







 本文介绍了RNN及其变体LSTM,详细阐述了TextRNN的网络结构,包括BiLSTM和多层RNN的使用。通过一个简单的代码实现展示了TextRNN在IMDB电影评论情感分析任务中的应用,包括数据预处理、模型构建、训练和验证过程。
本文介绍了RNN及其变体LSTM,详细阐述了TextRNN的网络结构,包括BiLSTM和多层RNN的使用。通过一个简单的代码实现展示了TextRNN在IMDB电影评论情感分析任务中的应用,包括数据预处理、模型构建、训练和验证过程。
Recurrent Neural Networks
RNN用来处理序列数据
具有记忆能力
Simple RNN
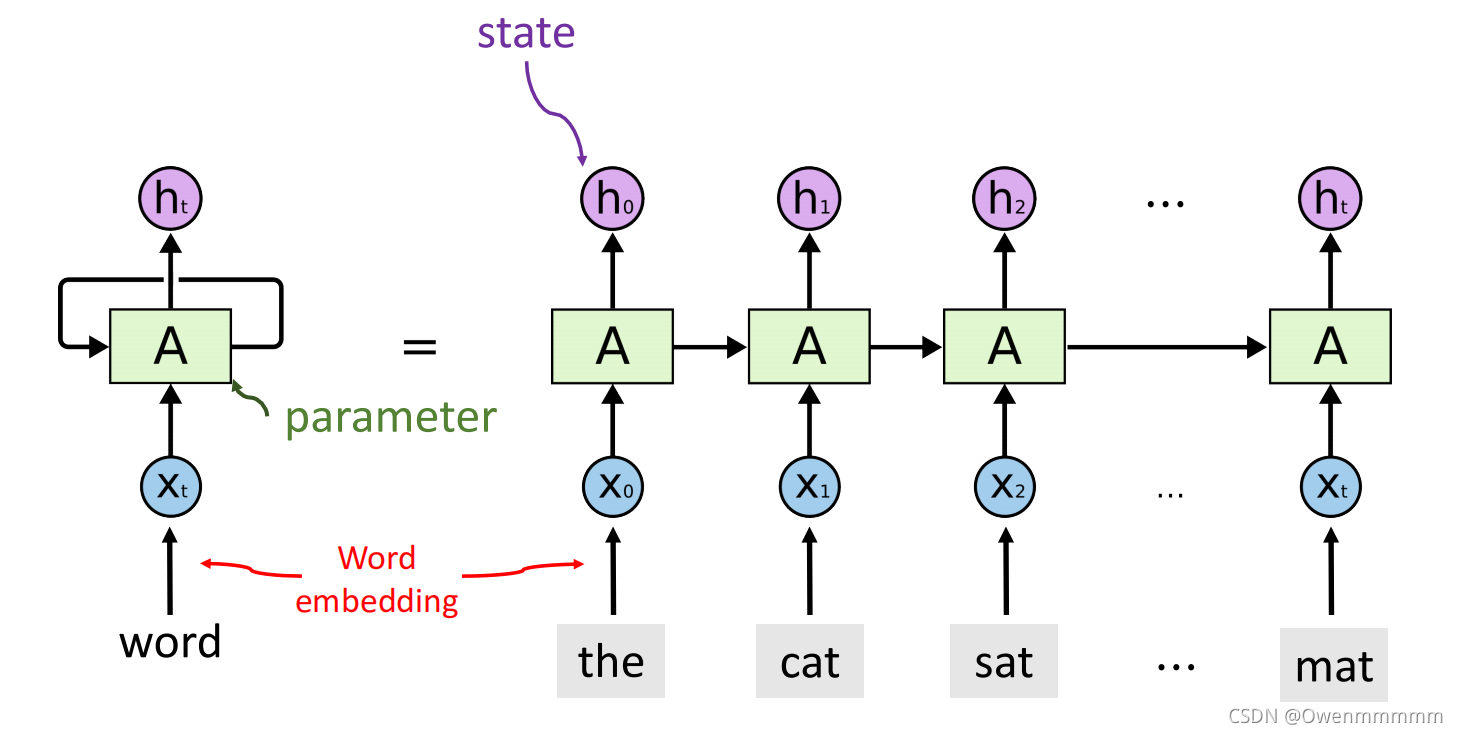
