






在 Java 开发的日常工作里,你或许曾编写过这样的代码:
@Transaction // 开启事务
public void createOrder(Order order) {
saveOrder(order);
sendMQ(order); // 或者是发起 RPC 调用
}
在上述代码中,于一个事务内部,先向 MySQL 数据库写入数据,紧接着便进行 MQ 消息的发送或者 RPC 调用。乍一看,在大多数情况下,这种代码编写方式似乎并无不妥。
然而,当下游系统执行反查操作时,却会出现数据查无踪迹的状况。更令人匪夷所思的是,此问题通常在业务低谷期才会冒出来,而在业务高峰期反倒相安无事,这背后究竟隐藏着怎样的缘由呢?
潜在问题
事务原子性语义受损
以 MySQL 的 InnoDB 事务为例,数据库事务仅仅能够确保数据库操作具备原子性,对于外部系统(诸如 MQ 或者 RPC 服务)的行为却无能为力。这就极有可能引发以下两种不良后果:
-
事务成功提交了,但 MQ 消息却发送失败。
-
事务提交失败了,可 MQ 消息却发送成功了。
我们所追求的事务原子性,是指一系列操作要么全部顺利完成,要么全部失败。而上述这两种情况,都会致使上下游数据出现不一致的问题。
下面以电商场景来详细说明。当用户支付成功之后,在事务内部会执行如下操作:
-
将订单状态更新为“已支付”(这属于数据库操作)。
-
发送物流服务的 MQ 消息(这属于外部操作)。
倘若步骤 1 顺利执行,而步骤 2 却失败了,就会出现用户已经支付了款项,但商品却未能发货的情况。要是步骤 1 执行失败,而步骤 2 执行成功,就会出现用户尚未支付,却被要求收货的尴尬局面。
长事务问题愈发严峻
MQ 和 RPC 操作通常属于网络 I/O 操作,其耗时往往要比本地数据库操作长得多。而且,网络环境具有不稳定性,随时都可能出现延迟、不可用、丢包等问题。这些因素都会使得事务的执行时间延长,进而引发以下一系列问题:
-
数据库锁竞争会变得更加激烈,甚至有可能引发死锁。
-
在高并发的场景下,RPC 操作耗时过长,会增加 DB 连接池的占用时间,从而降低系统的整体吞吐量。
下游反查数据遭遇失败
我们来看这样一个实际的业务场景:用户完成支付后,需要创建订单,并且向权益中心发送 RPC 请求以增加积分。在事务提交之前,权益中心需要进行数据反查。然而,由于事务隔离级别为“读已提交”及以上,此时权益中心无法查询到尚未提交事务的订单数据。这样一来,RPC 就会返回失败结果,进而导致本地事务无法提交。这就形成了一个死循环:上游需要等待下游执行成功后才能提交事务,而下游又要等待上游提交事务后才能返回执行成功。
回到开头提到的问题,在业务低谷期,MQ 消息会出现反查无法查询到数据的情况,这是因为在低谷期 MQ 消息能够被及时消费,其延迟几乎和 RPC 请求一样,这就使得消费者会在事务提交前执行反查操作,从而出现和 RPC 请求相同的问题。而在高峰期,由于 MQ 消费不及时,反查操作被“延后”了,在事务提交后才开始消费,所以可以查询到数据。这本质上是上游事务提交和下游消费的时序问题。
