







线性回归
应用
- Stock Market Forecast
- Self-driving(input:sensor数据;output:方向盘角度)
- Recommendation(input:购买人A,商品B特性;output:购买B的可能性)
- Combat Power of Pokemon(李宏毅宝可梦学习……)
模型步骤
- 模型假设,选择框架模型
- 模型评估,损失函数
- 模型优化,如何筛选最优的模型
线性回归定义
线性回归的定义是:目标值预期是输入变量的线性组合
Hypothesis:
y
=
b
+
∑
i
=
0
n
w
i
x
i
(
x
i
:
f
e
a
t
u
r
e
;
w
i
:
w
e
i
g
h
t
;
b
:
b
i
a
s
)
y=b+\sum_{i=0}^nw_ix_i(x_i:feature;w_i:weight;b:bias)
y=b+i=0∑nwixi(xi:feature;wi:weight;b:bias)
Bi-features
- 模型假设 - 线性模型
假设两个参数: h θ ( x ) = θ o + θ 1 x h_θ(x)=θ_o+θ_1x hθ(x)=θo+θ1x - 模型评估:损失函数
Loss Function: J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m [ h θ ( x i ) − y i ] 2 J(θ_0,θ_1)=\frac{1}{2m}\sum_{i=1}^m[h_θ(x^i)-y^i]^2 J(θ0,θ1)=2m1i=1∑m[hθ(xi)−yi]2 - 模型优化 - 梯度下降
a. Start witm some θ 0 , θ 1 θ_0,θ_1 θ0,θ1
b. keep changing θ 0 , θ 1 θ_0,θ_1 θ0,θ1,to reduce J ( θ 0 , θ 1 ) J(θ_0,θ_1) J(θ0,θ1) ,until minimum.
updata equation: θ j = θ j − α ∂ J ( θ 0 , θ 1 ) ∂ θ j ( j = 0 , 1 ; α : l e a r n i n g − r a t e ) θ_j=θ_j-α\frac{∂J(θ_0,θ_1)}{∂θ_j}(j=0,1;\alpha:learning-rate) θj=θj−α∂θj∂J(θ0,θ1)(j=0,1;α:learning−rate)
∂ J ( θ 0 , θ 1 ) ∂ θ 0 = 1 m ∑ i = 1 m [ h θ ( x i ) − y i ] \frac{∂J(θ_0,θ_1)}{∂θ_0}=\frac{1}{m}\sum_{i=1}^m[h_θ(x^i)-y^i] ∂θ0∂J(θ0,θ1)=m1i=1∑m[hθ(xi)−yi]
∂ J ( θ 0 , θ 1 ) ∂ θ 1 = 1 m ∑ i = 1 m [ h θ ( x i ) − y i ] x i \frac{∂J(θ_0,θ_1)}{∂θ_1}=\frac{1}{m}\sum_{i=1}^m[h_θ(x^i)-y^i]x^i ∂θ1∂J(θ0,θ1)=m1i=1∑m[hθ(xi)−yi]xi
Multiple-features
- 模型假设 - 线性模型
假设多个参数: h θ ( x ) = θ o + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 h_θ(x)=θ_o+θ_1x_1+\theta_2x_2+\theta_3x_3+\theta_4x_4 hθ(x)=θo+θ1x1+θ2x2+θ3x3+θ4x4
For the convenience of notation,defineX0=1
x 0 i = 1 , X = [ x 0 x 1 x 2 x 3 x 4 ] , θ = [ θ 0 θ 1 θ 2 θ 3 θ 4 ] x_0^i=1,X=\begin{bmatrix}x_0\\x_1\\ x_2\\ x_3\\x_4\\ \end{bmatrix},\theta=\begin{bmatrix}\theta_0\\\theta_1\\ \theta_2\\ \theta_3\\\theta_4\\ \end{bmatrix} x0i=1,X=⎣⎢⎢⎢⎢⎡x0x1x2x3x4⎦⎥⎥⎥⎥⎤,θ=⎣⎢⎢⎢⎢⎡θ0θ1θ2θ3θ4⎦⎥⎥⎥⎥⎤
h θ ( x ) = θ T X h_\theta(x)= \boldsymbol{\theta}^\mathsf{T}X hθ(x)=θTX - 模型评估:损失函数
