







论文笔记-arXiv2024-Large Language Model Interaction Simulator for Cold-Start Item Recommendation
LLM-InS:用于冷启动项目推荐的大语言模型交互模拟器
论文下载链接:https://arxiv.org/pdf/2402.09176
摘要
推荐冷启动项目对于协同过滤模型而言是一个长期存在的挑战。现有的冷启动模型使用映射函数根据冷启动项目的内容特征生成行为嵌入。然而,生成的行为嵌入与真实的行为嵌入有显著差异,会对推荐性能产生负面影响。
为了应对这一挑战,本文提出了LLM交互模拟器LLM-InS,基于内容方面对用户的行为模式进行建模。这个模拟器可以模拟每个冷启动项目的交互,将冷启动项目转换为热启动项目。
1.引言
1.1挑战
当前的冷启动方法依赖于“模拟嵌入”,存在以下局限性:
-
不同的嵌入逻辑:生成的嵌入是根据内容特征嵌入的,而行为嵌入是根据用户和项目的交互进行训练的。
-
内容建模不足:简单的NLP方法不能充分利用内容特征。
大语言模型在冷启动推荐中应用存在以下挑战:
-
共同推荐冷热项目:冷启动项目与热启动项目使用相同的方式和评分分布进行推荐。
-
行为嵌入生成:LLM难以生成与推荐系统一致的嵌入。
1.2贡献
传统模型生成嵌入和行为嵌入在推荐冷启动项目时会遇到性能下降问题,本文针对这一问题提出LLM-InS。
主要贡献如下:
-
修改大语言模型的结构和训练目标,不仅为用户和项目嵌入提供推理能力,而且还能准确模拟成对交互。
-
