







Presto和Spark访问Hive中的数据表,进行数据处理
Hive中有哪些表、表对应的HDFS地址
Presto和Spark会解析Hive元数据吗
HiveServer2:Hive服务端,负责接收SQL、解析SQL转换成Hadoop任务
元数据是存储在数据库中
Metastore:元数据管理服务,负责管理元数据,实现元数据共享,接收所有读写元数据请求
1-共享元数据
2-解耦合保证元数据安全
HiveServer2:端口:10000
Metastore:端口:9083

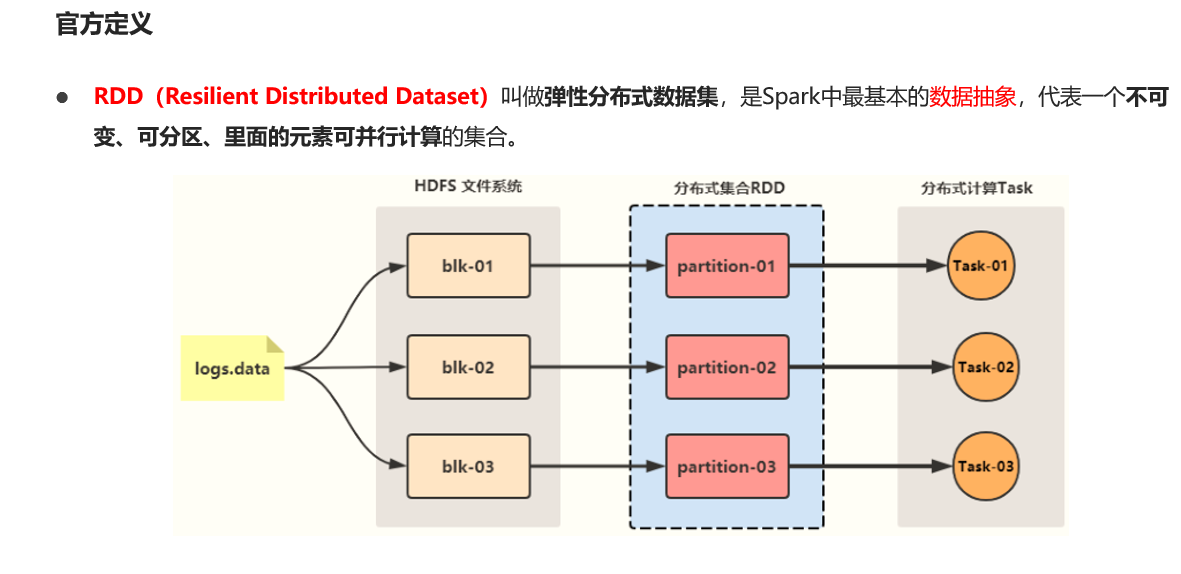
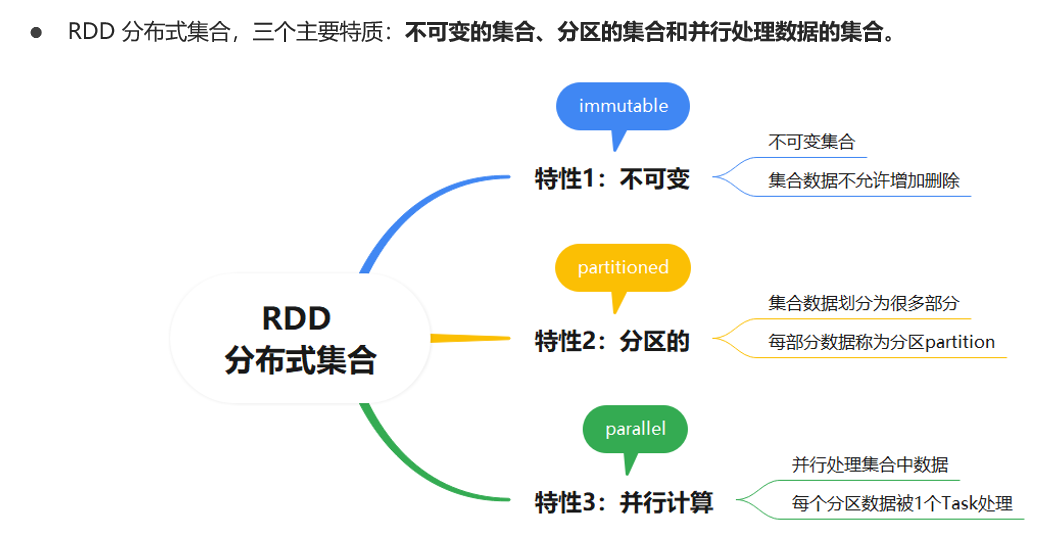
 RDD像HDFS中文件
RDD像HDFS中文件
一个RDD对应多个物理上的分区
一个文件对应多个物理上的Block