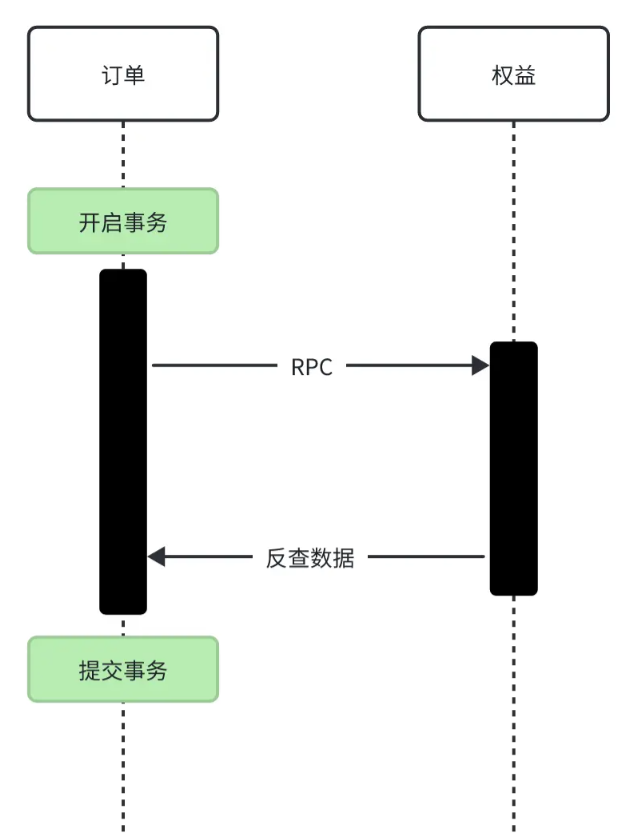
时序问题
详细探讨解决方案
保障事务提交与消息发送的时序
让消费者适当等待
可以继续在事务中嵌套发送消息,不过当消费者接收到消息时,让其主动休眠一段时间后再进行消费。或者发送延迟消息,确保消费者晚点再消费。这样做的目的是通过等待一定的时间,保证消费者的消费行为发生在事务提交之后。
但这种方法存在一个明显的弊端,那就是延迟时间很难精准把控:
-
如果延迟时间设置得太短,消费者可能会在事务提交之前执行反查操作,这样延迟时间就失去了意义。
-
如果延迟时间设置得太长,就会加大延迟,降低系统的吞吐量。
这和 Redis 延迟双删的思路有些相似,都是等一段时间后再执行后续操作,而且它们的缺点也相同,就是很难确定到底需要延迟多久。
在事务提交之后再发送消息
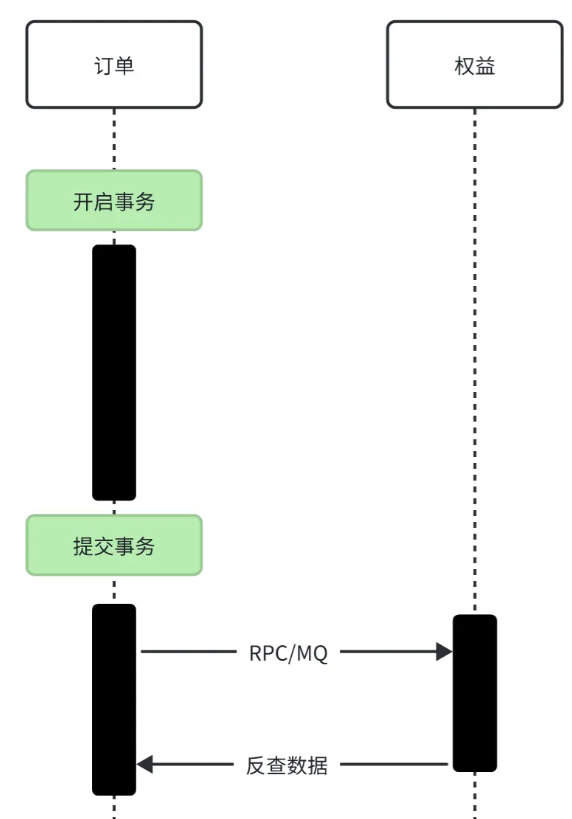
提交后发送消息
可以在事务提交之后,再进行 MQ 消息的发送和 RPC 请求。这样就能确保事务提交操作在发送 MQ 消息和 RPC 请求之前完成,避免它们在事务中嵌套。示例代码如下:
public void createOrder(Order order) {
saveOrderByTransaction(order); // 通过事务写入订单
sendMQ(order); // 或者是发起 RPC 调用,在事务之外执行
}
@Transaction // 仅对 SQL 操作添加事务
public void saveOrderByTransaction(Order order) {
saveOrder(order);
}
不过,上述代码存在一个问题:如果事务执行失败,代码可能会继续向下执行,此时 MQ 消息依旧会被发送成功。也就是说,本地事务提交失败,但 MQ 消息却成功发送了,这会导致上下游状态不一致。
为了解决这个问题,我们需要判断事务是否成功提交,只有成功提交了,才发送消息。
可以使用 if - else 语句来实现,但 Spring 为我们提供了一种更为优雅的解决方案:使用@TransactionalEventListener来监听事务状态。当事务成功提交后,才执行某些逻辑,这样就能保证当事务提交失败时,不发送 MQ 消息;只有当事务成功提交时,才发送 MQ 消息。示例代码如下:
// OrderService
@Transactional
public void createOrder(Order order) {
// 假设订单创建成功后,发布事件
OrderCreatedEvent event = new OrderCreatedEvent(order);
eventPublisher.publishEvent(event);
saveOrder(order);
}
// OrderCreatedEventListener