引入一种有效的“过滤和优化”方法来模拟冷启动项目的交互。
-
提出一种基于模拟和真实交互相结合的项目嵌入更新方法,确保更新过程全面有效。
2.相关工作
当前的冷启动模型将冷启动项目的内容映射到嵌入,然后将其与从热启动项目获得的行为嵌入对齐。基于对齐方向可以分为两类:
-
嵌入dropout模型,旨在通过dropout方法将热启动项目的行为嵌入与冷启动项目的内容生成嵌入对齐。
-
嵌入生成模型,其目标是将冷启动项目内容映射的嵌入朝着热行为嵌入的方向对齐。
3.预备知识
3.1符号
用户和项目集分别表示为U和I,用户和项目之间交互的集合由H表示。历史交互计数大于零的项目被称为热项目并表示为Iw,嵌入表示为EIw。历史交互为零的项目被称为冷项目并表示为Ic,内容嵌入表示为EIc。
对于每个冷启动项目i,使用交互模拟器Sim生成模拟交互In。为了快速生成交互,预先计算一个用户候选集Cu,包含最有可能与冷启动项目产生交互的用户。原始LLM表示为Lo,将训练后的LLM表示为Lt。
3.2问题定义
冷启动推荐
参考ALDI定义三个任务:所有商品、冷启动商品和热启动商品的推荐任务。
总体任务Rall是指根据所有项目的预测分数对所有项目进行预测的推荐任务,表示为:
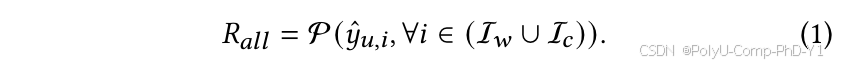
类似地,热启动推荐表示为:
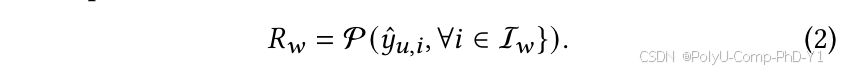
冷启动推荐表示为:
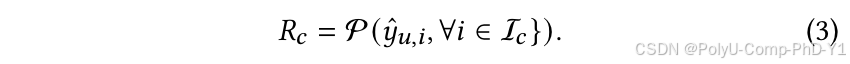
交互模拟