5个rdd,
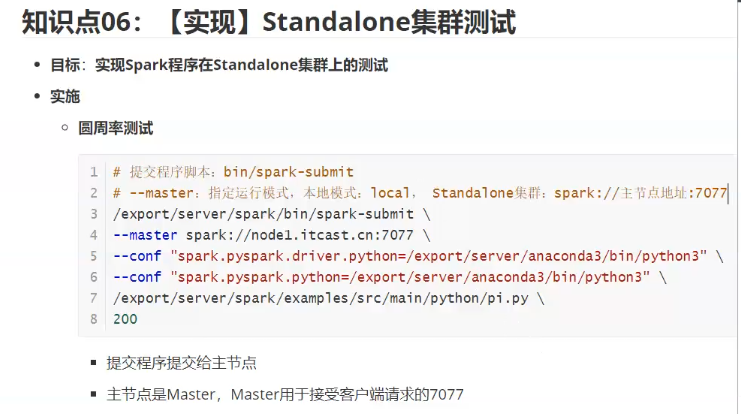
spark-submit
Active,Standby

ZK的主节点故障,允许从其他从节点中选举一个新的主节点
zk中,Leader故障,Follower选举成为新的Leader

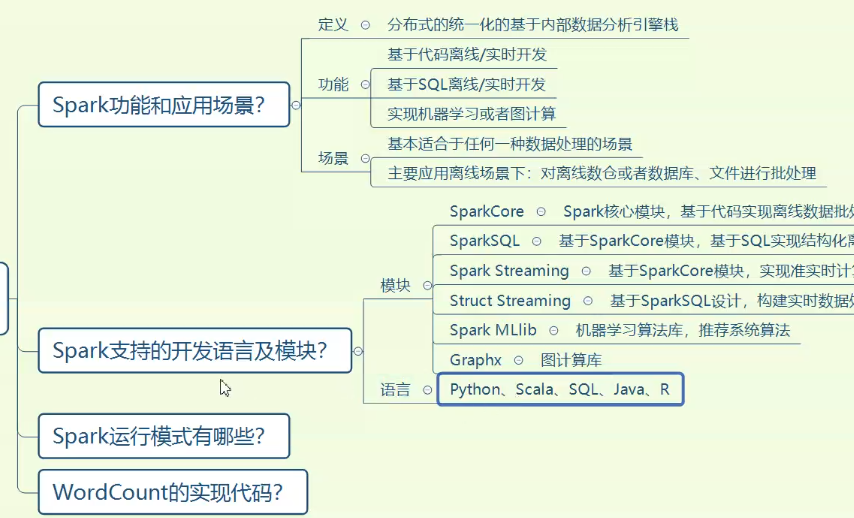
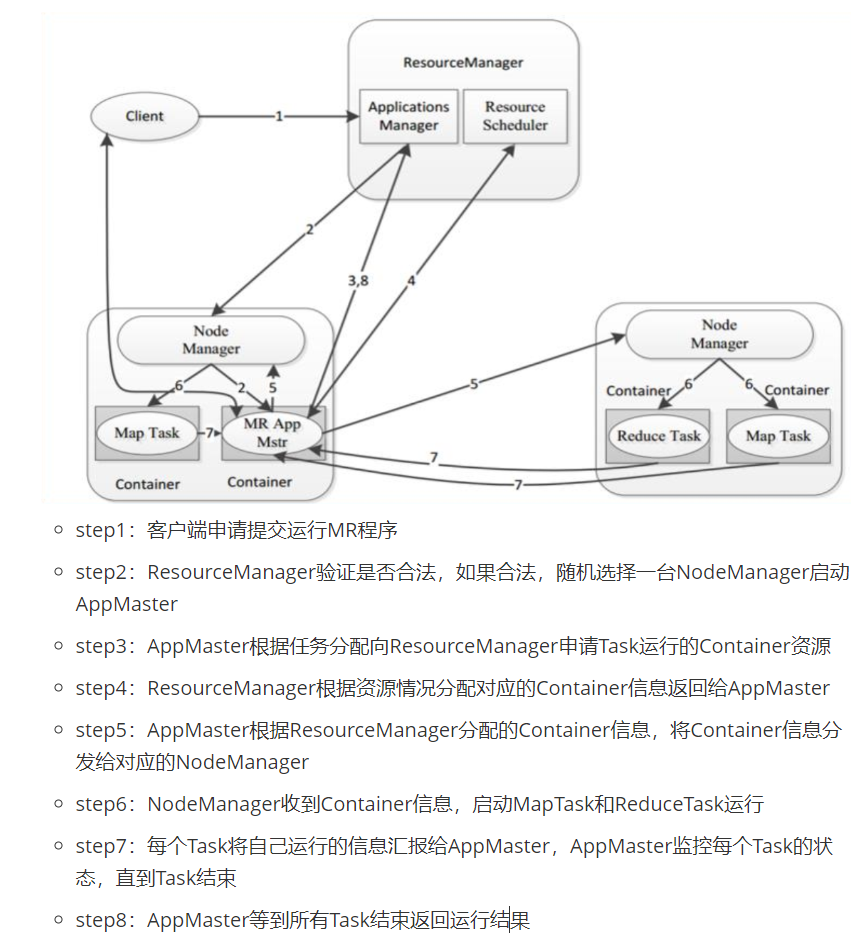
MapTask进程、ReduceTask进程
 软连接==快捷方式
软连接==快捷方式
vim中,i or o

