




文章目录
一、Redis三大缓存问题
1.缓存击穿(一)
触发条件:
一个并发访问量比较大的Key在某个时间过期,导致所有的请求直接打在DB上。
解决方案:
方案一:加锁更新
查询缓存,发现缓存中不存在,加锁让其他线程等待,只让一个线程去更新缓存。
方案二:异步更新
缓存设置为永不过期。通过异步的方式去更新缓存。后台开启另外一个守护线程,让其定时去更新缓存,但是这种实现相对复杂,难以把握。
2.缓存穿透(二)
触发条件:
查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就像缓存不存在一样,失去了缓存保护的作用。
解决方案:
方案一:设置默认值
为该数据设置一个默认值(可以为空值),之后访问缓存的时候,获取到这个默认值就知道数据库中数据为空,间接的保护了数据库。
但是可能会产生部分影响,例如:1.在缓存层保存默认值,又增加了内存消耗。2. 需要给该默认值设置过期时间。3. 因为缓存层和存储层的时间窗口不一致,导致影响业务。(当存储层的数据已经修改之后,但是缓存层的状态还没及时更新,导致在这个时间差内,用户访问不到。)
方案二:添加布隆过滤器
详细介绍见:大数据之布隆过滤器学习
3.缓存雪崩(三)
触发条件:
某一时刻发生大规模的缓存失效的情况,例如缓存服务器宕机、大量key在同一时间过期,这样的后果就是大量的请求直接打到DB上,可能导致整个系统的崩溃,成为雪崩。
解决方案:
方案一:提高缓存可用性
总共有两个思路,第一种是集群部署,避免单一节点出问题,导致整体雪崩。第二个思路是多级部署,不同级别设置不同的过期时间。
方案二:过期时间
两种处理方案:针对热点数据,设置永不过期。对于普通数据,打散过期时间,随机设置不同的key的过期时间。
方案三:熔断降级
两种思路:在服务器当即或者连接超时的情况下,为防止出现雪崩,可以暂时停止业务服务访问缓存系统。或者可以舍弃一些非核心的请求,返回准备好的错误提示。
二、布隆过滤器——BloomFilter
1 BloomFilter的由来
由霍华德.布隆的一个人在70年代提出的一个二进制向量数据结构。它可以帮助我们检测一个元素是否为这个集合中的一员。检测的结果可以100%保证元素一定不在这个集合中,但是不能100%一定在这个集合中。