收集给定用户的历史交互来模拟该用户是否可以与给定的冷启动项目进行交互。给定用户的历史行为𝐵𝑢={𝒄𝑢,1,···,𝒄𝑢,|𝐵𝑢|},模拟器Sim可以表示为:
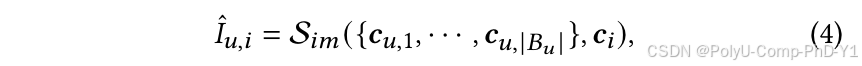
其中,𝐼𝑢,𝑖表示是否用户u是否会和项目i交互的预测。对于没有交互作用的冷启动项目,需要模拟足够的交互作用。因此,对于每个用户u∈Cu ,交互模拟器Sim需要模拟是否会发生交互。
对候选集中的所有用户进行交互模拟后,将模拟产生交互的用户组合起来形成交互集In:
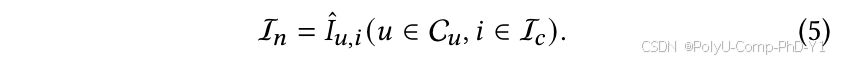
4.LLM-InS
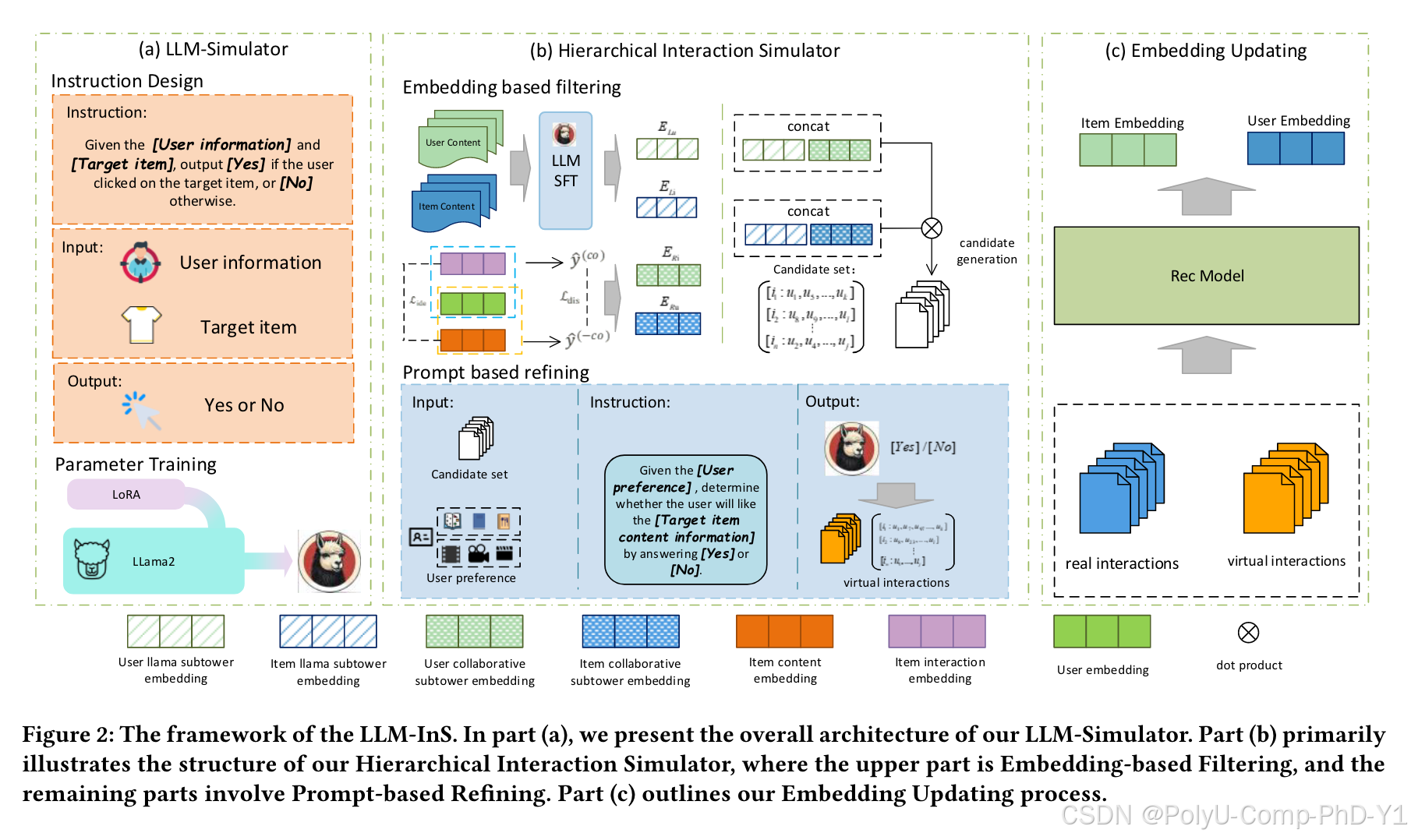
4.1LLM模拟器
本文通过基于提示的训练来模拟项目和用户之间的交互。提示设计遵循TALLRec的训练方法,包含指令、输入和输出。
通过利用自回归损失并使用Lora进行参数更新,确保训练好的LLM遵循预定义的输出格式并最大限度地提高模拟交互的真实性。优化函数如下:
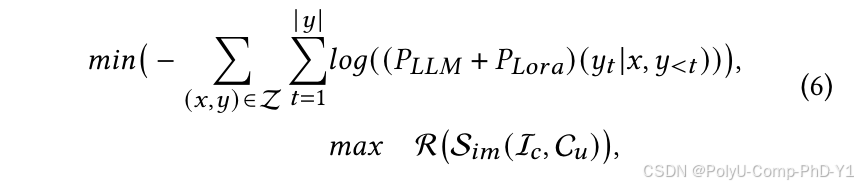
其中,R表示模拟器生成的交互的真实配对率。
4.2层次化交互模拟器
本文提出了一种模拟交互的方法,过滤并选择有限数量的潜在用户候选者来模拟交互。基于嵌入的过滤模拟器能够同时利用语义和协作空间来选择候选用户。此外,为了更好地利用LLM的能力,本文设计了一个基于提示的优化模拟器,通过设计提示和询问LLM来完善交互模拟。