vim命令行60直接跳到
markdown:用于复制内容
PDF:用于看笔记
![]()
8088
MapReduce:JobHistoryServer 19888端口
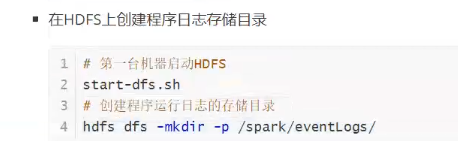
用于记录运行过所有MR的程序的日志
Spark:HistoryServer
sbin集群管理,

所有日志文件名中:一定会包含进程名字
哪个进程有问题,就看哪个进程日志文件
Spark:Master:8080 集群监控,
JobhistoryServer:19888
HistoryServer:18080

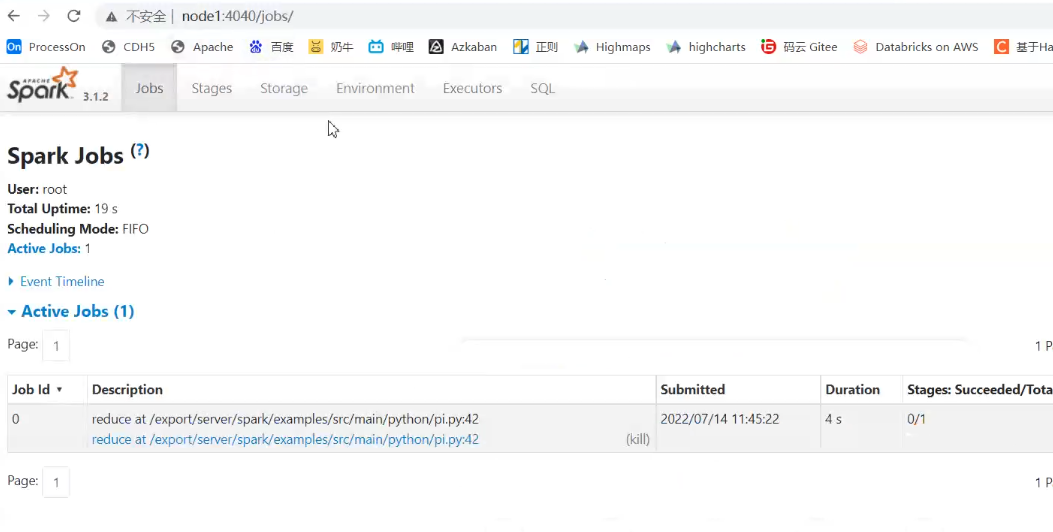
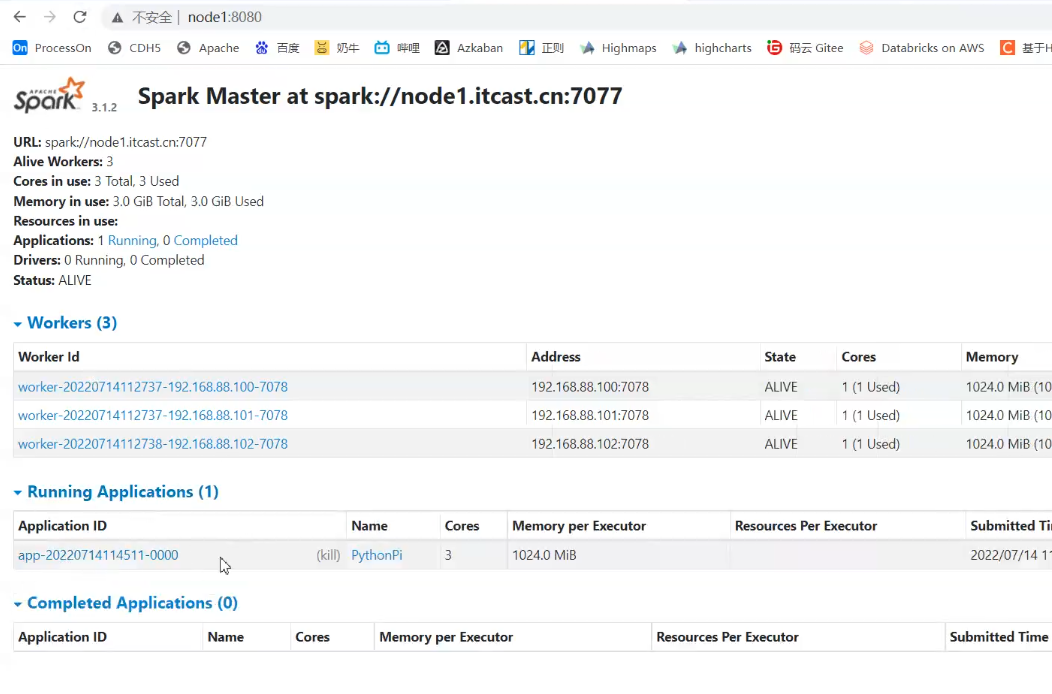
