






 本文介绍了图像处理中的双线性插值方法,用于在不同尺寸图像间平滑过渡;探讨了BN层在网络训练中的加速和稳定作用;阐述了SVM如何通过核函数处理非线性问题;最后讲解了空间、通道、时序及自注意力机制在深度学习中的应用,这些机制在捕获关键信息和提高模型性能方面至关重要。
本文介绍了图像处理中的双线性插值方法,用于在不同尺寸图像间平滑过渡;探讨了BN层在网络训练中的加速和稳定作用;阐述了SVM如何通过核函数处理非线性问题;最后讲解了空间、通道、时序及自注意力机制在深度学习中的应用,这些机制在捕获关键信息和提高模型性能方面至关重要。
1、介绍双线性插值法
假设源图像大小为mxn,目标图像为axb。那么两幅图像的边长比分别为:m/a和n/b。注意,通常这个比例不是整数,编程存储的时候要用浮点型。目标图像的第(i,j)个像素点(i行j列)可以通过边长比对应回源图像。其对应坐标为(i*m/a,j*n/b)。显然,这个对应坐标一般来说不是整数,而非整数的坐标是无法在图像这种离散数据上使用的。双线性插值通过寻找距离这个对应坐标最近的四个像素点,来计算该点的值。
如图,已知Q12,Q22,Q11,Q21,但是要插值的点为P点,这就要用双线性插值了,首先在x轴方向上,对R1和R2两个点进行插值,这个很简单,然后根据R1和R2对P点进行插值,这就是所谓的双线性插值。
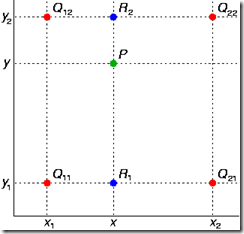
在x方向上线性插值(R1、R2),然后在y方向上线性插值(P),得到想要的结果:
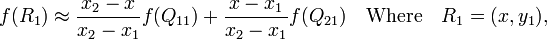
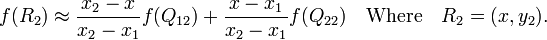
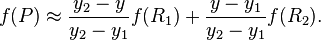
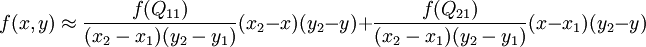
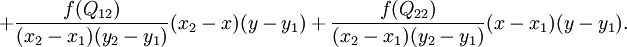
2、介绍BN层
- 加快网络的训练和收敛的速度
- 控制梯度爆炸防止梯度消失
- 防止过拟合
3、SVM如何处理非线性情况
- 利用核函数(去更高维度找到可以分类的超平面)
- 软间隔和正则话(降低分类要求)
4、介绍空间/通道/时序/自注意力机制
空间注意力机制:空间域将原始图片中的空间信息变换到另一个空间中并保留了关键信息。
通道注意力机制:在卷积神经网络中,每一张图片初始会由(R,G,B)三通道表示出来,之后经过不同的卷积核之后,每一个通道又会生成新的信号,比如图片特征的每个通道使用64核卷积,就会产生64个新通道的矩阵(H,W,64),H,W分别表示图片特征的高度和宽度。每个通道的特征其实就表示该图片在不同卷积核上的分量,这个权重越大,则表示相关度越高,也就是我们越需要去注意的通道了。
时序注意力机制:在预测每个时刻的输出时用到的上下文是跟当前输出有关系的上下文。
自注意力机制:本质上,对于每个输入向量,Self-Attention产生一个向量,该向量在其邻近向量上加权求和,其中权重由向量之间的关系或连通性决定。
5、LR为什么不能用平方损失?(采用对数似然)
用平方损失之类的得到的函数不是凸函数,会存在很多局部极小点,梯度下降很容易陷入局部最优。

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









