






1.论文启发点详细内容(文+图)
1.1介绍

图1:GOOD与不同基线的比较。第一列中的图像来自ADE20K的验证集(周等人,2019)。从第二列到第四列,我们展示了三种开放世界物体检测方法的检测结果:OLN 、GGN 和我们的几何引导开放世界物体检测器 (GOOD)。所示检测结果为每种方法前 100 个提案中的真阳性提案。真正的积极提案或真实对象的数量用括号表示。所有模型都是在COCO数据集的PASCAL-VOC类的RGB图像上训练的(Lin等人,2014),其中不包括房屋,树木或厨房家具。OLN 和 GGN 都无法检测到许多在训练期间未看到的物体。GOOD通过利用几何线索更好地推广到看不见的类别。
当前目标检测器在开放世界环境中失败的一个原因是,在训练期间,它们会因在背景检测到未标记的物体而受到惩罚,因此不鼓励检测它们。受此启发,以前的工作设计了不同的架构(OLN——Learning Open-World Object Proposals without Learning to Classify——2021; Extending one-stage detection with open-world proposals——2022 ,甚至包括unsniffer——2023)和培训管道 pipelines (Learning to Detect Every Thing in an Open World——2021 ;GGN——Open-world instance segmentation: Exploiting pseudo ground truth from learned pairwise affinity——2022 ),以避免抑制背景中未注释的对象,这导致了显着的性能改进。然而,这些方法仍然受到培训课程过度拟合的影响。它们仅在RGB图像上进行训练,主要依靠外观线索来检测新类别的物体,并且很难推广到外观新颖的物体。
此外,在RGB图像训练方面也存在已知的捷径学习问题 short-cut learning problems (Imagenet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness——2019) (Shortcut learning in deep neural networks——2020)(Counterfactual generative networks—— 2021) – 在训练过程中对已知类的纹理或判别部分进行过度拟合没有限制。
在这项工作中,我们建议通过结合通用单目估计器从RGB图像中提取的几何线索来应对这一挑战。我们发现,在具有挑战性的基准测试中,这些线索显着提高了对新对象类别的检测召回率。