执行完了,端口4040释放,
1个Driver:驱动进程
任何一个Spark程序都由两种进程组成:Driver-驱动进程和Executor-计算进程
Driver负责解析生成、调度分配Task
Driver高度类似于YARN中的APPMaster
APPMaster + MapTask/ReduceTask
Driver + Executor
MapTask/ReduceTask==container==Executor
集群模式:HDFS
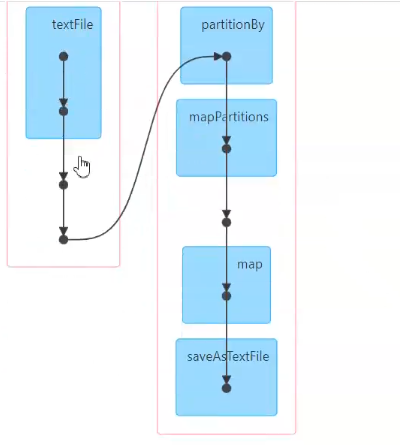
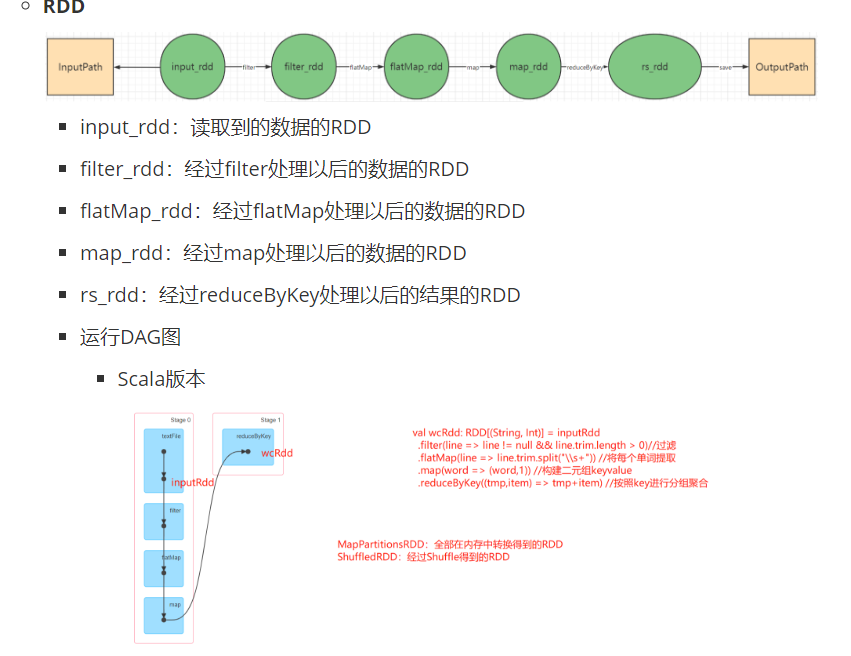
曲线==shuffle