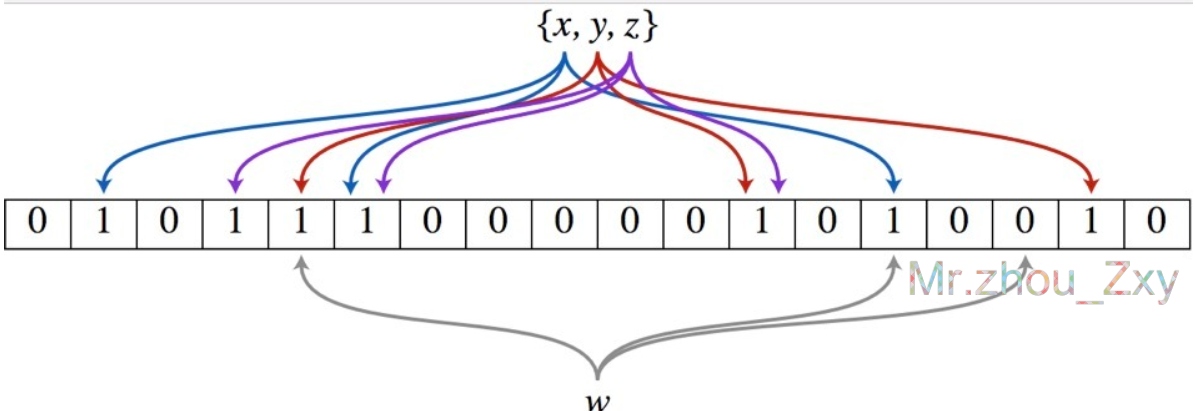
tips:
从容器角度来说:
如果布隆过滤器判断元素在集合中存在,不一定存在
如果布隆过滤器判断不存在,一定不存在
从元素角度来说:
如果元素实际存在,布隆过滤器一定判断存在
如果元素实际不存在,布隆过滤器可能判断存在
2.爬虫
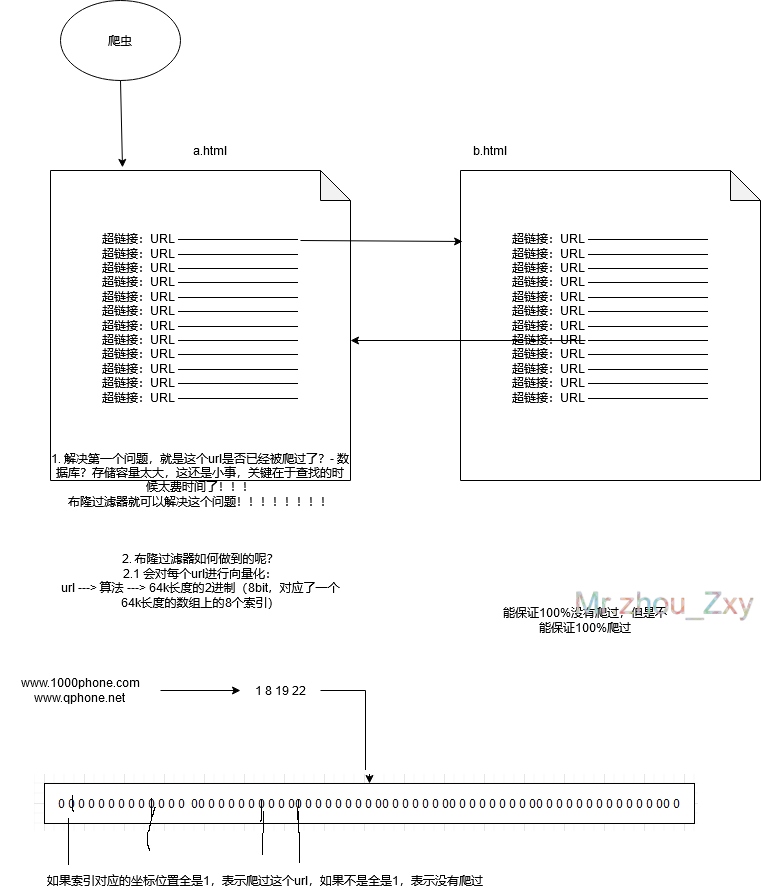
3.在hbase中的应用
作用:能减少get/scan的查询时间。不过它肯定增加集群的负担,在早期的hbase中是默认关闭的。在当前版本中默认实际是开启的。
hbase支持以下的布隆过滤器的类型:
- NONE : 不使用布隆过滤器
- ROW : 行键使用布隆过滤器
- ROWCOL : 行键+列簇使用布隆过滤器
4.缓存穿透
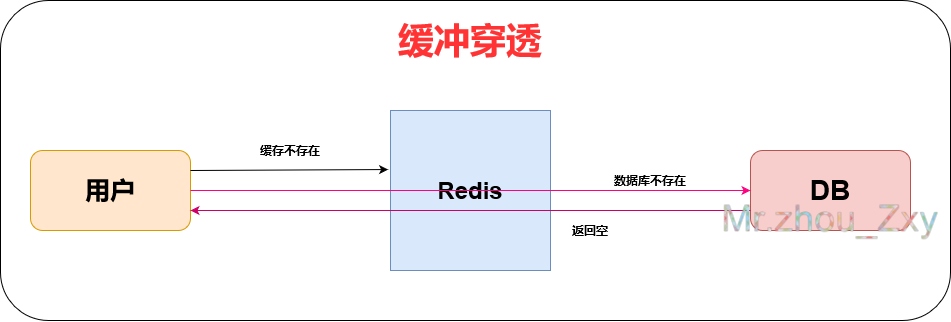
所谓缓冲穿透,就是例如在上图中,用户向Redis请求查询,但是没有查询到。接下来就会去数据库中查询,发现数据库里也没有,返回空。经过多次这样的操作,如果每次查询不到,都要在去数据库中再访问一遍,无疑会给数据库造成很大的压力。这种情况就是属于穿透了。
这时候就需要在Redis中设置一个特殊的标志,当用户访问Redis为空或者访问到这个标志后,就默认数据库中也没有这个数据,也就减少了数据库的压力。
但是有一点要注意,这个访问到特殊标志,就默认数据库没有数据一定要设置存活时间,当数据库中增加信息的时候,一定要让用户可以访问到。
随着数据的增多,特殊标识符的使用显得有点不足,这时候还是布隆过滤器承担重任。
5.布隆过滤器的其他应用场景
- 反垃圾邮件,从数十亿垃圾邮件列表中 判断某邮箱是否是垃圾邮箱
- Google Chrome使用布隆过滤器识别恶意URL
- Medium使用布隆过滤器避免推荐给用户已经读过的文章
- Google BigTable,Apache HBase,Apache Cassandra使用布隆过滤器减少对不存在的行和列的查找。
6.拓展
问:如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?
