






一、Excel
- 在Excel里,时间就是一个数字序号,代表自从1900年1月0日以来的天数。序列号1对应于1900年1月1日,序列号2对应于1900 年1月2日,依此类推。与日期序列号相似,时间也有序列号。当需要处理时间值时,只需扩展Excel日期序列号系统以包括小数即可。换句话说,Excel使用小数的天来处理时间。例如,2007年6月1日的日期序列号是39234,中午(一天的一半)在内部以39234.5 表示。与一分钟等价的序列号大约是0.00069444,所以在Excel里要表示分钟或秒时,用文本格式,否则有些时间点Excel会将分钟、秒转换为小数(单位:秒),这时将秒数转为LocalDateTime时就和实际时间有误差,比如Excel里指定时间:2023/10/25 12:05 时,会转换为2023-10-25 12:04:59,是由于小数的四舍五入造成的
-
当是多级表头时,且最下一层级表头字段名称有重复,因此需要指定字段下标序号才能成功读取到值,否则值会赋值到最后1个重名的字段。同时读取时要指定表头行数。上例如:
@ApiModelProperty("项目1名称") @ExcelProperty(value = {"项目1", "名称"},index = 7) private String project1Name; @ApiModelProperty("项目1分数") @ExcelProperty(value = {"项目1", "分数"},index = 8) @TableField(exist = false) private String project1ScoreStr; private BigDecimal project1Score; @ApiModelProperty("项目2名称") @ExcelProperty(value = {"项目2", "名称"},index = 9) private String project2Name; @ApiModelProperty("项目2分数") @ExcelProperty(value = {"项目2", "分数"},index = 10) @TableField(exist = false) private String project2ScoreStr; private BigDecimal project2Score; - ...
二、Mybatis
- 若实体里的List<?>里的泛型为String,则resultMap里的collection中应这样写
<resultMap id="xx" type="org.xxxx"> <id column="lectureCategory" property="lectureCategory"/> <result column="lecturerStarRating" property="lecturerStarRating"/> <collection property="lectureList" ofType="String"> <id column="lecture_name"/> </collection> </resultMap> - 当分页数据对应的实体里的字段需要用到List<?>时,如果直接用MybatisPlus的<collection>标签进行集合映射会导致分页查询到的条数比预期的要多,这是因为sql中left join1对多了,也被统计在内了。若要解决此问题可使用<collection>标签的子查询,这样统计的是left join左边表的行数,统计完毕后在根据坐表的某个列作为关联条件进行子查询。实例:
<resultMap id="pageDetailMap" type="xx.xx.dto.dailysalary.ApprenticeDailySalaryDetail"> <id property="jobNo" column="job_no"/> <result property="regionCode" column="region_code"/> <result property="regionName" column="region_name"/> <collection property="leaveBillDateTimeList" ofType="xx.xx.dto.dailysalary.DailySalaryCheckDetailVO$LeaveDateTime" select="pageDetail_sub_query" column="jobNo=job_no"> <id column="billNo" property="billNo"/> <result column="starDateTime" property="starDateTime"/> <result column="endDateTime" property="endDateTime"/> </collection> </resultMap> <!-- 主查询--> <select id="pageDetail" resultMap="pageDetailMap"> dailySalary.region_code, dailySalary.region_name, dailySalary.job_no from apprentice_daily_salary dailySalary where dailySalary.is_deleted = 0 </select> <!-- 子查询:通过collection标签里的column将主查询的关联字段值传给子查询,语法column"{子查询所需参数名1=主查询列名1,子查询所需参数名2=主查询列名2}"--> <select id="pageDetail_sub_query" resultType="xx.xx.dto.dailysalary.DailySalaryCheckDetailVO$LeaveDateTime"> select isnull(t1.BillNO, t2.BillNO) as billNo, isnull(t1.StartDate, t2.XStarDate) AS starDateTime, isnull(t1.EndDate, t2.XEndDate) AS endDateTime from Leave t1 left join Leave t2 on t2.Cancel = 0 and t1.BillNO = t2.LeaveBill where t1.Cancel = 0 and t1.JobNo = #{jobNo} </select>然后再聚合项目顶层pom中:
