










标题:Docker双显卡环境报错解决:Failed to initialize NVML: Unknown Error(附详细分析)
🔍 问题背景
在Ubuntu 22双显卡主机上配置Docker运行大语言模型时,安装完NVIDIA驱动和NVIDIA Container Toolkit后,运行以下命令验证GPU支持:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
却报错 Failed to initialize NVML: Unknown Error,截图如下:
 —
—
🛠️ 错误原因分析
- 双显卡兼容性问题:在多GPU环境中,NVIDIA Container Toolkit可能无法自动挂载所有显卡设备。
- 设备权限缺失:Docker默认的
--gpus all参数可能未正确识别/dev/nvidia*设备文件,尤其是nvidiactl控制设备。 - NVML初始化失败:NVML(NVIDIA Management Library)依赖对显卡设备的完全访问权限,若设备未挂载或权限不足,会导致初始化失败。
✅ 终极解决方案
通过显式指定显卡设备和控制接口,强制Docker挂载所需设备:
sudo docker run --rm --gpus all \
--device=/dev/nvidiactl \
--device=/dev/nvidia0 \
--device=/dev/nvidia1 \
ubuntu nvidia-smi
执行效果:成功显示GPU状态,问题解决!
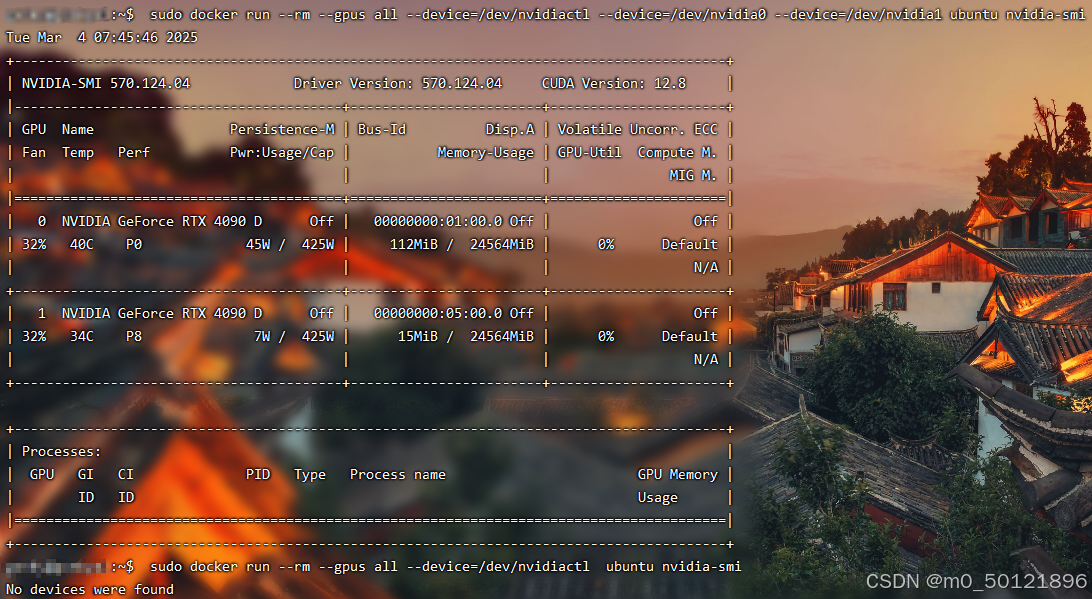
📝 原理详解
-
为什么需要
--device参数?--gpus all仅挂载GPU计算设备(如nvidia0,nvidia1),但可能遗漏控制设备nvidiactl。- 显式指定
--device确保容器内能访问所有NVIDIA设备文件,包括管理和计算接口。
-
关键设备说明
/dev/nvidiactl:NVIDIA显卡的统一控制接口,必须挂载。/dev/nvidia0,/dev/nvidia1:物理GPU设备,对应双显卡环境中的两张卡。
💡 预防与优化建议
-
永久配置Docker(可选)
在/etc/docker/daemon.json中添加默认设备规则,避免每次手动指定:{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } }, "device-requests": [ {"count": -1, "capabilities": [["gpu"]]}, {"driver": "nvidia", "capabilities": ["compute", "utility"]} ] }重启Docker服务:
sudo systemctl restart docker -
检查设备列表
通过命令查看所有NVIDIA设备,确认实际编号:ls /dev/nvidia*输出示例:
/dev/nvidia0 /dev/nvidia1 /dev/nvidiactl -
环境一致性验证
- 确保宿主机驱动版本与容器内CUDA版本兼容。
- 更新NVIDIA Container Toolkit至最新版本:
sudo apt-get install --upgrade nvidia-container-toolkit
🚨 注意事项
- 设备编号可能变化:若主机硬件调整(如增减显卡),需重新检查
/dev/nvidia*编号。 - 权限问题:若容器内仍报错,尝试添加
--privileged参数(慎用,仅测试环境推荐)。
📚 总结
在多GPU环境中,Docker的--gpus all参数可能无法覆盖所有依赖设备。通过显式挂载/dev/nvidiactl及物理GPU设备,可彻底解决NVML初始化问题。这一方案同样适用于其他需要多显卡支持的AI训练场景。
欢迎留言交流! 如果你遇到类似问题或有更好的方案,欢迎在评论区分享讨论~ 💬
“解决问题的方式不止一种,但目标都是星辰大海。” —— 你的点赞和收藏是我更新的动力! 🌟
(以上主要内容来着Deepseek)

















 2476
2476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