- h t h_t ht:状态矩阵,不断更新(h_0: the;h_1: the cat…)
- 只有一个参数矩阵A:随机初始化,然后用训练数据来学习A
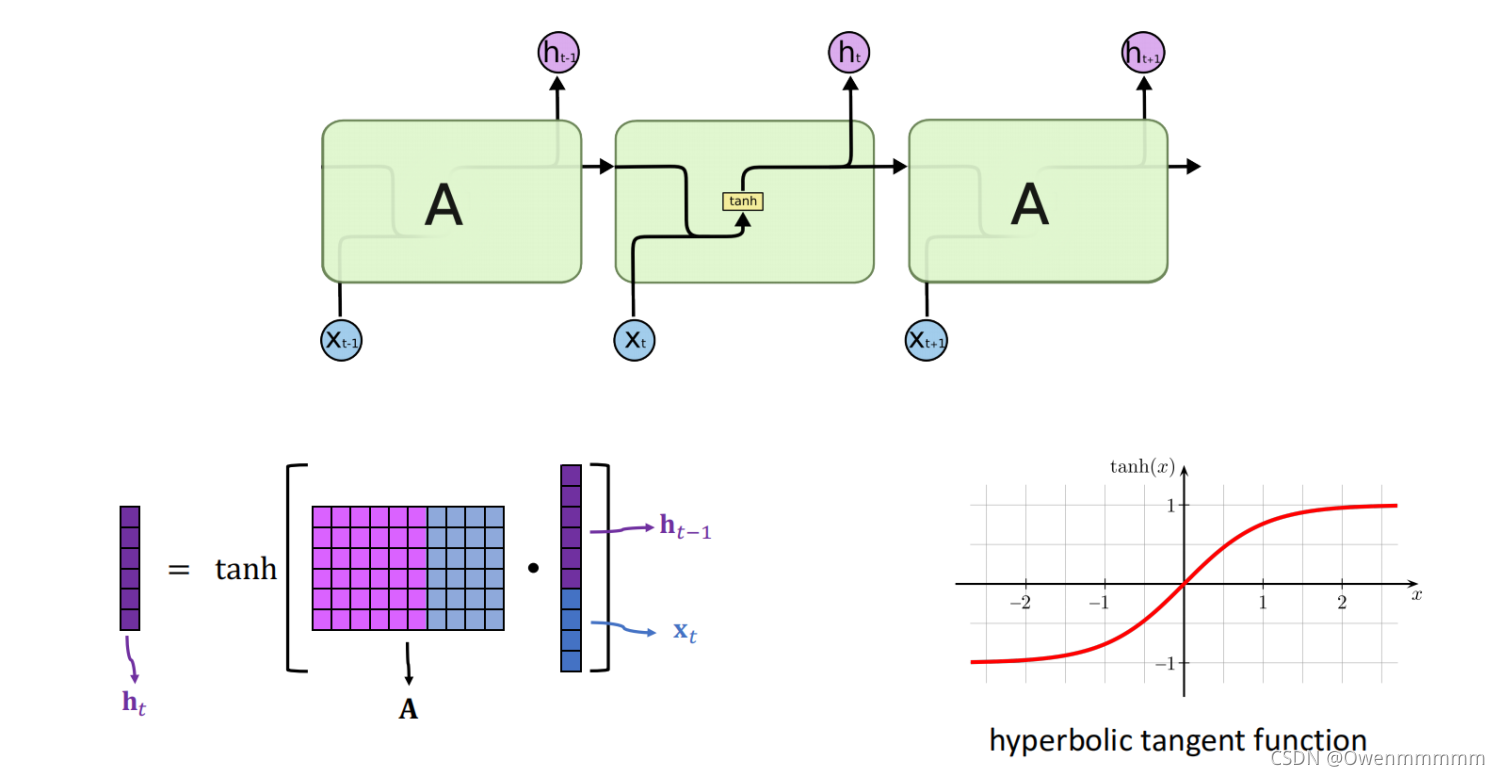
- 为什么需要tanh激活函数:如果不激活可能会出现梯度消失或者梯度爆炸。
LSTM
- LSTM可以避免梯度消失的问题
- LSTM的记忆力要比SimpleRNN强
结构图:
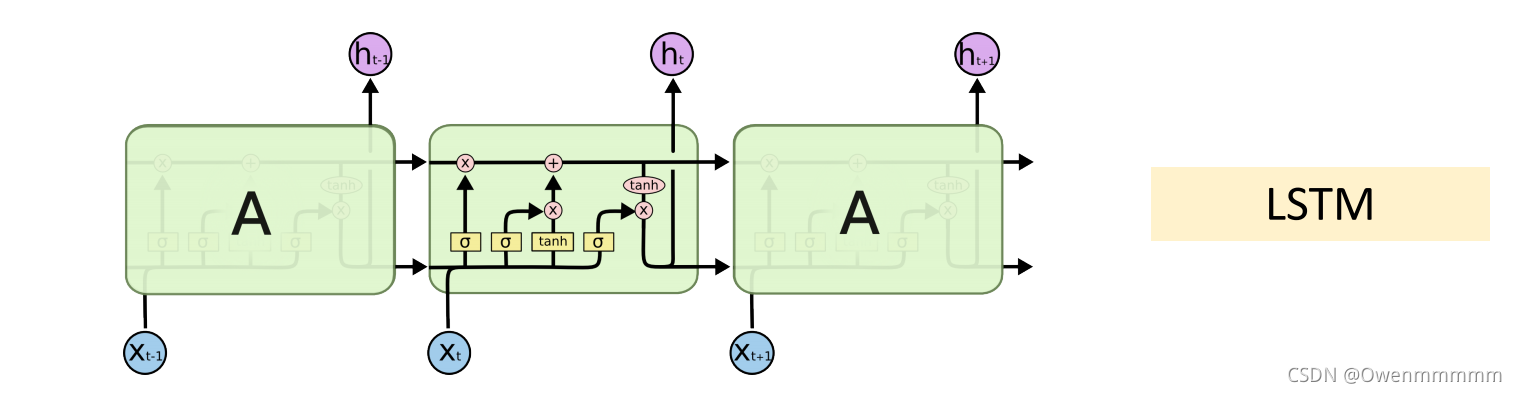
- LSTM有四个参数矩阵
- 传送带(conveyor bert):过去的信息可以直接传送到未来。
- 过去的信息直接通过 C t C_t Ct传送到下一个时刻,不会发生太大的变化(以此避免梯度消失)