<dependencyManagement> <dependencies> <dependency> <groupId>com.jlcx.qd</groupId> <artifactId>inf-bom</artifactId> <version>${version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> ... </dependency> </dependencies> </dependencyManagement>在需要使用相关JAR包的pom.xml文件中正常引入依赖就行,若需要使用不同的版本则同时添加<version>即可。本质就是:引入的info-bom其实引入的是一些版本锁定内容,和SpringCloud的版本管理如出一辙。参考自:
- MybatisPlus配置分页插件后,分页count相关的优化配置是开启的(比optimizeCountSql),而分页前需要统计行数,此时如果MybatisPlus内使用的JSqlParser对SQL解析成功时,就会将SQL的select中的字段用count(*)替换并去掉排序进行优化,失败时(若mybatisplus使用的此依赖的版本和数据库对应不上时就有可能出现某些语法解析失败)就打印解析失败日志并使用原SQL。当使用的是SqlServer数据库进行分页查询时且需要排序时,如果由于SqlServer语法中的"["等其他关键字等因素导致JSqlParser解析失败时会用select count(*) from (原SQL),这就导致from后的原SQL变成了子查询且排了序,而SqlServer子查询里排序必须加上top 100 percent,但还可能不管用。此时我们可以通过mybatisplus提供的Page对象里的countId字段指定一个mapper接口来用于统计行数,然后原来自己写的SQL来查数据。
package com.baomidou.mybatisplus.extension.plugins.inner; /** * 分页拦截器 * <p> * 默认对 left join 进行优化,虽然能优化count,但是加上分页的话如果1对多本身结果条数就是不正确的 * * @author hubin * @since 3.4.0 */ @Data @NoArgsConstructor @SuppressWarnings({"rawtypes"}) public class PaginationInnerInterceptor implements InnerInterceptor { /** * 获取自动优化的 countSql * * @param page 参数 * @param sql sql * @return countSql */ protected String autoCountSql(IPage<?> page, String sql) { if (!page.optimizeCountSql()) { return lowLevelCountSql(sql); } try { Select select = (Select) CCJSqlParserUtil.parse(sql); SelectBody selectBody = select.getSelectBody(); // https://github.com/baomidou/mybatis-plus/issues/3920 分页增加union语法支持 if (selectBody instanceof SetOperationList) { return lowLevelCountSql(sql); } PlainSelect plainSelect = (PlainSelect) select.getSelectBody(); Distinct distinct = plainSelect.getDistinct(); GroupByElement groupBy = plainSelect.getGroupBy(); List<OrderByElement> orderBy = plainSelect.getOrderByElements(); if (CollectionUtils.isNotEmpty(orderBy)) { boolean canClean = true; if (groupBy != null) { // 包含groupBy 不去除orderBy canClean = false; } if (canClean) { for (OrderByElement order : orderBy) { // order by 里带参数,不去除order by Expression expression = order.getExpression(); if (!(expression instanceof Column) && expression.toString().contains(StringPool.QUESTION_MARK)) { canClean = false; break; } } } //优化: 判断排序字段不会对分页行数造成影响时去掉排序 if (canClean) { plainSelect.setOrderByElements(null); } } //#95 Github, selectItems contains #{} ${}, which will be translated to ?, and it may be in a function: power(#{myInt},2) for (SelectItem item : plainSelect.getSelectItems()) { if (item.toString().contains(StringPool.QUESTION_MARK)) { return lowLevelCountSql(select.toString()); } } // 包含 distinct、groupBy不优化 if (distinct != null || null != groupBy) { return lowLevelCountSql(select.toString()); } // 包含 join 连表,进行判断是否移除 join 连表 if (optimizeJoin && page.optimizeJoinOfCountSql()) { List<Join> joins = plainSelect.getJoins(); if (CollectionUtils.isNotEmpty(joins)) { boolean canRemoveJoin = true; String whereS = Optional.ofNullable(plainSelect.getWhere()).map(Expression::toString).orElse(StringPool.EMPTY); // 