4.2.1基于嵌入的过滤模拟器
为了更好地实现嵌入级别的过滤,提出Llama Subtower表示语义空间建模,以及使用协作空间进行嵌入过滤的Collaborative Subtower,最后合并两个嵌入进行整体过滤。
这一步涉及的公式运算较为复杂,建议查看论文page5。
4.2.2基于提示的优化模拟器
通过构造提示,设计冷启动项目的内容信息与用户内容信息之间的交互,模拟问答形式的交互。具体来说,使用用户的历史交互作为用户的内容信息,而项目的信息由项目的内容来表示。该提示可以表述如下:
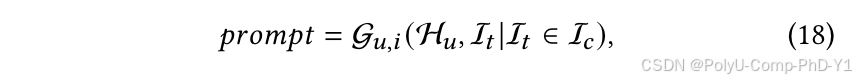
其中Gu,i表示提示的生成函数,Hu表示用户历史交互项内容,It表示目标冷启动项目。将提示输入LLM后,得到的输出作为该提示的标签,表明是否点击。
5.实验
5.1设置
数据集:CiteULike and MovieLens
基线:
-
基于Dropout的嵌入模拟器:DropoutNet 、MTPR和 CLCRec。
-
生成嵌入模拟器:DeepMusic、MetaEmb 、GPatch、GAR、UCC和ALDI。
-
基于LLM的推荐:ChatGPT3、TALLRec和 LLMRec。(5.4实验中使用)
评估指标:Recall@K 和 NDCG@K
5.2实验结果
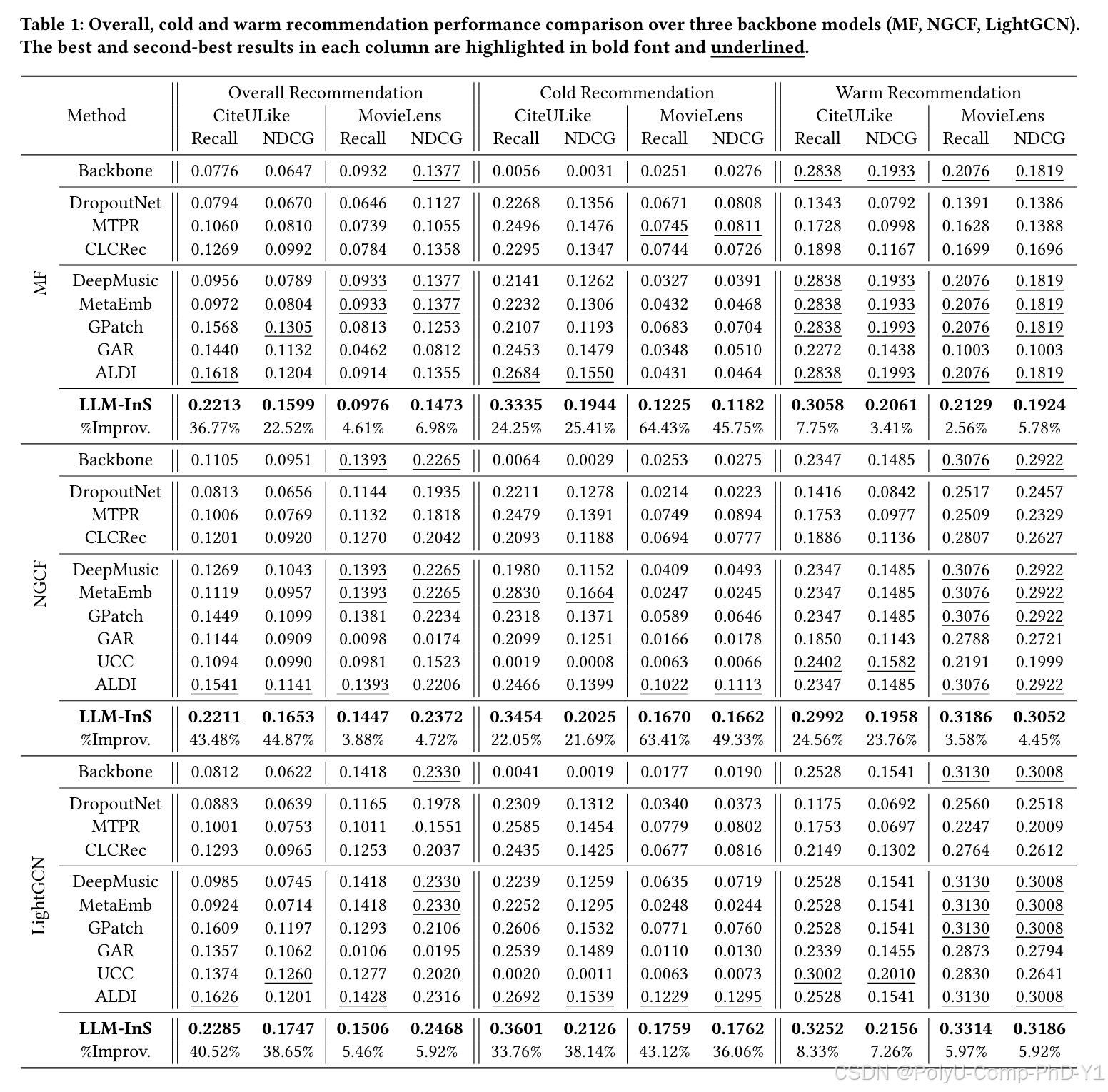
结论:
-
LLM-InS在整体、冷启动和热启动推荐性能方面均优于所有嵌入模拟基线模型。
-