长期以来,从单个RGB图像中估计深度和法线等几何线索一直是一个活跃的研究领域。这种中级表示对许多变化(例如亮度、颜色)具有内置的不变性,并且比 RGB 信号更不受类限制,请参见图 2。换句话说,已知物体和未知物体在几何线索方面的差异较小。近年来,由于更强大的架构和更大的数据集(Vision transformers for dense prediction——2021b; Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer——2022;Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans.,2021 年),中级表示的单眼估计器在预测质量和对新场景的泛化方面取得了显着进步。当在新数据集上用作现成的预训练模型时,这些模型能够有效地计算高质量的几何线索。因此,人们很自然地会问,这些模型是否可以为当前基于RGB的开放世界物体检测器提供额外的知识,以克服泛化问题。
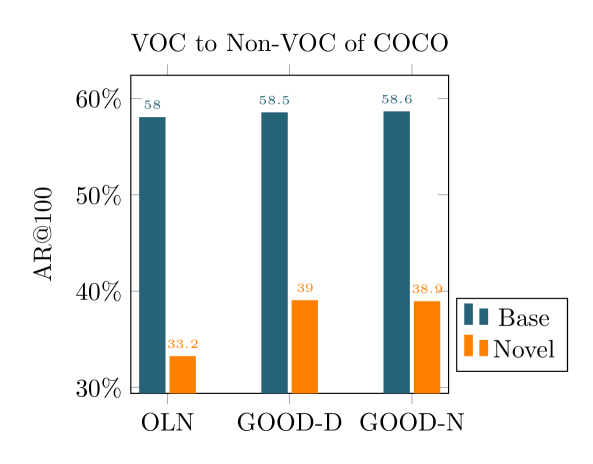

图 2:几何提示与对象定位的外观提示相辅相成。RGB图像的深度和法线线索是使用现成的通用单目预测器提取的。左图:几何提示抽象出外观细节,专注于更全面的信息,例如物体形状和相对空间位置(深度)和方向变化(法线)。右图:通过结合几何线索,GOOD比基于RGB的OLN模型具有更好的泛化性,即基础类和新类之间的AR差距要小得多。
在本文中,我们建议使用一种伪标记方法将几何线索整合到开放世界的目标检测器训练中。我们首先在预测的深度或法线图上训练一个对象建议网络,以在训练集中发现新的未注释对象。排名靠前的新物体预测被用作伪盒子( pseudo boxes ),用于在原始RGB输入上训练开放世界物体检测器。我们观察到,结合几何线索可以显着提高对看不见物体的检测回忆,尤其是那些与训练对象截然不同的物体,如图 1 和图 2 所示。我们推测,这是由于几何线索和基于RGB的检测线索的互补性:几何线索有助于发现基于RGB的检测器无法检测到的新颖物体,并且基于RGB的检测器可以利用更多的注释,其强大的表示学习能力可以推广到新的,看不见的类别。
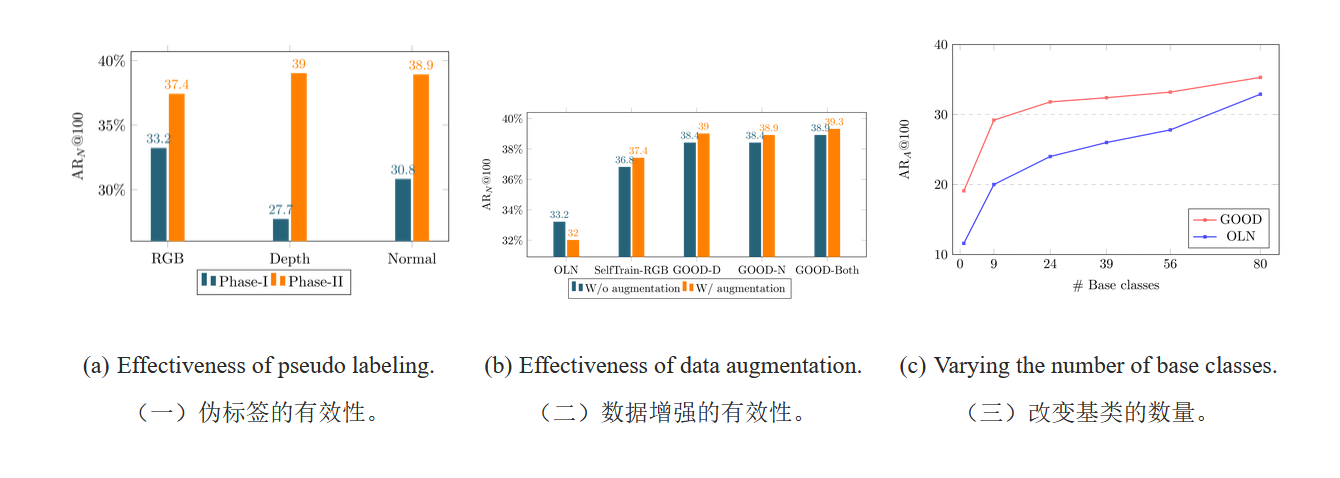
我们最终的几何引导开放世界目标检测器(GOOD)在多个基准测试中超越了与开放世界类无关的对象检测的最新性能。由于丰富的几何信息,GOOD可以推广到看不见的类别,只有几个已知的类进行训练。特别是,在COCO数据集上使用单个训练类“人”(Lin等人,2014),GOOD在检测非人类对象方面可以比SOTA方法高出5.0%AR@100(相对提高24%)。GOOD有20个PASCAL-VOC类进行训练,在检测非VOC类方面,AR@100比SOTA方法高出6.1%。此外,我们还分析了几何线索的优势,并表明它们对跨类的语义变化不太敏感,并且优于其他提高泛化的策略。