Loss Function: θ j = θ j − α 1 m ∑ i = 1 m [ h θ ( x i ) − y i ] X j i ( j = 0 , 1 , 2 … … ; α : l e a r n i n g − r a t e ) θ_j=θ_j-α\frac{1}{m}\sum_{i=1}^m[h_θ(x^i)-y^i]X_j^i(j=0,1,2……;\alpha:learning-rate) θj=θj−αm1i=1∑m[hθ(xi)−yi]Xji(j=0,1,2……;α:learning−rate) - 模型优化 - 梯度下降
updata equation: ∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m [ h θ ( x i ) − y i ] X j i \frac{∂J(θ)}{∂θ_j}=\frac{1}{m}\sum_{i=1}^m[h_θ(x^i)-y^i]X_j^i ∂θj∂J(θ)=m1i=1∑m[hθ(xi)−yi]Xji
θ j = θ j − α 1 m ∑ i = 1 m [ h θ ( x i ) − y i ] X j i ( j = 0 , 1 , 2 … … ; α : l e a r n i n g − r a t e ) θ_j=θ_j-α\frac{1}{m}\sum_{i=1}^m[h_θ(x^i)-y^i]X_j^i(j=0,1,2……;\alpha:learning-rate) θj=θj−αm1i=1∑m[hθ(xi)−yi]Xji(j=0,1,2……;α:learning−rate)
一元N次线性模型
y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + … … y=b+w_1x_{cp}+w_2(x_{cp})^2+w_3(x_{cp})^3+…… y=b+w1xcp+w2(xcp)2+w3(xcp)3+……
- 在模型上,我们可以进一步优化,使用更高次方的模型,必定会在训练集上表现更为优秀;
- 但是在训练集上表现更为优秀的模型,在测试集上的效果可能反而更差——>过拟合
过拟合
- 原因:
a. 原始特征过多,存在一些嘈杂特征
b. 模型过于复杂(尝试去兼顾各个测试数据点) - 解决办法
c. 进行特征选择,消除关联大的特征(Hard)
d. 交叉验证(不能解决,只能检验)
e. 正则化(减少高次项权重)
步骤优化
- 多个线性模型合并到一个线性模型 (提取信息的能力变强了)
- 更多参数,更多input
- 加入正则化
代码实现
import numpy as np
import matplotlib.pyplot as plt
def model(a,b,x):
return a*x+b
def cost_function(a,b,x,y):
n = 10
return 0.5/n*(np.square(y-a*x-b)).sum()
def optimize(a,b,x,y):
n = 5
learning_rate = 1e-1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y)).sum()
a = a - learning_rate*da
b = b - learning_rate*db
return a,b
x = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
x = np.reshape(x,newshape=(-1,1)) / 100.0
y = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
y = np.reshape(y,newshape=(-1,1)) / 100.0
plt.scatter(x,y)
# 初始化
a = 0
b = 0
# 遍历
def iterate(a,b,x,y,times):
for i in range(times):
a,b = optimize(a,b,x,y)
y_hat=model(a,b,x)
cost = cost_function(a, b, x, y)
print(a,b,cost)
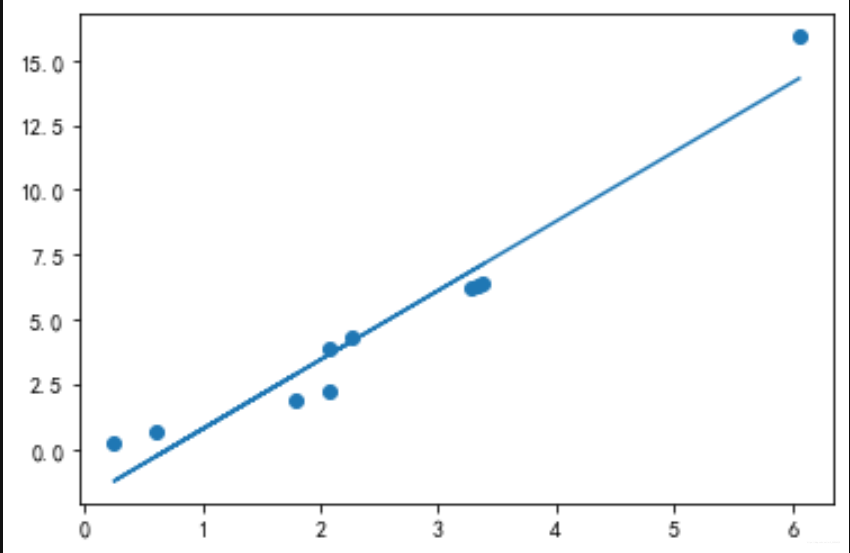
plt.scatter(x,y)
plt.plot(x,y_hat)
return y_hat
iterate(a,b,x,y,100000)
a,b,cost:2.669454966762257 -1.8843319665732654 0.5096836494794538
y_hat: array([[ 7.13842582],
[ 7.00495307],
[ 6.87148032],
[ 3.64143981],
[ 4.14863626],
[-1.21696822],
[ 2.89399242],
[-0.28265899],
[ 3.66813436],
[14.29256513]]))
sklearn代码实现