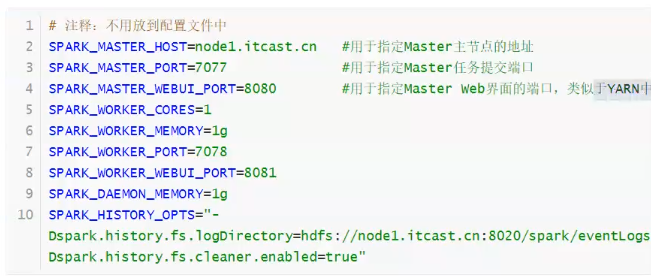
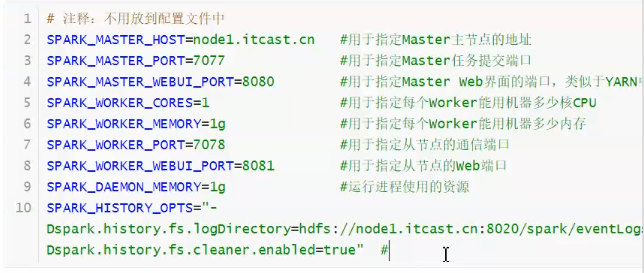
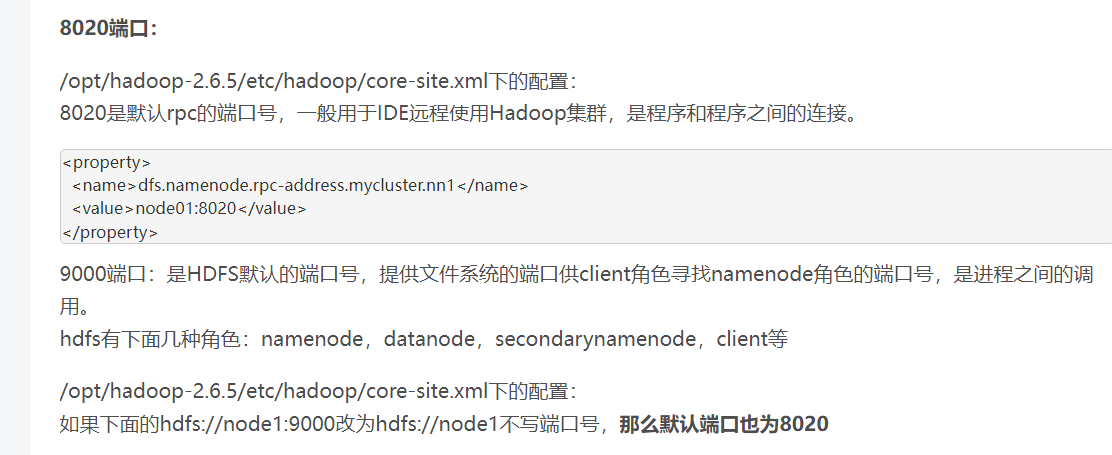
改端口,一定修改配置文件,配置文件中一定会有
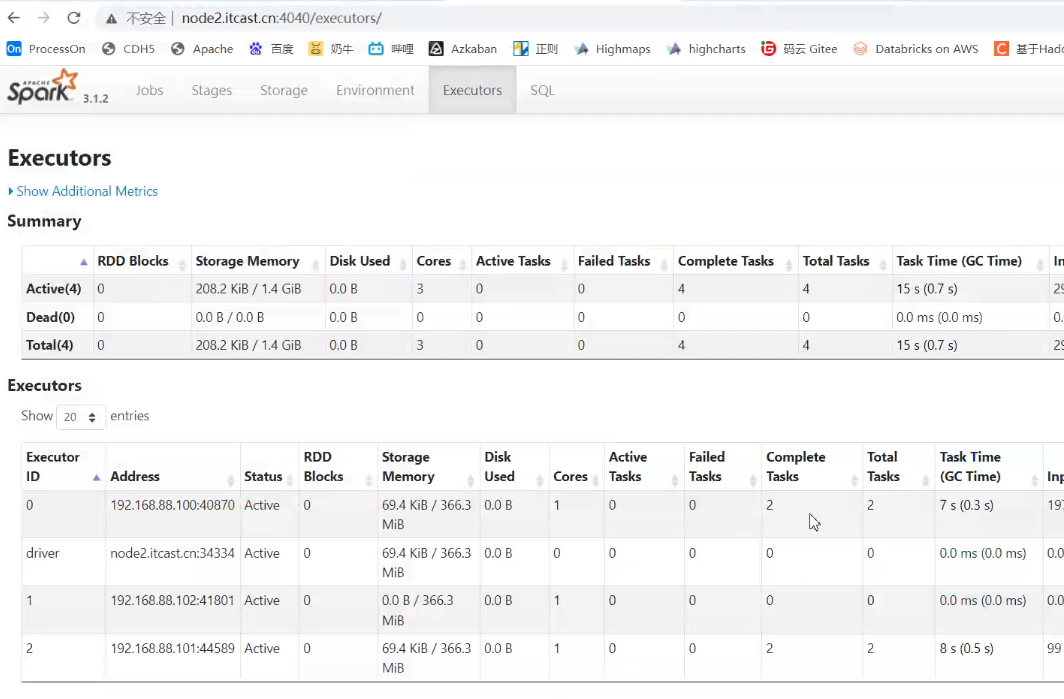
Task会优先分配到数据所在机器运行
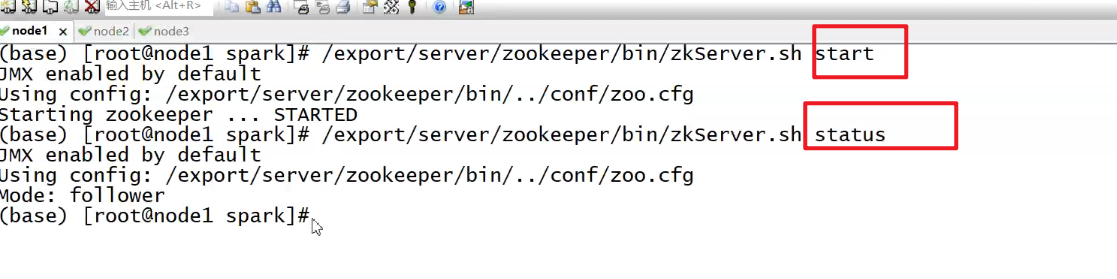
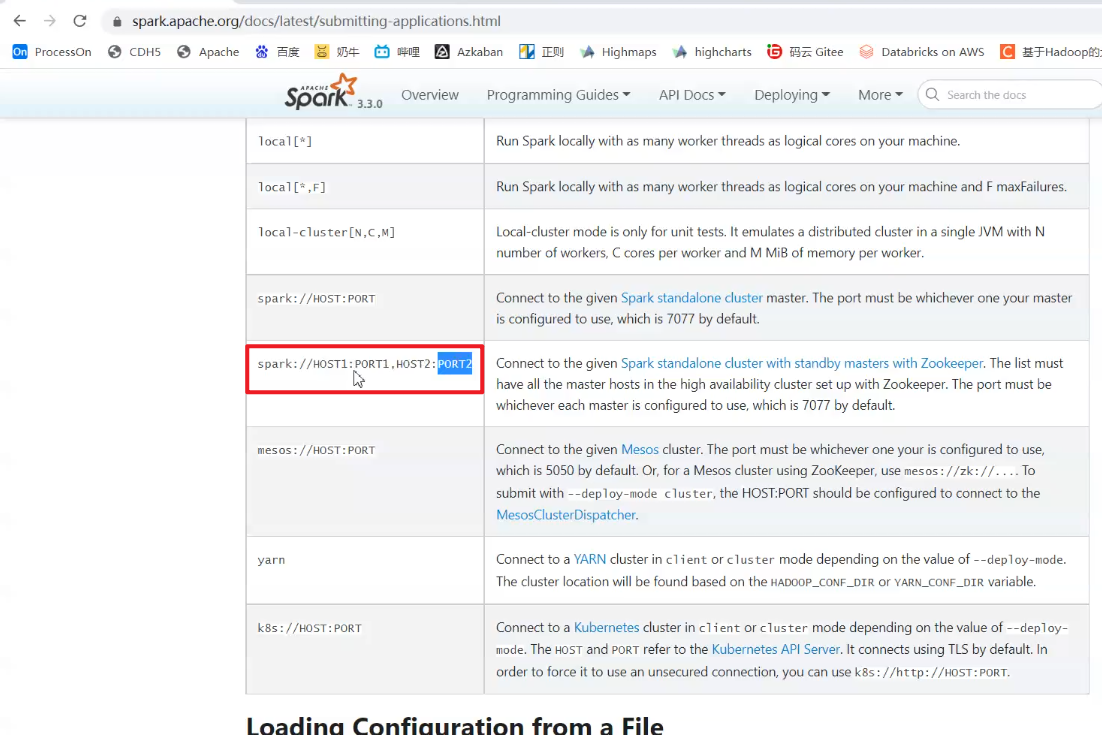
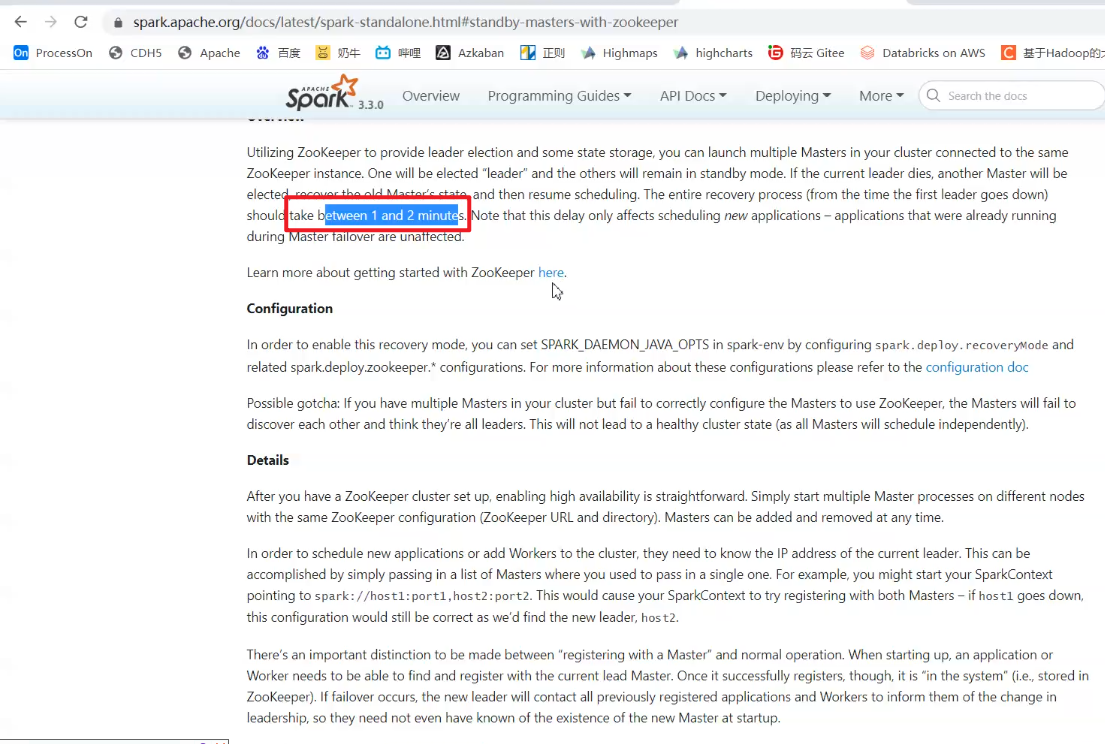
后面不用高可用ha,
![]()
先到先得
![]()
![]()


