







 本文介绍了如何利用Transformer库和预训练的BERT模型进行情感分析,包括爬取Yelp评论,将其转化为DataFrame并计算情绪。通过编码、解码和模型预测,得出评论的情感等级。
本文介绍了如何利用Transformer库和预训练的BERT模型进行情感分析,包括爬取Yelp评论,将其转化为DataFrame并计算情绪。通过编码、解码和模型预测,得出评论的情感等级。
本文讲介绍如何利用Transformer库来快速搭建一个情感分析模型,同时也将利用BeautifulSoup从Yelp中获取评论,以便能够更大规模地计算情绪。
1. 导入依赖库
没有的话请提前安装,安装若有问题可以留言。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import requests
from bs4 import BeautifulSoup
import re
2. 初始化模型
这一段代码将从HuggingFace的Transformer库下载预训练好的情感分析模型。
https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment
这个预训练模型它以多颗星(1到5颗星之间)预测评论的情绪。
- Example
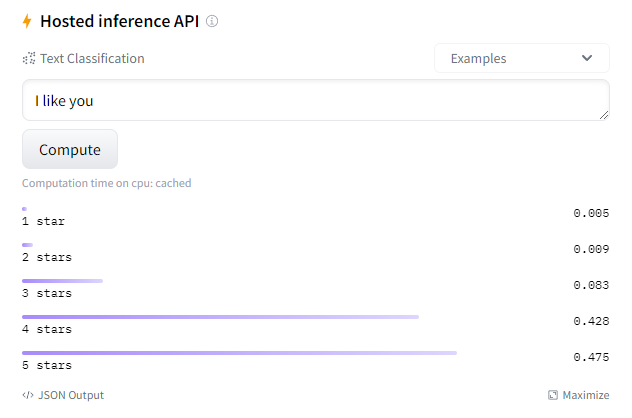
tokenizer = AutoTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
model = AutoModelForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
3. 编码以及计算情绪
tokens = tokenizer.encode('I hated this, absolutely the worst', return_tensors='pt')
- 可以查看经预训练tokenizer编码之后的句向量
tokens
# tensor([[ 101, 151, 39487, 10163, 10372, 117, 35925, 10563, 10103, 43060, 102]])
- 经预训练tokenizer解码之后的句子包含了
[CLS]和<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