- 答1:好,我们最简单的想法就是把这么多数据放到数据结构里去,比如List、Map、Tree,一搜不就出来了吗,比如map.get(),我们假设一个元素1个字节的字段,10亿的数据大概需要 900G 的内存空间,这个对于普通的服务器来说是承受不了的。
- 答2:用一种好的方法,巧妙的方法来解决,这里引入一种节省空间的数据结构,位图,他是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。

我们还需要一个映射关系,你总得知道某个元素在哪个位置上吧,然后在去看这个位置上是0还是1,
- 用到哈希函数,用哈希函数有两个好处,第一是哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,第二是他的分布是均匀的,如果全挤的一块去那还怎么区分,比如MD5、SHA-1这些就是常见的哈希算法。
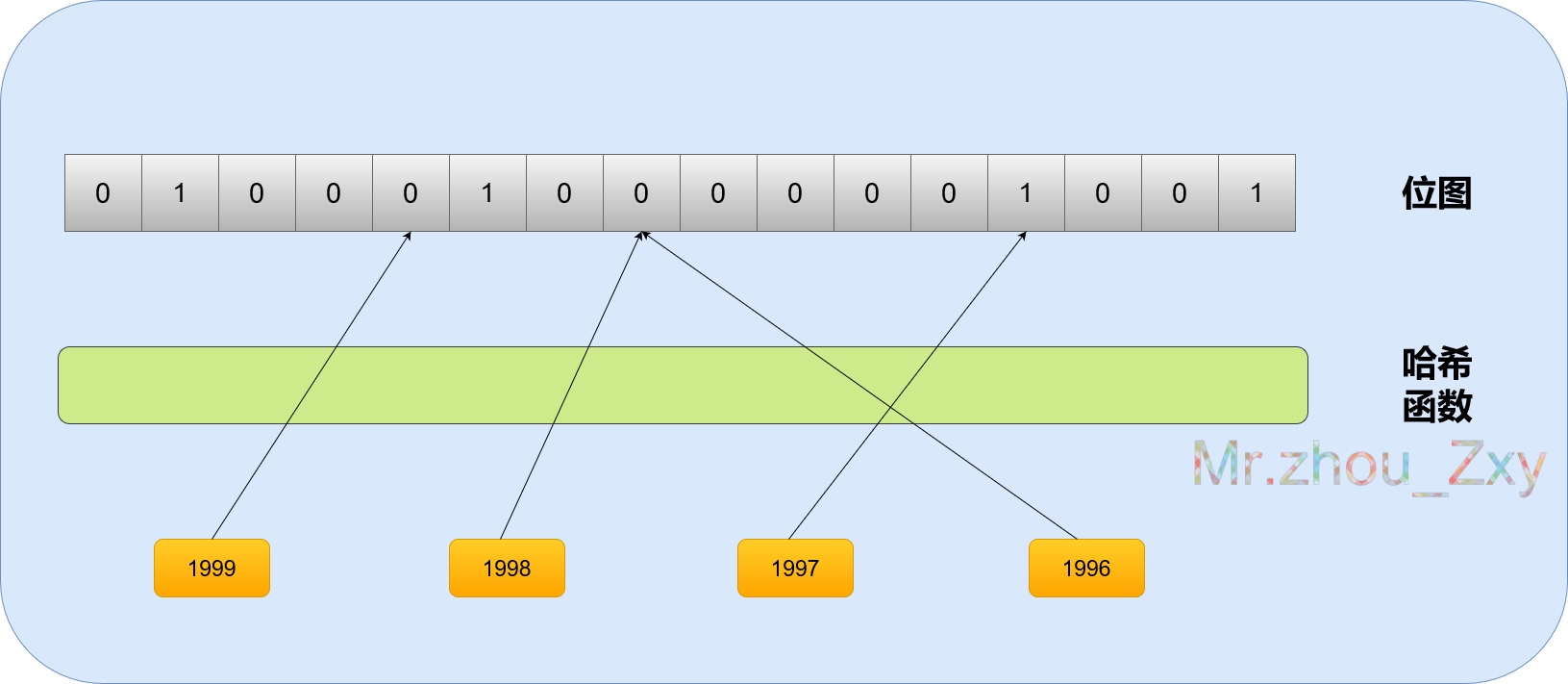
如上图中的1998和1996经过哈希函数得到的哈希值一样,就成为哈希冲突或者哈希碰撞。我们可以通过两种方法降低哈希碰撞产生的可能性。第一是扩大位图,但是内存消耗也在增加。第二是经过多个河西函数处理,但是越来越耗费时间。所以,还是需要用到布隆过滤器来处理。
三、JavaAPI操作redis(jedis连接池)中的set
- Operation .java
操作Redis类开发
package com.redis;
import redis.clients.jedis.Jedis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 173万+
173万+




 到【灌水乐园】发言
到【灌水乐园】发言









