







Executor总资源 <= 从节点资源
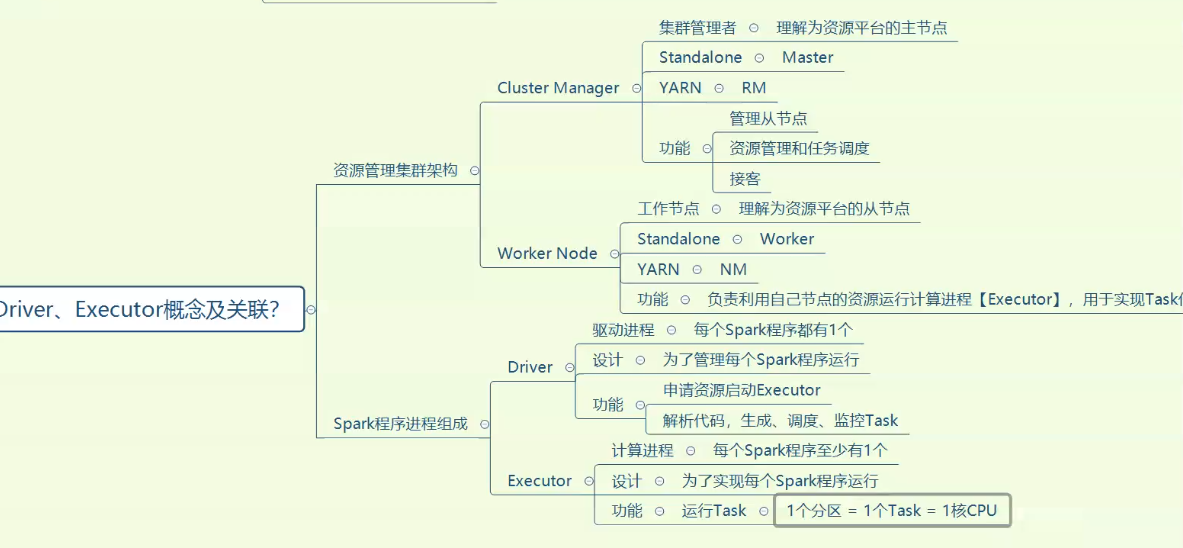
一个Executor的核数,只决定最大并行数
代表这个Executor最多同时处理8个Task
14个Task分配:14 = 8+6
![]()
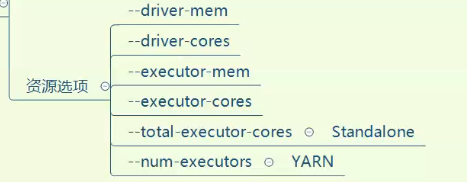
--master yarn
--num-executors
Task执行过程中,才会去读取数据变成RDD
1-先有Task,2-先有RDD的(数据)
没有指定,只是定义了input_rdd来自于这个文件
task读取,转换分区成RDD数据,
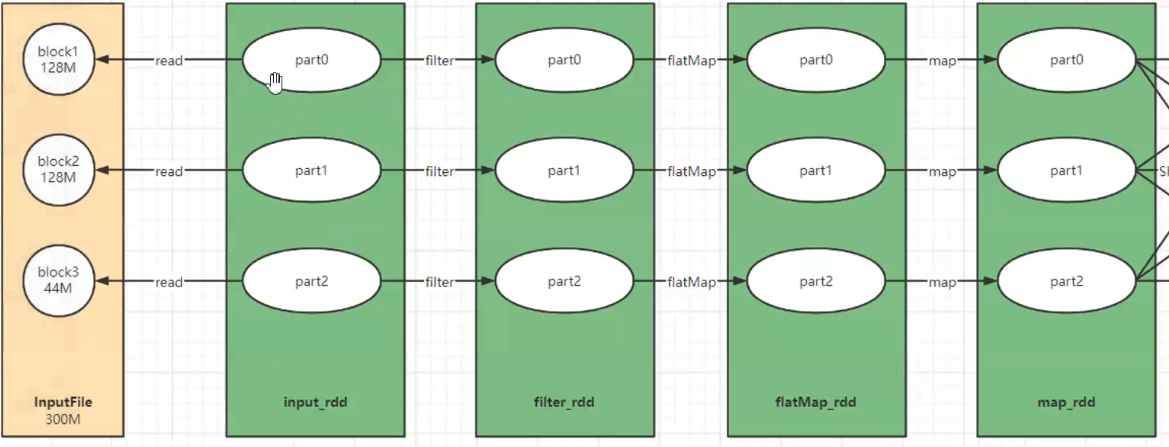
分块:文件的概念,HDFS
RDD分区是处理的结果
逻辑上的关系是一个分区对应一个Task
计算有几个分区由别的Task完成
就是实质上程序运行有两种task,一种来计算分区个数,一个是对分区数据进行处理
一个分区 = 一个计算Task :Executor
Split:分片/切片 = Partition:分区
优点:读写块
内存空间比较小,内存数据易丢失
不记录数据,记录操作,
领导要的时候才干,懒加载,