问题:只比较了AR,也就是说,只是以召回率作为条件,参考unsniffer,可以认为其用足够多的框把所有物体包住了。接下来我们继续看其准确率如何。
1.2相关工作
与类无关的开放世界检测方法
与类无关的开放世界对象检测是通过仅使用有限数量的对象类(基类)进行学习来定位图像中所有对象的任务。标准对象检测训练的核心问题是,模型被训练为将未注释的对象分类为背景,因此在推理时被抑制以检测它们。为了解决这个问题,Kim等人(2021)提出了对象定位网络(OLN),该网络将Faster RCNN(任等人,2015)的分类头替换为与类无关的对象头,以便仅在正样本(即已知对象)上计算训练损失,从而不抑制对未注释的新对象的检测。
Saito 等人 ( 2021) 通过将已知对象复制粘贴到合成背景上来合成训练集。然而,该模型在求解目标检测任务时遇到了合成域与真实域之间的差距。
除了背景非抑制之外,一种更主动的方法是利用未注释的对象进行训练。Wang 等人 ( 2022) 建立在传统的无学习方法的基础上,开发了一种成对亲和力预测器来发现未注释的对象。然后,使用新发现的对象掩码和真实基类注释作为监督来训练他们的对象检测器 GGN。
最后,另一个有前途的方向是使用来自大型预训练多模态模型的开放世界知识。最近,Minderer 等人( 2022);Maaz 等人(2022 年)利用预训练的语言视觉模型(Radford 等人,2021 年)使用文本查询检测开放世界对象。
我们的工作与OLN和GGN最相关。我们使用了 OLN 架构和训练损失,但还通过我们的伪标记方法合并了几何线索。 GGN 使用成对亲和力进行伪标记。然而,由于成对亲和力是使用基类注解在RGB输入上训练的,因此GGN仍然存在基于RGB的方法的过拟合问题。我们的实验表明,几何线索是伪盒子的更好来源。
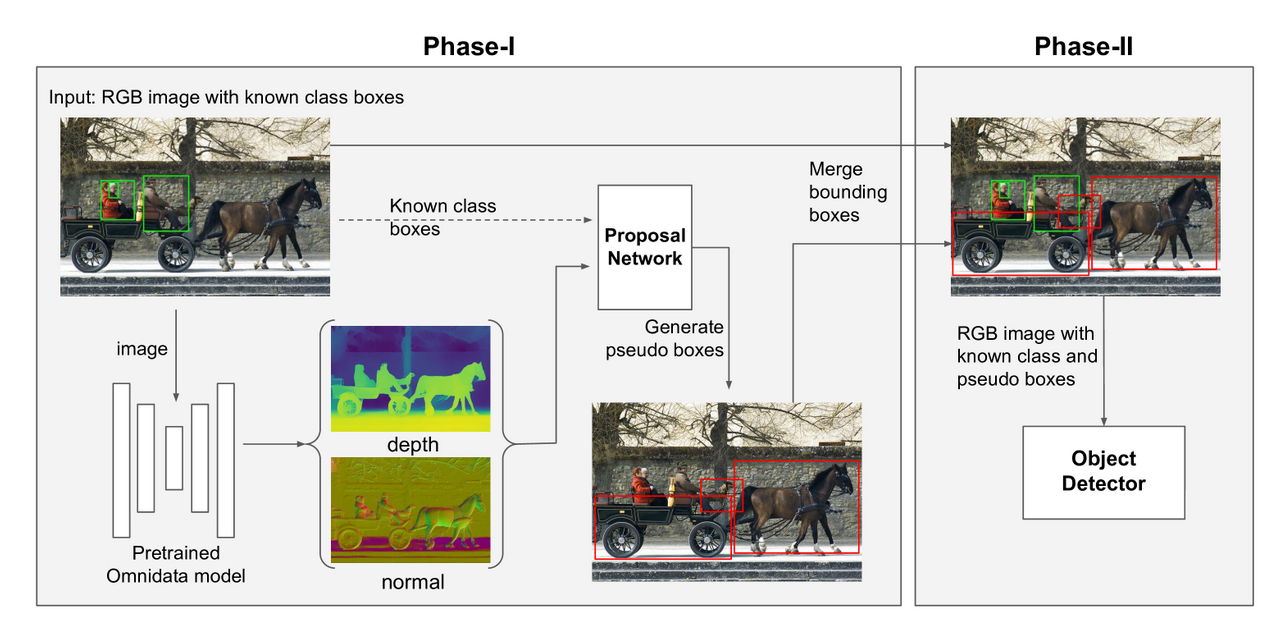
图 3:几何引导伪标记方法概述。它由两个培训阶段组成。第一阶段:RGB输入首先由现成的模型进行预处理,以提取几何提示,然后用于训练具有基类边界框注释的对象建议网络。然后,提案网络对训练样本进行伪标记,发现未注释的新对象。排名靠前的伪框被添加到注释池中,用于第二阶段训练,即使用基类和伪注释直接在 RGB 输入上训练与类无关的对象检测器。在推理时,我们只需要第二阶段的模型。
1.3方法
我们的目标是整合几何线索,以提高开放世界与类无关的对象检测性能。具体来说,我们提出了一种伪标记方法,该方法可以有效地利用几何线索来检测训练集中未注释的新对象,然后将它们用于训练目标检测器。请参阅图 3 中我们方法的概述
开放世界与类无关的目标检测问题(其实就是开放集问题)
目前最先进的物体检测方法在封闭世界假设下效果很好。它们使用 {
ti