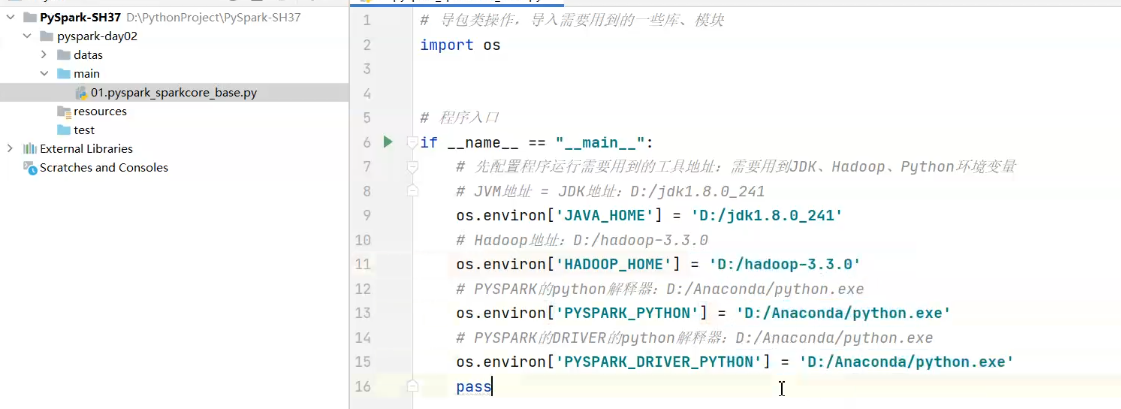
程序运行需要用到JVM、Python解释器、Hadoop命令
注意解压是否嵌套???