# 获取数据
from sklearn.datasets import load_boston
boston = load_boston()
boston.DESCR
# 数据分割
from sklearn.model_selection import train_test_split
import numpy as np
x = boston.data
y = boston.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
# 标准化处理 目标值也要标准化处理:由于假设方程
# 实例化两个标准化
from sklearn.preprocessing import StandardScaler
ss_X = StandardScaler()
x_train = ss_X.fit_transform(x_train)
x_test = ss_X.transform(x_test)
ss_y = StandardScaler()
y_train = ss_y.fit_transform(y_train.reshape(-1,1))
y_test = ss_y.transform(y_test.reshape(-1,1))
# 1. 正规方程求解方式预测结果
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_) #回归系数
# y_predict = lr.predict(x_test)
# print('测试集里每个房子的预测价格:',y_predict)
# 看到原来的结果
y_lr_predict = ss_y.inverse_transform(lr.predict(x_test))
print('测试集里每个房子的预测价格:',y_lr_predict)
# 2. 梯度下降的方法预测结果
from sklearn.linear_model import SGDRegressor
SGD = SGDRegressor()
SGD.fit(x_train,y_train.ravel()) #ravel:解决DataConversionWarning
print(SGD.coef_) #回归系数
y_sgd_predict = ss_y.inverse_transform(SGD.predict(x_test))
print('测试集里每个房子的预测价格:',y_sgd_predict)
# 回归性能评估:均方根误差
# 传入的真实值预测值均为标准化之前的数字
from sklearn.metrics import mean_squared_error
print('正规方程的均方根误差:',mean_squared_error(ss_y.inverse_transform(y_test),y_lr_predict))
print('梯度下降的均方根误差:',mean_squared_error(ss_y.inverse_transform(y_test),y_sgd_predict))
正规方程的均方根误差: 15.527809174130768
梯度下降的均方根误差: 15.707687539776714
岭回归
- 带有正则化的线性回归,可以使得权重趋近于0。越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
- 岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数,得到的回归系数更符合实际、更可靠,对病态数据的拟合要强于最小二乘法。
- 当数据集中存在共线性的时候,岭回归就有用。
# 数据处理见线性回归
from sklearn.linear_model import Ridge
rd = Ridge(alpha=0.5)
rd.fit(x_train,y_train)
print(rd.coef_)
y_rd_predict = ss_y.inverse_transform(rd.predict(x_test))
print(y_rd_predict)
print('岭回归的均方根误差:',mean_squared_error(ss_y.inverse_transform(y_test),y_rd_predict))
[[-0.10815706 0.1019874 0.02347368 0.08807389 -0.26886108 0.22345934
0.00473672 -0.34140667 0.31799134 -0.23874863 -0.22060247 0.08072599
-0.45430967]]
岭回归的均方根误差: 15.519013730980953


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