Hash分区器
优点:Key相同一定会进入同一个分区
缺点:容易导致数据倾斜
分配不均衡
轮询 随机

Hive中用分桶实现map join替代reduce join 避免reduce join过程中出现数据倾斜
group by 和 join count_distinct都能导致数据倾斜 group by/count(distinct) + join
distribut by rand()
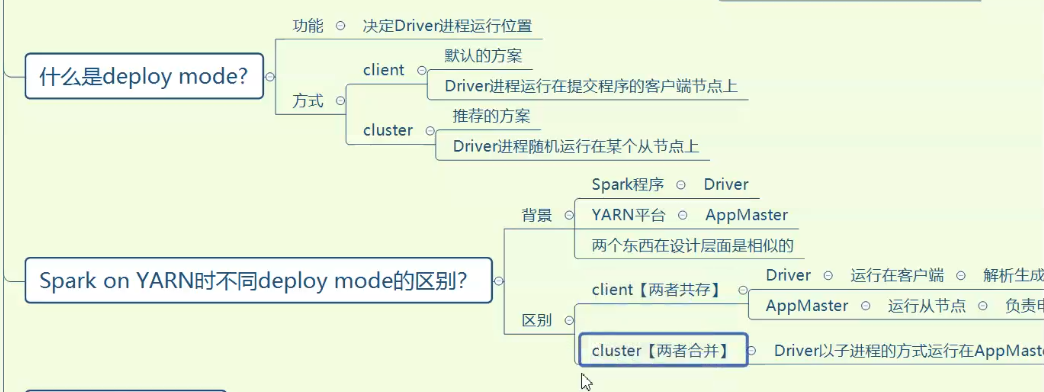
最优方案:将Task分配到数据所在节点上运行