不区分大小写 whereS = whereS.toLowerCase(); for (Join join : joins) { if (!join.isLeft()) { canRemoveJoin = false; break; } FromItem rightItem = join.getRightItem(); String str = ""; if (rightItem instanceof Table) { Table table = (Table) rightItem; str = Optional.ofNullable(table.getAlias()).map(Alias::getName).orElse(table.getName()) + StringPool.DOT; } else if (rightItem instanceof SubSelect) { SubSelect subSelect = (SubSelect) rightItem; /* 如果 left join 是子查询,并且子查询里包含 ?(代表有入参) 或者 where 条件里包含使用 join 的表的字段作条件,就不移除 join */ if (subSelect.toString().contains(StringPool.QUESTION_MARK)) { canRemoveJoin = false; break; } str = subSelect.getAlias().getName() + StringPool.DOT; } // 不区分大小写 str = str.toLowerCase(); if (whereS.contains(str)) { /* 如果 where 条件里包含使用 join 的表的字段作条件,就不移除 join */ canRemoveJoin = false; break; } for (Expression expression : join.getOnExpressions()) { if (expression.toString().contains(StringPool.QUESTION_MARK)) { /* 如果 join 里包含 ?(代表有入参) 就不移除 join */ canRemoveJoin = false; break; } } } if (canRemoveJoin) { plainSelect.setJoins(null); } } } // 优化 SQL // COUNT_SELECT_ITEM就是count(*),下边这一步会将select field1,..替换为select count(*) from ... plainSelect.setSelectItems(COUNT_SELECT_ITEM); return select.toString(); } catch (JSQLParserException e) { // 无法优化使用原 SQL logger.warn("optimize this sql to a count sql has exception, sql:\"" + sql + "\", exception:\n" + e.getCause()); } catch (Exception e) { logger.warn("optimize this sql to a count sql has error, sql:\"" + sql + "\", exception:\n" + e); } // 解析失败时使用原SQL,点进去就明白了 return lowLevelCountSql(sql); } /** * 无法进行count优化时,降级使用此方法 * * @param originalSql 原始sql * @return countSql */ protected String lowLevelCountSql(String originalSql) { return SqlParserUtils.getOriginalCountSql(originalSql); } }package com.baomidou.mybatisplus.extension.toolkit; /** * SQL 解析工具类 * * @author hubin * @since 2018-07-22 */ public class SqlParserUtils { /** * 获取 COUNT 原生 SQL 包装 * * @param originalSql ignore * @return ignore */ public static String getOriginalCountSql(String originalSql) { // select后的字段列表、尾部排序都不处理,对原SQL直接包一层统计行数 // SqlServer包一层内部的子查询有排序时会提示让加top,但是有时候加了还是解析失败,这时候可以通过MybatisPlus提供的Page类的countId字段指定一个mapper接口(此接口对应的SQL由于只用返回long类型的总条数,不是分页查询,所以不会进行SQL解析就不会报错,就是个普通的统计查询,想怎么写就怎么写语法和mybatisPlus无关)用以分页的统计行数,然后查询分页的records时还用原来的SQL。 return String.format("SELECT COUNT(*) FROM (%s) TOTAL", originalSql); } }下边是具体解决方案示例:
// Service层分页查询接口 @Override public IPage<ApprenticeDailySalaryDetail> pageDetail(Page<Object> page, PageDetailRequest request) { // 指定具体的count SQL page.setCountId("getPageDetailCount"); IPage<ApprenticeDailySalaryDetail> pageVO = baseMapper.pageDetail(page, request, cn); return pageVO; } // Mapper层对应的两个方法,第一步统计行数,第二部查询分页数据,对用xml中的SQL就不发出来了 Long getPageDetailCount(IPage<Object> page, @Param("request") PageDetailRequest request, @Param("cn") CodeAndNameVO cn); IPage<ApprenticeDailySalaryDetail> pageDetail(Page<Object> page, @Param("request") PageDetailRequest request, @Param("cn") CodeAndNameVO cn); - 从sql到实体的LocalDate等其他日期类型的字段转换时,SQL查出来的数据必须是日期,如果是字符串的话不能转为Java中的日期类型,必须转换