1. Forget Gate
- f为遗忘门矩阵,为0就不通过
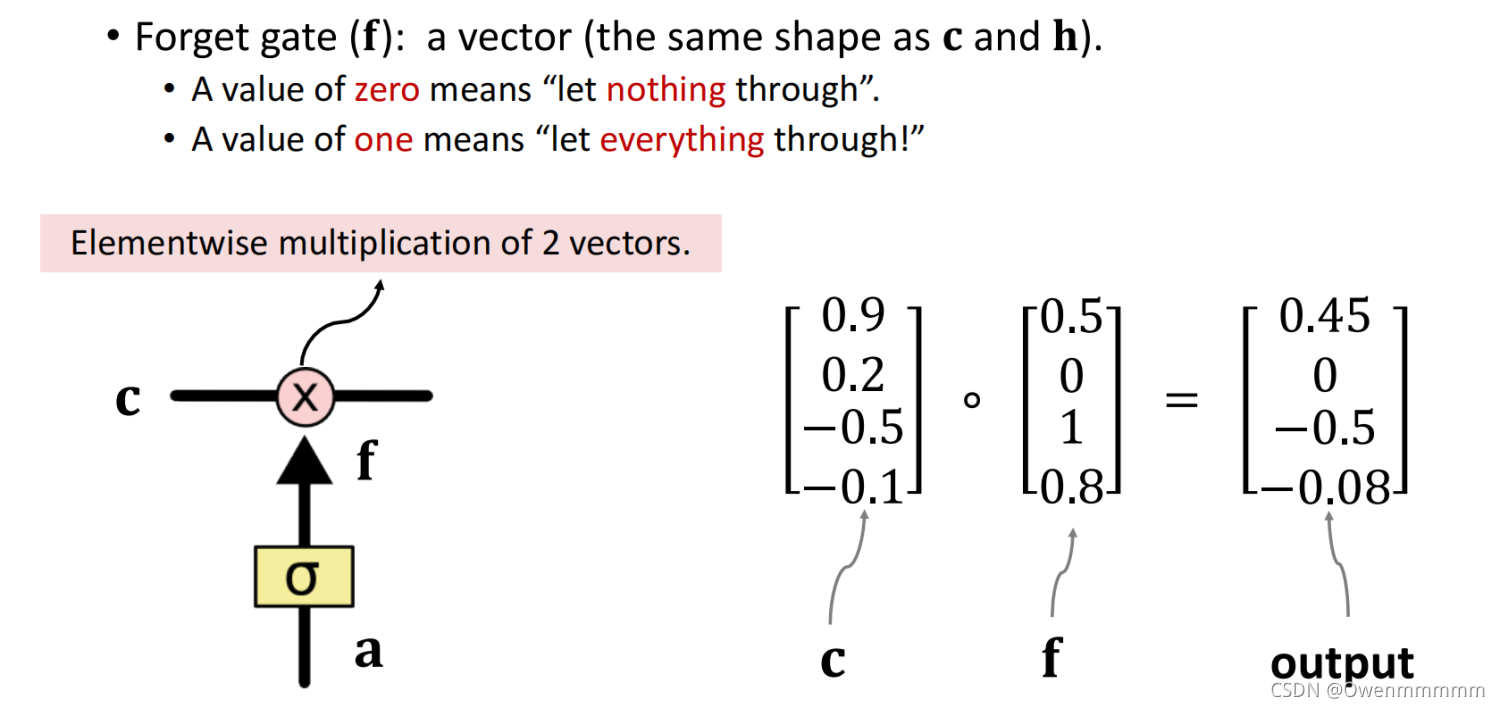
- W f W_f Wf:参数矩阵,通过反向传播从训练数据中学习
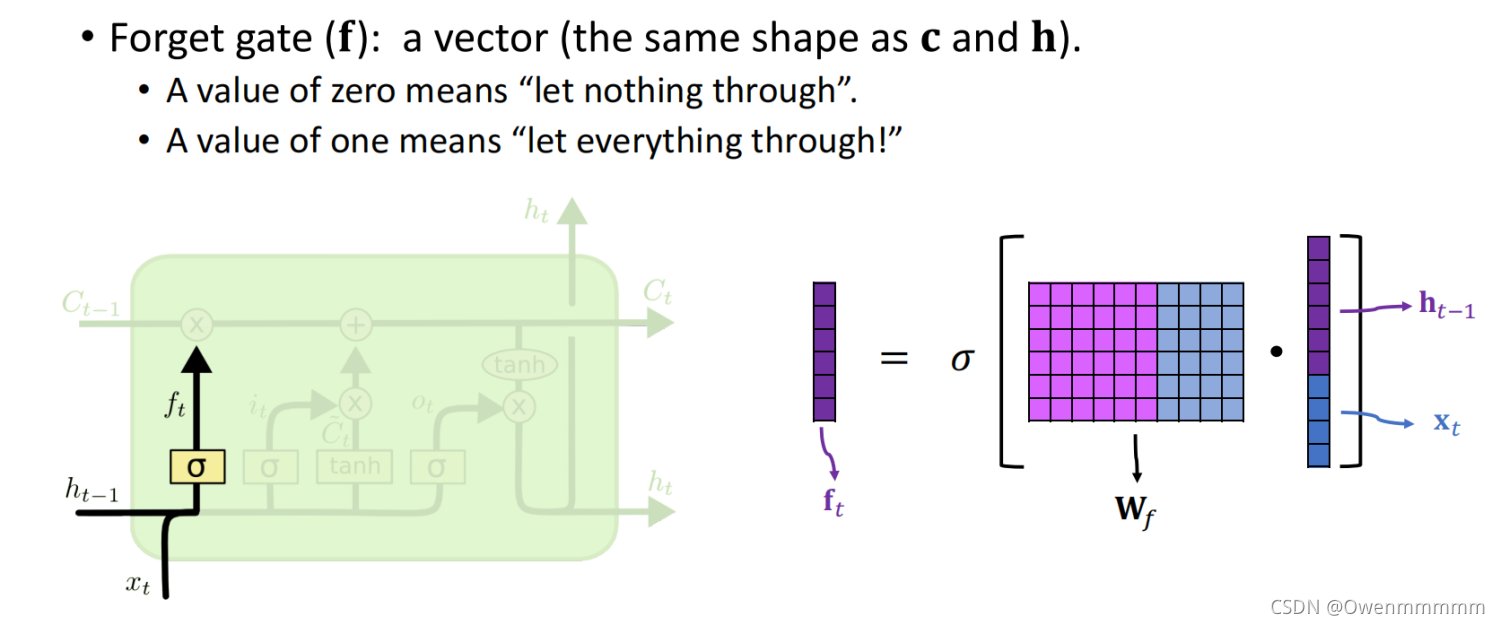
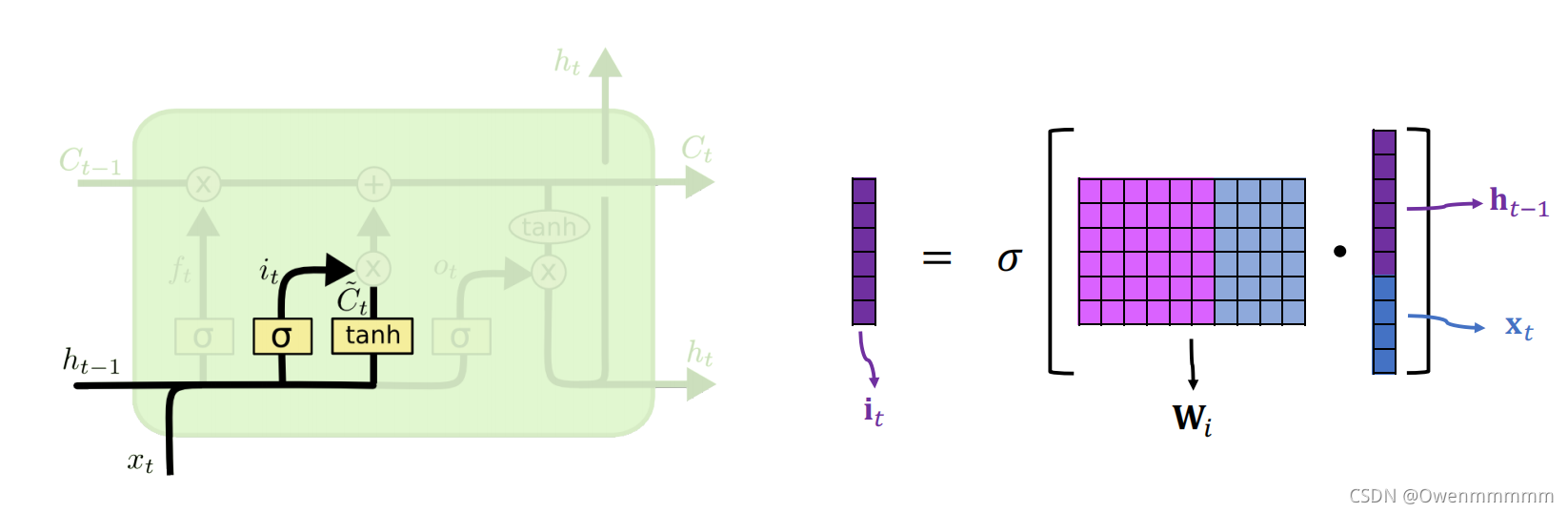
2. Input Gate
- W i W_i Wi:参数矩阵,通过反向传播从训练数据中学习
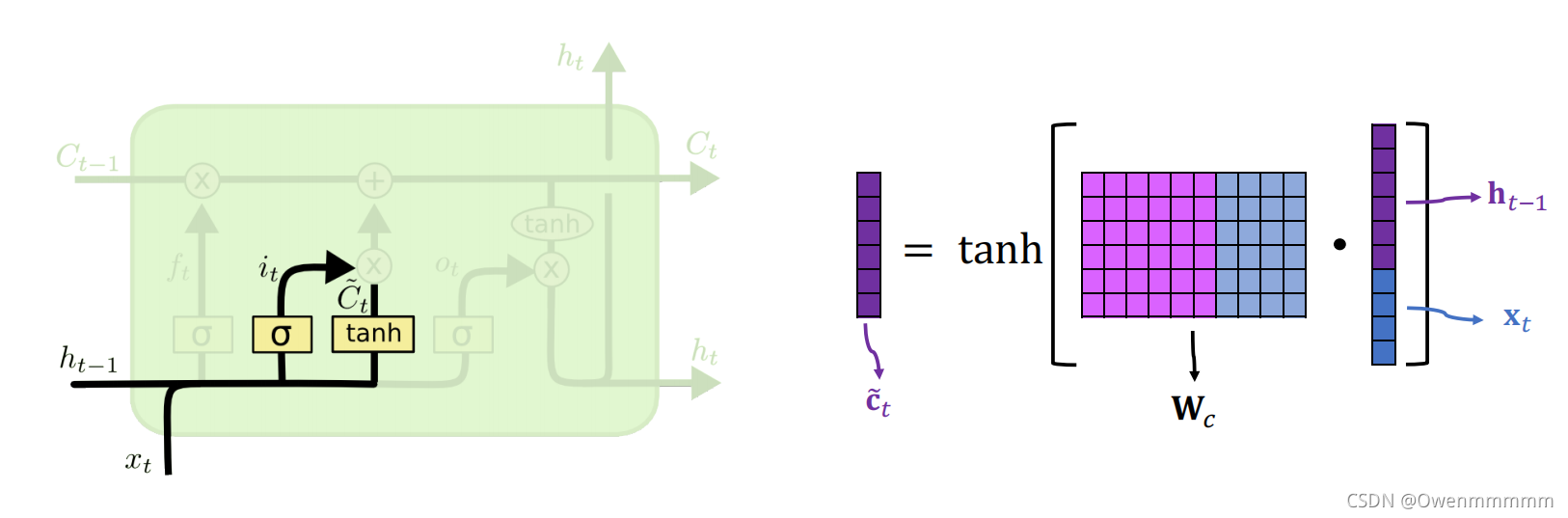
3. New Value
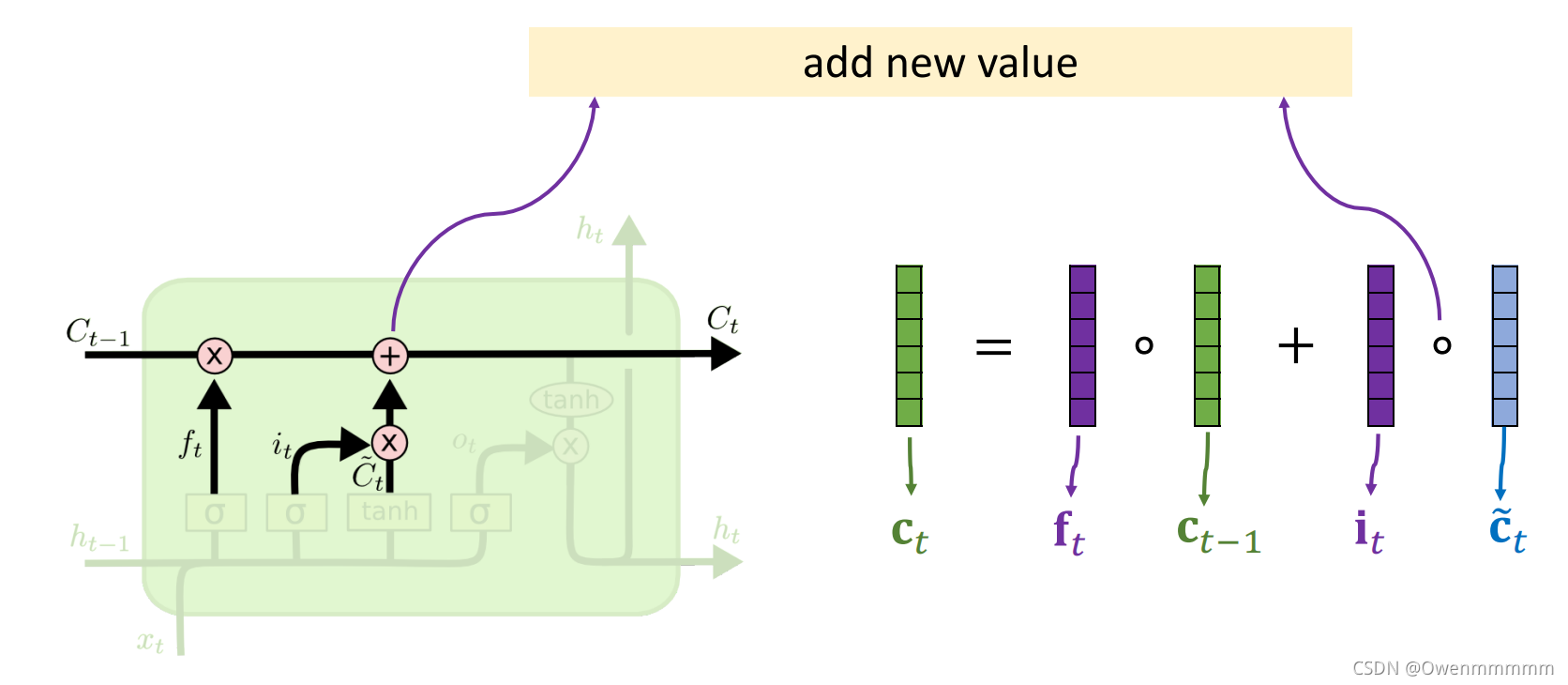
4. Output Gate