全局分区,排序,需要shuffle,




minpartition=2:分区数一定 >= 2
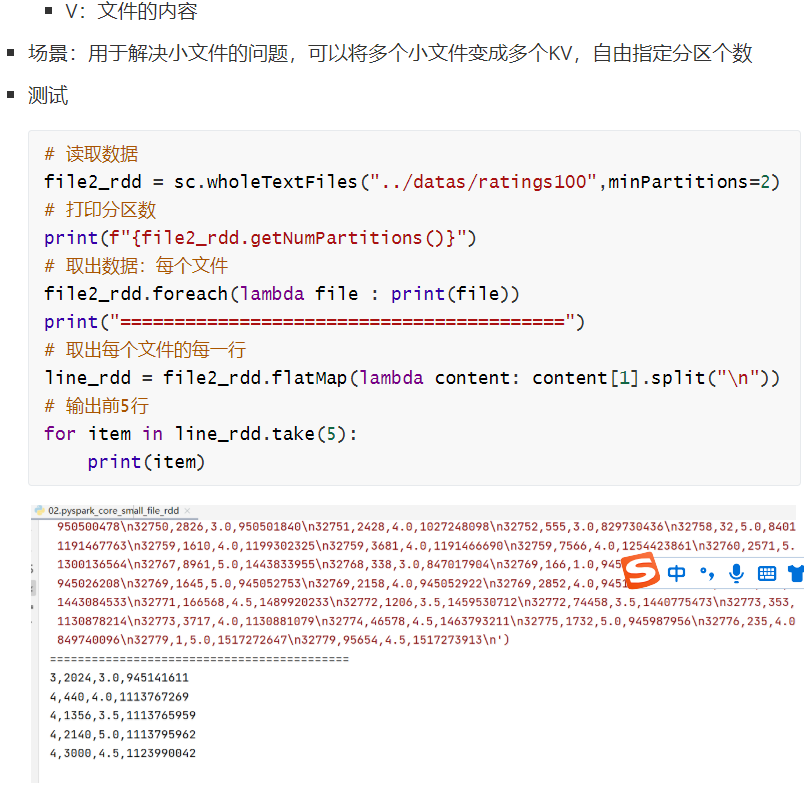
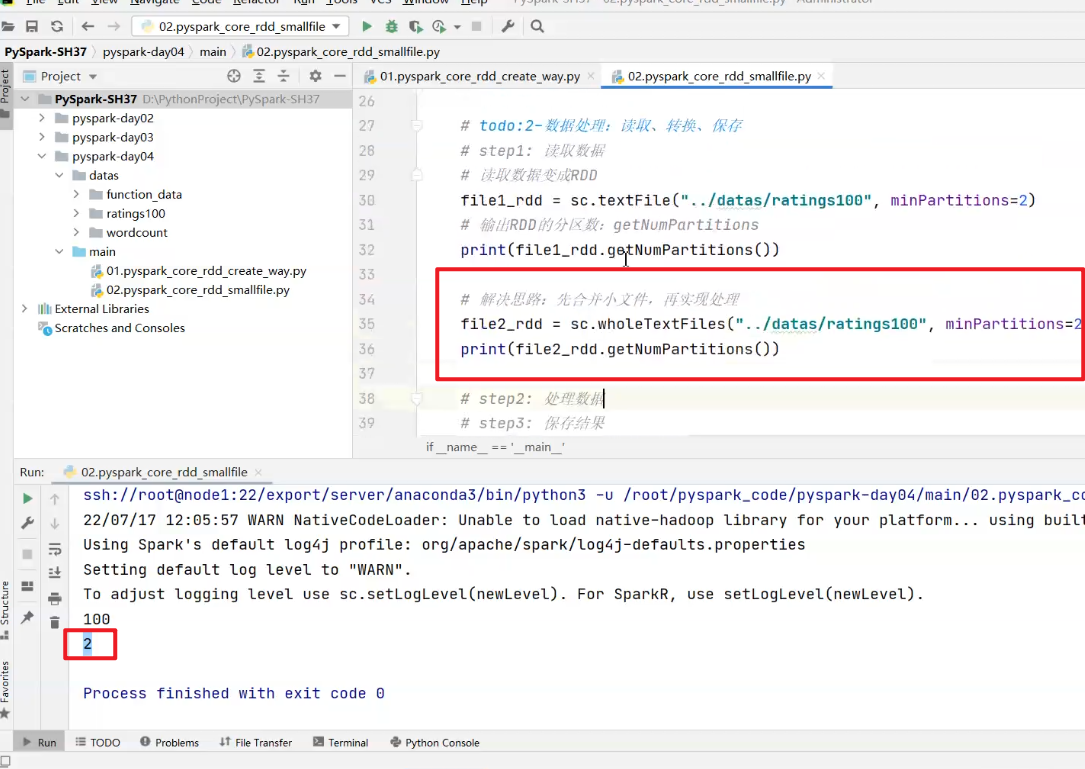