-- apprentice_daily_salary表里的 year、month、day都是int类型,现在要组装成日期转为Java类里的LocalDate(框架里已配置JacksonLocalDate相关的转换配置) -- 如果去掉convert(date,'日期')直接将'日期'与Java实体字段转换这会报错提示不能直接将varchar转为JDBCTYPE LOCALDATETIME select convert(date, concat(dailySalary.year, '-', iif(dailySalary.month < 10, concat('0', dailySalary.month), cast(dailySalary.month AS char(2))), '-', iif(dailySalary.day < 10, concat('0', dailySalary.day), cast(dailySalary.day AS char(2))))) as attendance_date from apprentice_daily_salary dailySalary - 在使用Mybatis进行Insert、Update操作时,若字段值为null,此时会提示奇奇怪怪的转换异常,在指定jdbcType就正常了。原因:
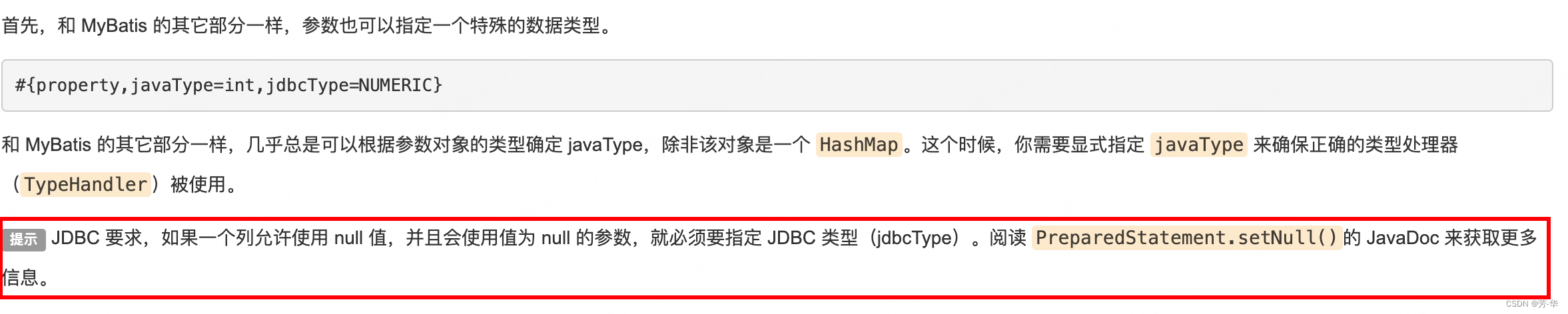
- Mybatis的xml中的SQL查询对应的Java实体中的字段不能是泛型,否则会奇怪的错误,如下就不允许
// mapper接口 List<KeyValueVO<String,List<ManagementPersonalityVO.DimensionMap>>> getInfo(); @Data @ApiModel("键-值实体") public class KeyValueVO<K, V> { @ApiModelProperty("键") private K key; @ApiModelProperty("值") private V value; } - 在使用<collection>、<assocation>两个标签时,如果想要把内部的<id>、<result>提取到外边的<resultMap>实现复用时,需要在这两个标签里指定resultMap=""属性。参考自官方文档
-
<!--不通过前端传参查询,后端逻辑指定,故不存在SQL注入风险,#{}本质是占位符会给表名加单引号导致SQL执行报错,要用${} --> <select id="truncateTable"> truncate table ${tableName} </select> - MyBatis的
<collection>标签通常用于映射单个对象中的集合属性。如果Mapper接口想返回List<User>,User里有List<Book>时,是不能直接通过单纯的1个两表关联的SQL实现的,只能使用<collection>的select属性加上分布查询实现。 - 。。。
三、Maven
- BOM(Bill of Materials)是Mave提供的一种功能,他是一个担任着jar包版本统一管理职责的pom文件。我们通过在其内部声明<dependencyManagement>和<properties>来管理jar版本,然后在一个Maven聚合项目的顶层pom中像引入其他依赖那样使用它。
-
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.ydj.qd</groupId> <artifactId>inf-bom</artifactId> <version>1.0</version> <packaging>pom</packaging> <name>inf-bom</name> <description>第三方jar包统一管理</description> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <spring.version>4.3.15.RELEASE</spring.version> </properties> <dependencyManagement> <dependencies> <!-- 阿里 --> <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.12</version> </dependency> <!-- https://mvnrepository.com/artifact/com.aliyun.mns/aliyun-sdk-mns --> <dependency> <groupId>com.aliyun.mns</groupId> <artifactId>aliyun-sdk-mns</artifactId> <version>1.1.8</version> <classifier>jar-with-dependencies</classifier> </dependency> <!-- Apache --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.3.2</version> </dependency> </dependencies> </dependencyManagement> <build> </build> <distributionManagement> <repository> <id>maven-releases</id> <name>maven-releases</name> <url>http://mvn.ydj.com/repository/maven-releases/</url> </repository> <snapshotRepository> <id>maven-snapshots</id> <name>maven-snapshots</name> <url>http://mvn.ydj.com/repository/maven-snapshots/</url> </snapshotRepository> </distributionManagement> </project> - 。。。

















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