任何一个Spark程序都由:Driver+Executor
Executor:执行Task
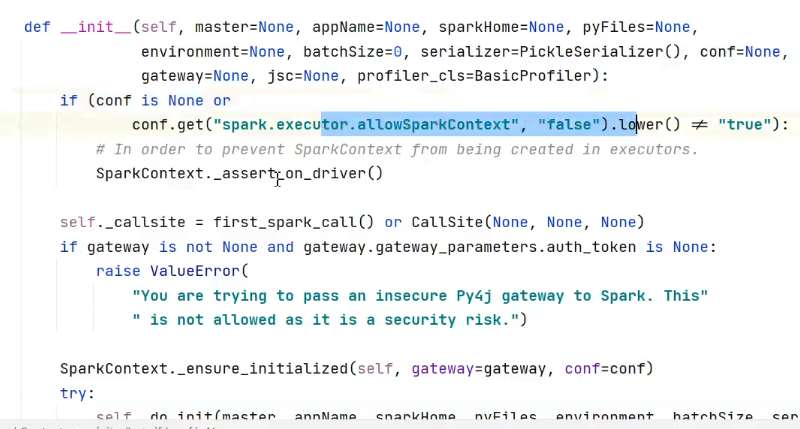
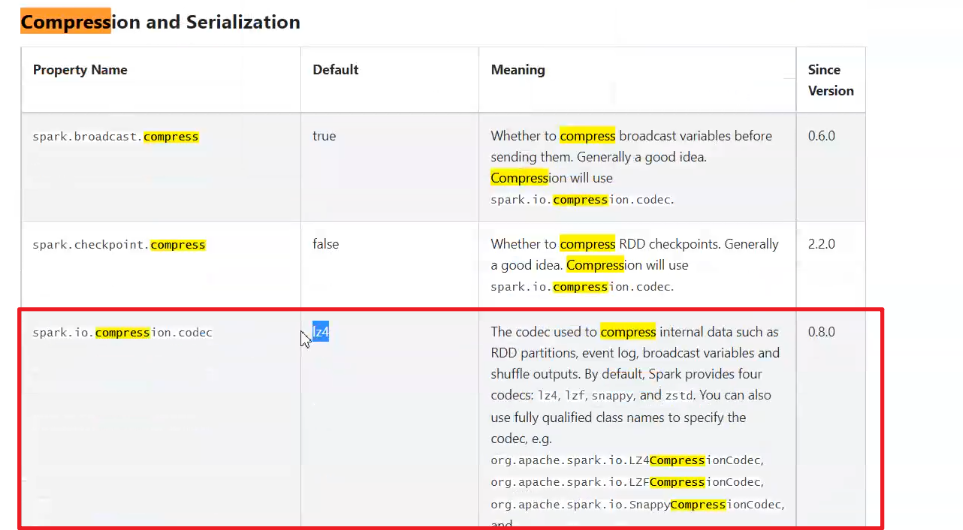