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleOrderCreatedEvent(OrderCreatedEvent event) {
sendMQ(event);
}
确保本地事务与 MQ 消息的原子性
上面提到的@TransactionalEventListener实际上还存在一个问题,即事务提交成功,但 MQ 消息发送失败,无法保证本地事务和消息发送的原子性,也就是无法实现要么都成功,要么都失败的目标。下面介绍几种可行的解决方案:
分布式事务
分布式事务可以解决本地事务和 MQ 消息的原子性问题,但它会带来可靠性、性能、使用成本等方面的问题,给系统增加额外的复杂性。总体而言,这种方法的弊端远大于益处。
事务消息
在 RocketMQ 中,支持事务消息,它可以保证本地事务和 MQ 消息的原子性。其执行逻辑如下:
-
生产者将消息发送至 Apache RocketMQ 服务端。
-
Apache RocketMQ 服务端将消息持久化成功之后,会向生产者返回 Ack 确认消息已经发送成功,此时消息被标记为“暂不能投递”,这种状态下的消息即为半事务消息。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit 或是 Rollback),服务端收到确认结果后会进行如下处理:
-
若二次确认结果为 Commit,服务端将半事务消息标记为可投递,并投递给消费者。
-
若二次确认结果为 Rollback,服务端将回滚事务,不会将半事务消息投递给消费者。
-
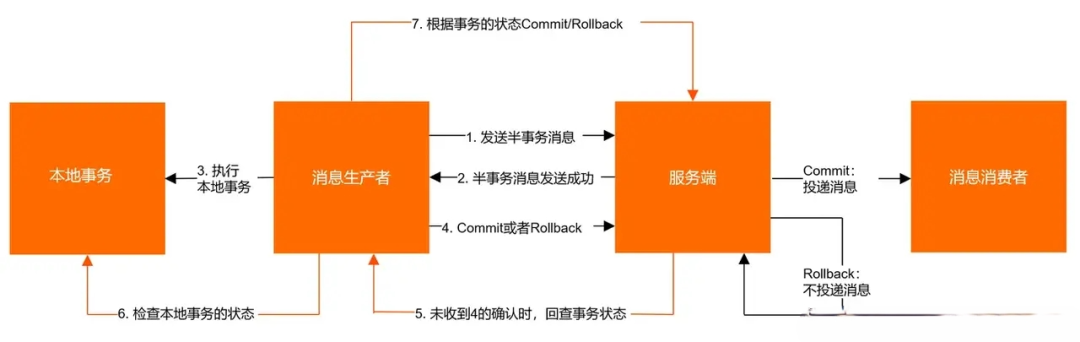
事务消息
本地消息表 + 定时任务
比较常见的解决方案是采用本地消息表 + 定时任务的方式。在本地事务中,除了写入业务数据外,还要将要发送的 MQ 消息写入到 MySQL 的消息表中。而发送消息不再由业务代码决定,而是由后台定时任务来轮询消息表,定时发送消息。这样可以保证:
-
本地事务执行失败时,不会发送 MQ 消息。因为消息表不会写入该消息(会回滚),定时任务自然不会发送该消息。
-
本地事务执行成功时,可以保证 MQ 消息一定能发送成功。定时任务查询到消息表的消息后,会发送消息。如果出现失败,可以继续重试。当达到一定重试次数还发送失败时,可以发送信息,让人工介入处理。
如果允许数据存在一定的延迟,即不是要求强一致的场景,只需要保证数据的最终一致性,那么本地消息表 + 定时任务是一个非常不错的选择,同时它也能解决上面提到的事务提交和消息发送的时序问题。示例代码如下:
// OrderService
@Transactional
public void createOrder(Order order) {
saveOrder(order);
saveOrderMessage(order); // 写入本地消息表
// 不需要在代码中编写发送 MQ 消息的逻辑
}
// MessageSendTask
@Scheduled(fixedRate = 1000) // 每隔 1 秒执行一次