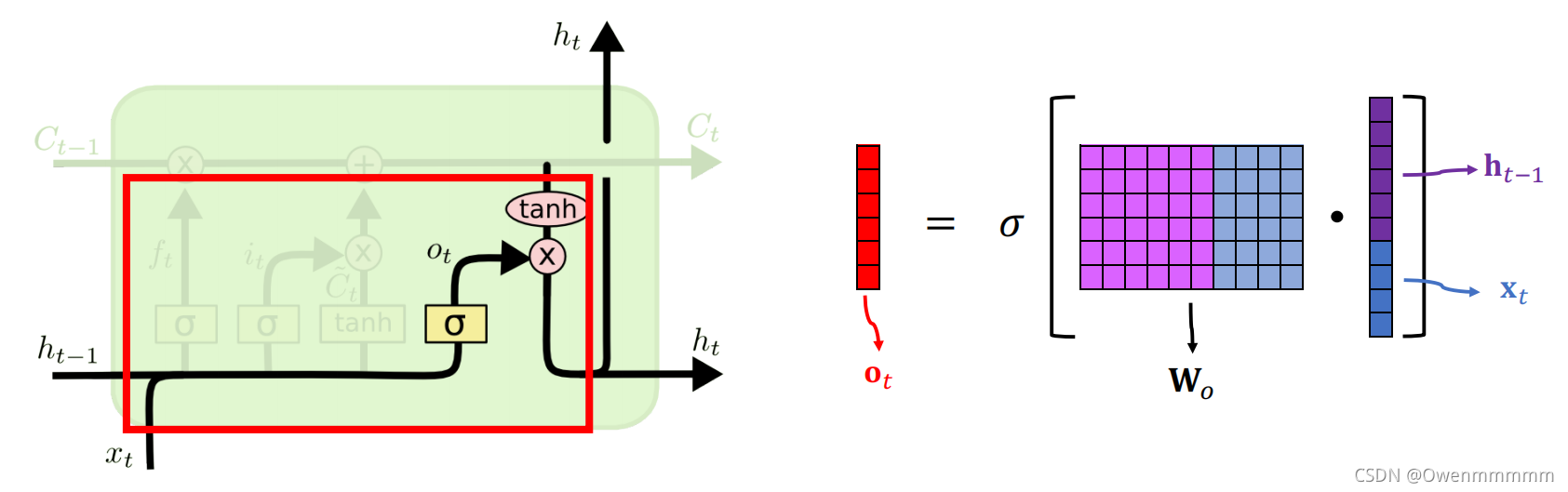
- Two Copies of ht:
- 一个作为输出
- 另一个传入到了下一步
改进RNN
- 多层RNN
- 双向RNN
- 预训练(预训练embedding层)
TextRNN
文本分类任务中,CNN可以用来提取句子中类似N-Gram的关键信息,适合短句子文本。TextRNN擅长捕获更长的序列信息。具体到文本分类任务中,从某种意义上可以理解为可以捕获变长、单向的N-Gram信息(Bi-LSTM可以是双向)。
一句话简介:textRNN指的是利用RNN循环神经网络解决文本分类问题,通常使用LSTM和GRU这种变形的RNN,而且使用双向,两层架构居多。
1. TextRNN简介
基本处理步骤:
