inplace: 对原数组做出修改并返回一个新数组。默认值为False,如果值为True,那么原数组直接就被替换
数据的增加:
先创建一个表格:
import pandas as pd
data = [[45,65,200],[56,45,50],[67,67,67]]
index = ['Tom','Jack','Alice']
columns = ['math','Chinese','english']
df = pd.DataFrame(data = data, index = index, columns= columns)

-
按列增加数据
1.采用直接赋值的方式增加列数据
df['politics'] = [90,89,100] 
2.使用loc属性在DataFrame的最后一列增加
df.loc[:,'chemistry'] = [100,68,80] 
3.在指定的索引上进行插入一列
insert()函数:
insert(loc, column, value, allow_duplicates=False)
loc: int型,表示第几列;若在第一列插入数据,则 loc=0
column: 给插入的列取名,如 column='新的一列'
value:数字,array,series等
allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复。
lst = [100,90,82]
df.insert(1,'history',lst)

-
按行增加数据
1.直接增加
df.loc['Ben'] = [15,56,99] 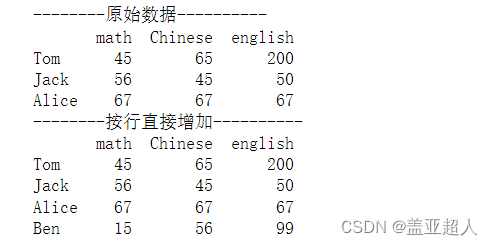
-
增加多行数据
新建一个DataFrame
new_df = pd.DataFrame(
data = {'math':[67,88],'Chinese':[88,65],'english':[75,66]},index = ['Jacy','Peter']
)
df = df.append(new_df) 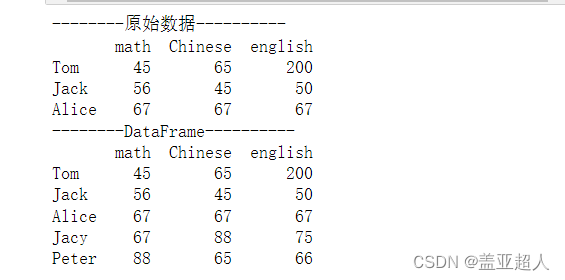
修改数据
-
修改列标题
使用DataFrame对象的columns属性直接赋值
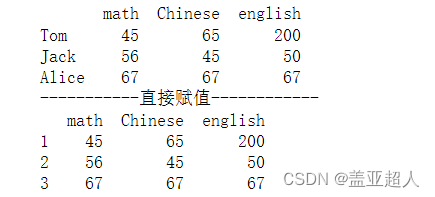
print('-----------直接赋值------------')
df.index=list('123')
print(df)
使用DataFrame对象的rename方法修改列标题
df.rename({'1':'一','2':'二','3':'三'},inplace = True,axis = 0)
print(df)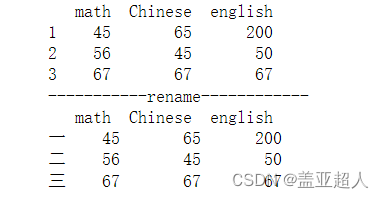
-
修改行标题
使用DataFrame对象的index属性
# 修改数据
# import pandas as pd
# data = [[45,65,200],[56,45,50],[67,67,67]]
# index = ['Tom','Jack','Alice']
# columns = ['math','Chinese','english']
# df = pd.DataFrame(data = data, index = index, columns= columns)
# print(df)
print('--------修改一整行--------')
df.loc['张三'] = [100,100,100]
print(df)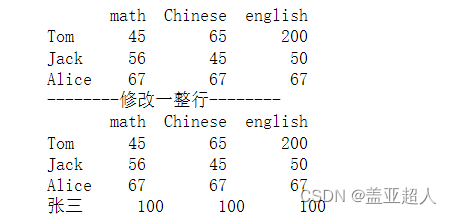
-
修改数据
使用DataFrame对象的loc属性和iloc属性
print('--------修改0行的所有列--------')
df.iloc[0,:]=[90,90,90]
print(df)
print('--------修改列--------')
df.loc[:,'math']=[55,55,55,66]
print(df)
df.iloc[:,1] = [100,100,100,100]
print(df)
df.loc['Tom','Chinese']=6
print(df) 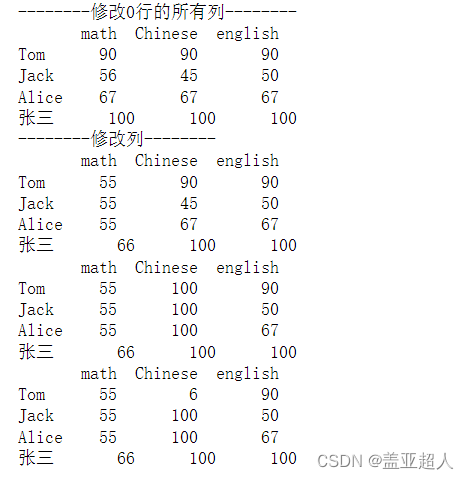
删除数据
使用DataFrame对象中的drop()方法

删除math列(三种方法)
df.drop(['math'],axis=1,inplace=True)
df.drop(columns='math',axis=1,inplace=True)
df.drop(labels='math',axis=1,inplace=True) 
删除行(三种方法)
# 删除行
df.drop(['Tom'],axis=0,inplace=True)
df.drop(columns='Tom',axis=0,inplace=True)
df.drop(labels='Tom',axis=0,inplace=True)
带条件删除
# 带条件的删除
# print(df[df['math']<60].index[0])
df.drop(df[(df['math']<60)].index,inplace=True) # 删除math分数小于60的行
print(df)
--------------------------菜鸟初上路,请各位大佬多多指教------------------------------
---------------------------------------OK,到这见底了----------------------------------------

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