怎么看源码
ctrl+鼠标左点击,
多敲两三天,再用模板,
括号(可注释)==加反斜杠,

spark-submit
localost:4040 Windows下
18080 linux下,
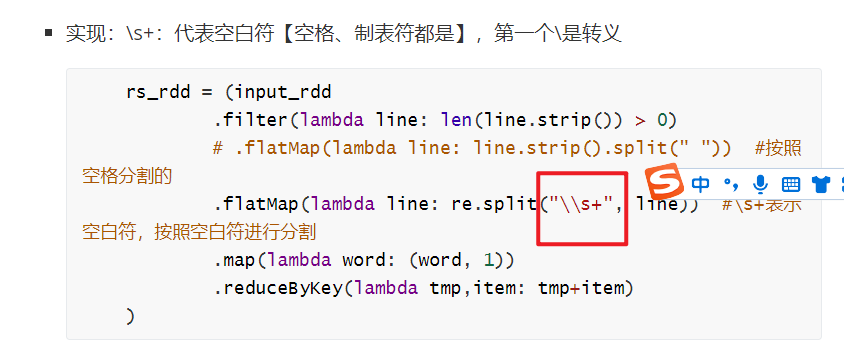

如果存在会报错:Output Directory already exists
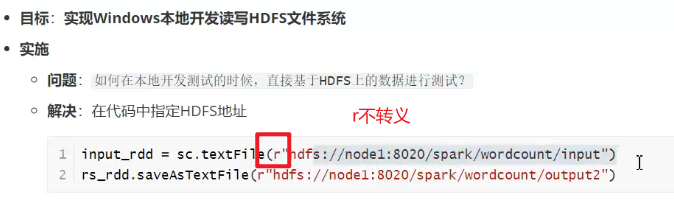
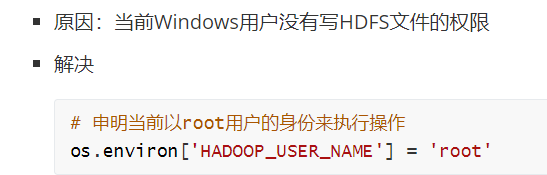

 注意:输出目录不能提前存在
注意:输出目录不能提前存在
参数可以提供代码的灵活性
阶段是全局编号,
本地模式:只启动1个进程来运行所有Task
Spark程序:Application
每个Application有一个监控端口4040开始
每个Application中可以包含多个job

Spark是基于内存计算,为了避免资源浪费

同一个阶段中所有操作直接在内存中完成

熟练编写Wordcount
review




preview







已看完::::::::::

















 2428
2428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