- 将所有文本/序列的长度统一为n;对文本进行分词,并使用词嵌入得到每个词固定维度的向量表示。
- 对于每一个输入文本/序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出以及传递给下一个时间步长并和下一个单词的词向量一起作为RNN单元输入。
- 再计算下一个时间步长上RNN的隐藏状态
- 以此重复…直到处理完输入文本中的每一个单词,由于输入文本的长度为n,所以要经历n个时间步长。
2. TextRNN网络结构
流程:embedding—>BiLSTM—>concat final output/average all output—–>softmax layer
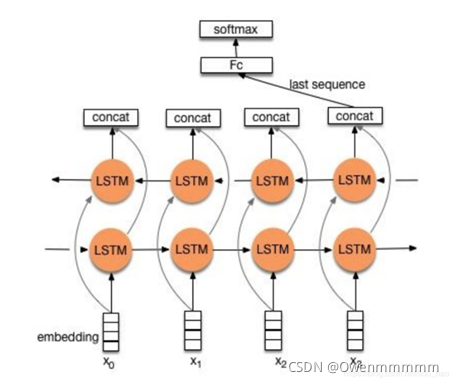
两种形式:
- 一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;
- 取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层(输出层使用softmax激活函数)进行一个多分类(2分类的话使用sigmoid激活函数)。
上述结构也可以添加dropout/L2正则化或BatchNormalization 来防止过拟合以及加速模型训练。
简单代码实现
任务:输入前两个此,预测下一个词
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
dtype = torch.FloatTensor
sentences = [ "i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {
w: i for i, w in enumerate(vocab)}
idx2word = {
i: w for i, w in enumerate(vocab)}
n_class = len(vocab)
# TextRNN Parameter
batch_size = 2
n_step = 2 # number of cells(= number of Step) 输入有多少个单词
n_hidden = 5 # number of hidden units in one cell
def make_data(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word2idx[n] for n in word[:-1]]
target = word2idx[word[-1]]
input_batch.append(np.eye(n_class)[input]) # one-hot编码
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_data(sentences)
input_batch, target_batch = torch.Tensor(input_batch), torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