一个元素就是一个文件,一个文件中有多行
一个元素就是一行,一行有多个单词



shuffle

100分区,1亿条数据,统计每个小时的数据量
24


生产 根据大文件个数决定分区,
小文件多测试,
测试:指定为2
![]() 无爹,并行化集合,
无爹,并行化集合,
lazy模式:知道了但是暂时不做

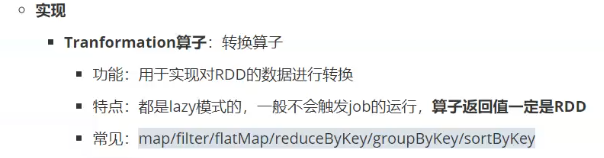





flatMap就是explode

一对一,一对多,


driver默认1g
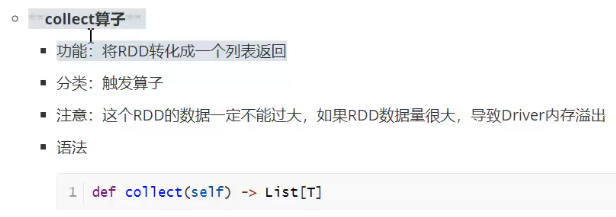
spark分区并行计算,


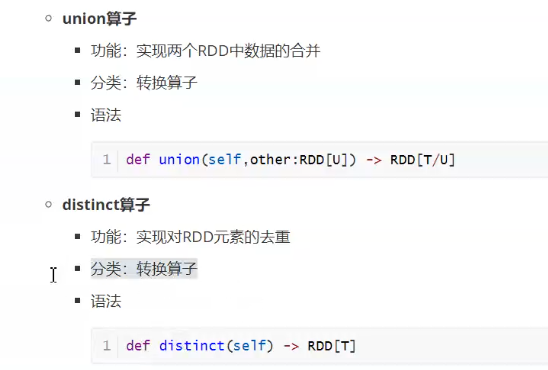
去重本质:全局分组

review,tonight,


preview







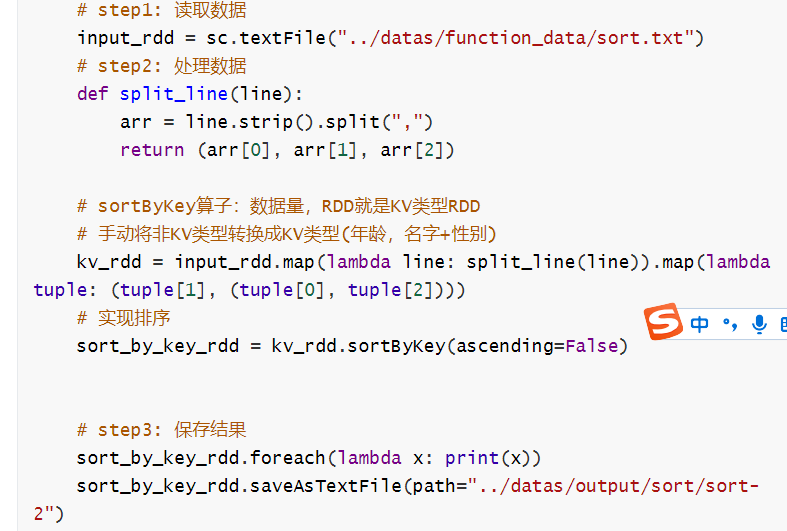



 明天把day05预习完???
明天把day05预习完???
# step1: 读取数据
input_rdd = sc.textFile("../datas/wordcount/word.txt")
# step2: 处理数据
tuple_rdd = ( input_rdd
.filter(lambda line: len(line.strip()) > 0)
.flatMap(lambda line: re.split("\\s+", line))
.map(lambda word: (word, 1))
)
tuple_rdd.foreach(lambda x: print(x))
print("=============================")
# 方案一:groupByKey先分组,再聚合
group_rdd = tuple_rdd.groupByKey()
group_rdd.foreach(lambda x: print(x[0], "------>", *x[1]))
print("=============================")
#map聚合
rs_rdd1 = group_rdd.map(lambda x: (x[0], sum(x[1])))
rs_rdd1.foreach(lambda rs: print(rs))
















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