} 预先指定的语义类列表 𝒦 (即基类)中的一组对象边界框注释进行训练。在测试时,通过检测已知基类中的对象来评估它们的泛化性。图像 ℐ 目标检测的标准训练损失分为两部分:
分类损失Lcls和边界框回归损失Lreg
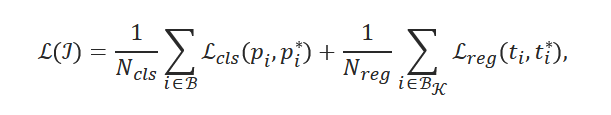
其中 i 是候选集中 ℬ 的锚点的索引, {pi,ti} 是预测的标签和边界框坐标, {pi*,ti*}是 相应的真值。 Ncls 是候选集中 ℬ 的锚点总数。 Nreg 是子集 ℬ𝒦 的大小,它只包含带有真值标签 pi*=1 的锚点。 注意仅当锚点 i可以关联到已知类 𝒦 中的带注释的对象边界框时锚点 pi* =1 ;否则它等于 0 (认为是背景background)。
从封闭世界到开放世界设置,泛化目标延伸到定位图像中的每个对象,这些对象可能属于未知的新颖类 u∈𝒰 。在(1)中的训练损失下,未注释的对象将被归类为“背景”。因此,该模型会在推理时将相似类型的对象视为“背景”。为了避免抑制背景对新物体的检测,OLN提出将(1)中的分类损失替换为对象性得分预测损失,得到
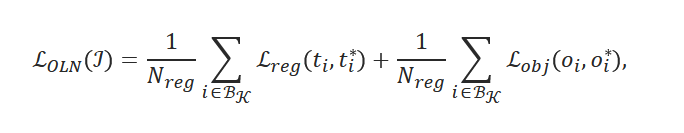
其中 oi 和 oi* 是预测的客体性得分及其锚点的真实值 ground truth of anchor i 。这样一来,只有锚框 pi*=1 参与训练,完全消除了任何“背景”预测。在推理时,对象性分数用于对检测进行排名。但是,由于这些定位点仅从基类中捕获带注释的对象,因此这种损失修改无法有效地缓解对基类的过度拟合。我们进一步求助于在训练中添加额外的“对象”,尤其是外观与基类中的对象截然不同的新对象。
利用几何线索
在RGB图像上训练的模型往往过度依赖外观线索进行对象检测。因此,它们很难检测到与基类截然不同的新对象。例如,在汽车上训练的模型可能会检测到卡车,但不太可能同时检测到三明治。因此,将这些新颖的物体(例如食物)纳入训练是减轻对基类(例如车辆)的外观偏见的有效方法。
为此,我们利用两种类型的几何线索,即深度和法线,来检测训练集中未注释的新对象,参见图 2 中的一些示例。它们都是捕获局部信息的常见几何线索。深度侧重于对象的相对空间差异,并抽象出对象表面上的细节。曲面法线侧重于方向差,在平面上保持不变。与原始RGB图像相比,它们丢弃了大部分外观细节,而专注于几何信息,例如物体形状和相对空间位置。因此,用它们训练的模型可以发现许多基于RGB的模型无法检测到的新颖物体。