public void handleOrderCreatedEvent(OrderCreatedEvent event) {
List<Message> messages = findMessages();
sendMQInBatches(messages);
// 接下来还要更新消息表中消息的发送状态
}
监听 binlog
可以通过 canal 监听上游数据库的 binlog 日志,解析日志后发送到 MQ 中,由下游自行决定如何消费。
优势:
-
上游提交后才通知到相关系统,下游反查可以查到数据。
-
可以保证本地事务和 MQ 消息的最终一致性。只有事务提交了,才有 binlog,才能发送 MQ 消息,供下游消费。
-
实现解耦。业务只需正常写入数据即可,无需关心具体的发送 MQ 消息的操作。
缺点: 实现较为复杂,需要额外维护监听 binlog 的第三方组件。
避免反查操作
消息中包含消费者所需的字段,即通过冗余字段来避免反查操作。这样一来,下游就无需关心上游事务何时提交。不过,这种方式会带来额外的问题:
-
会使生产者的逻辑变得更加复杂。
-
增大消息的体积,给网络带宽和 MQ 带来额外的负担。
-
MQ 的引入是为了解耦,即生产者无需关心消费者如何使用数据。如果生产者需要根据各类消费者定制消息,就会将生产者和消费者耦合在一起。这样一来,开发上游的人员还需要梳理整个消费逻辑,这可能会让他们不太愿意,导致上下游的开发难以协调,同时也需要有人来推动这种修改。所以,这不仅仅是一个技术问题。
而且在实际业务中,很多场景下反查操作是不可避免的,我们不能假定反查操作一定不存在:
-
在某些团队中,会采取一刀切的方式,即消息只允许携带主键值,这就必然会导致反查数据库。
-
下游需要查询到上游的最新数据。
-
在网络拍卖场景中,加价是基于当前最新价格进行的,此时必须获取最新的数据,而不是用户在网页上看到的“旧”数据,即当前读,此时肯定需要反查数据以获取最新值。
-
在电商场景中,订单的支付金额通常是用户创建订单时“看到的”价格。可能创建订单后商品价格上涨了,但一般还是以创建订单时的价格为准,即快照读,此时就不一定需要反查数据了。
-
总结
在事务中嵌套发送 MQ 消息和 RPC 调用,会引发以下问题:
-
事务回滚会导致上下游数据不一致。
-
增加事务执行时间,加剧锁竞争,导致系统吞吐量下降(长事务问题)。
-
下游无法反查到未提交的数据。
事务内应该只包含可靠的、可回滚的数据。也就是说,不要在事务中嵌套发送 MQ 消息和 RPC 调用。
常见的解决方案如下:
-
本地消息表 + 定时任务。由定时任务来发送 MQ 消息,实现简单、可靠,效果良好。
-
事务消息。依赖 RocketMQ 来实现。
-
监听 binlog。但实现成本较高。
同时,由于数据库存在主从延迟,反查操作并不保证一定能查到数据,因此适当的重试也是不可避免的。

















 2833
2833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