我们使用现成的预训练模型来提取几何线索。具体来说,我们使用使用跨任务一致性(Robust learning through cross-task consistency,Zamir 等人,2020 年)和 2D/3D 数据增强(3d common corruptions and data augmentation,Kar 等人,2022 年)训练的 Omnidata 模型(3d common corruptions and data augmentation,Eftekhar 等人,2021 年)。模型的训练数据集是 Omnidata Starter 数据集 (OSD),其中包含 2200 个真实和渲染的场景。尽管 OSD 与目标检测基准数据集之间存在差异,但 Omnidata 模型可以产生高质量的结果,这意味着这些几何线索背后的不变性是稳健的。
伪标签法
为了使用几何线索在训练集中发现未注释的新对象,我们首先使用与OLN中相同的训练损失
LOLN
(即图3中的第一阶段训练)在深度或法线输入上训练对象建议网络。然后,该对象建议网络将使用其检测到的边界框对训练图像进行伪标记。
在过滤掉检测到的与基类注释重叠的边界框后,我们将剩余的top-k 框添加到真值注释中。这是 k∈{1,2,3} 在小型维持验证集上为每个检测器确定的。最后,我们使用RGB图像作为输入,将扩展的边界框注释池作为真实值,即图3中的Phase-II,训练一个新的与类无关的目标检测器。训练损失为
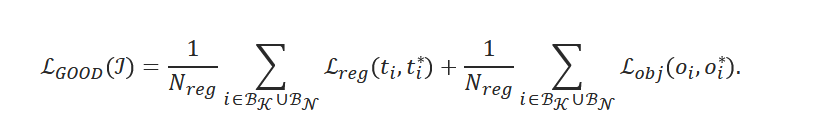
与
LOLN
相比,与检测到的新物体的伪框重叠的锚点,即 i∈ℬ𝒩 ,也参与训练。伪框可以从单一来源(即其中一个几何线索)和两者(即伪标签组合)获取。我们命名我们的方法 GOOD - X 当使用特定的几何线索 X 作为伪标签源时,而 GOOD - Both 代表从深度和法线中嵌入伪标签。
受到以前在自我训练方面的工作启发(Self-training with noisy student improves imagenet classification.Xie et al., 2020; Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Sohn 等人,2020 年; End-to-end semi-supervised object detection with soft teacher,Xu et al., 2021),我们在第二阶段使用强大的数据增强来抵消伪盒子中的噪声,并进一步提高 GOOD 的性能。具体来说,对于第二阶段训练,我们使用 AutoAugment(Autoaugment: Learning augmentation strategies from data,Cubuk 等人,2019 年),其中包括随机调整大小、翻转和裁剪。
几何提示的优点
几何线索对不同类别的外观变化不太敏感。我们首先比较了在几何线索上训练的对象建议网络与在RGB图像上训练的对象建议网络的每新颖类AR@5。在这里,AR@5很有意思,因为在第一阶段使用几何线索来发现看起来很新的物体,并且在第二阶段中,每个图像将使用不超过五个伪框,见图3。(???)
图 4 显示,在许多类别中,几何提示可以实现比 RGB 高得多的per-novel-class AR@5。一个例子是新颖的超类别“食物”,包括“热狗”和“三明治”等类别。属于超类别“人”、“动物”、“车辆”和“室内”的基类与“食物”超类别的外观截然不同。基于RGB的模型很难使用外观线索来检测食物。相比之下,几何线索可以跨超类别进行推广。对于几何线索比 RGB 差的类别,我们发现它们通常尺寸较小,例如刀、叉和时钟。这表明,在抽象掉外观细节的同时,几何线索也可能丢失一些关于小物体的信息。这再次显示了RGB和几何线索的互补性。
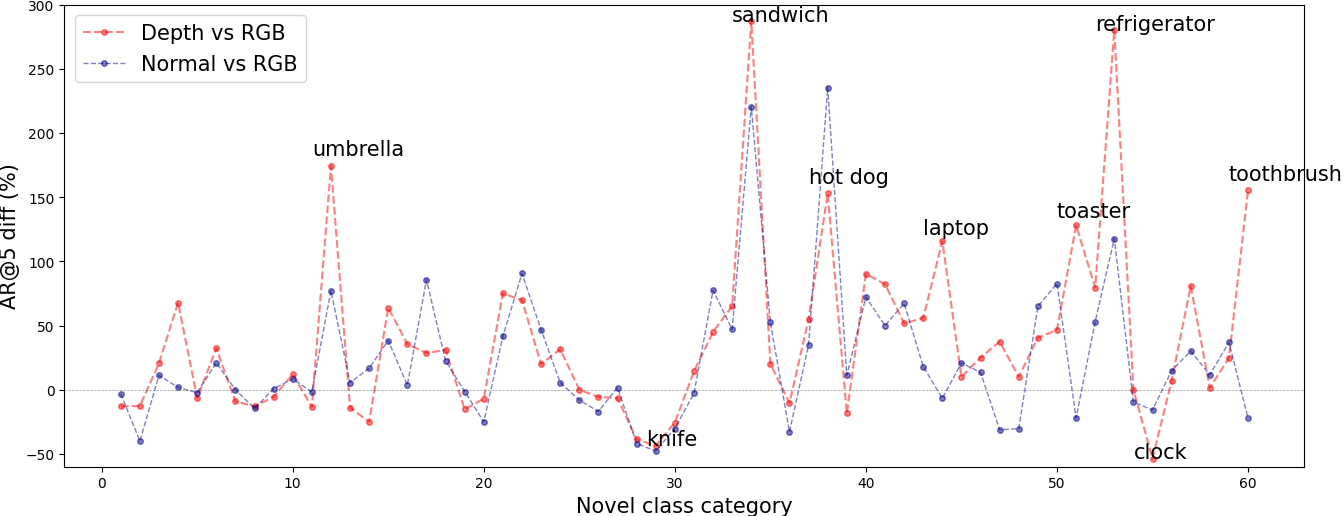
图4:COCO VOC → Non-VOC上伪盒的每类AR@5差异比较。我们在几何线索(图 3 中的第一阶段)上训练对象建议网络,并直接在 RGB 图像上训练。我们显示了它们per-novel-class AR@5差异,其定义为
(ARX−ARRGB)/ARRGB
X∈{Depth,Normal}
。几何提示在零差分线( zero difference line )以上的那些类上优于 RGB 图像。我们还重点介绍了一些 RGB 和几何提示有很大差异的类。
几何提示比边缘和成对亲和力更好。Geometric cues are better than edges and pairwise affinities.
结论
在本文中,我们提出了一种GOOD方法来解决开放世界与类无关的目标检测这一具有挑战性的问题。它利用易于获取的几何线索(如深度和法线)来检测训练集中未注释的新对象。由于几何线索侧重于物体形状和相对空间位置而不是外观,因此它们可以检测到基于RGB的方法无法检测到的新物体。通过进一步将这些新对象纳入基于RGB的目标检测器训练中,GOOD在跨类别和数据集中展示了强大的泛化性能。
2.论文摘要
我们解决了开放世界与类无关的对象检测的任务,即通过从有限数量的基本对象类中学习来检测图像中的每个对象。最先进的基于RGB的模型在训练类中存在过度拟合的问题,并且经常无法检测出外观新颖的物体。这是因为基于RGB的模型主要依靠外观相似性来检测新奇的物体,并且还容易过度拟合纹理和判别部分等快捷线索。为了解决基于RGB的目标检测器的这些缺点,我们建议结合由通用单目估计器预测的深度和法线等几何线索。具体来说,我们使用几何线索来训练对象提案网络 object proposal network ,用于伪标记训练集中未注释的新对象。我们由此产生的几何引导开放世界目标检测器(GOOD)显著提高了对新目标类别的检测召回率,并且仅在少数培训课程中就已经表现良好。在COCO数据集上使用单个“人员”类进行训练,GOOD比SOTA方法高出5.0%AR@100,相对提高了24%。

3.与启发点相关内容
论文原文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