生成嵌入模拟模型在热推荐和整体推荐方面通常比dropout嵌入模拟模型表现更好。
5.3消融实验
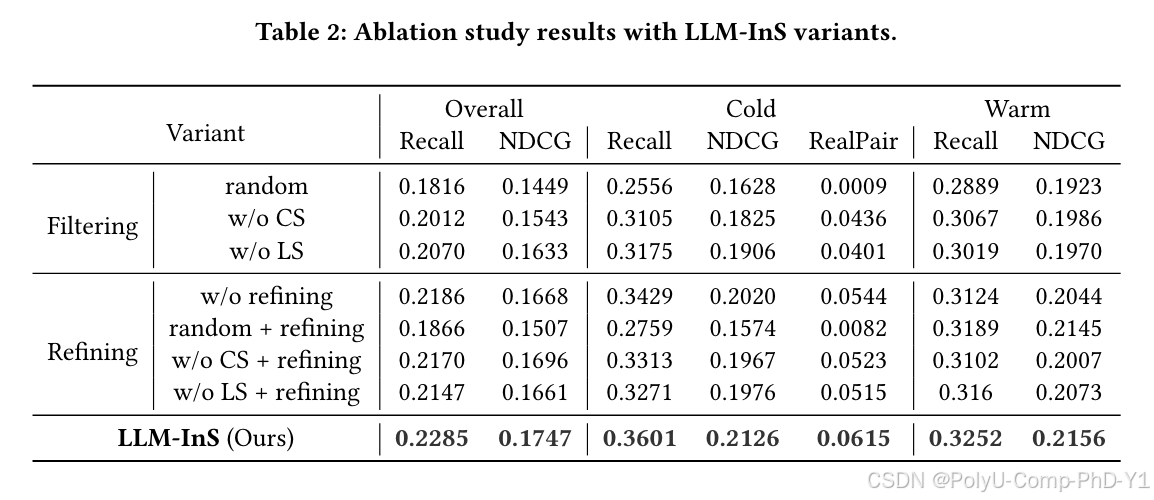
结论:
-
过滤阶段的有效性
-
随机选择一定数量的用户来构建与冷启动项目的交互,召回率和NDCG指标都会显著下降。这表明如果没有过滤和细化阶段,LLM-InS无法获得相对真实和可靠的用户-项目对交互。
-
在没有CS和没有LS的情况下,只有一个subtower处于过滤阶段并且没有进行细化,所有场景中的指标都显示出不同程度的下降。这表明只有一个subtower可以从语义或协作空间捕获部分信息,但是嵌入向量并不全面。
-
-
优化阶段的有效性
-
相对于经过优化的LLM-InS,没有优化的变体的评估指标有所下降。这表明优化阶段通过LLMSimulator有效地细化了用户候选集,提高了RealPair的比率。
-
与没有优化的过滤阶段的三个消融实验(如随机+优化、无CS+优化和无LS+优化)相比,表2中的消融指标显示优化后有所改善。这表明通过提示结合语义空间细化的细化阶段可以有效提高整体性能。
-
5.4大模型实验
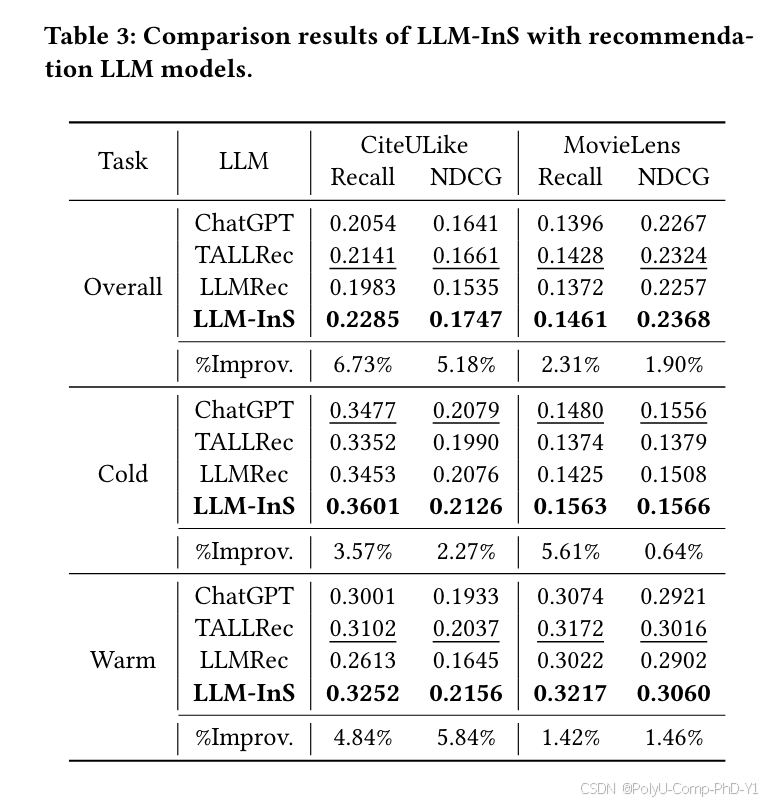
结论:
LLM-InS在总体推荐、冷推荐和热推荐方面总体优于当前所有LLM模型。这表明,通过LLM模拟器训练以及过滤和优化阶段,LLM-InS可以有效地将推荐任务与LLM结合起来。实验结果证明了模型在冷启动项目推荐方面的有效性。
6.结论
针对冷启动推荐场景中冷启动项目和热启动项目之间巨大的嵌入差距,提出了一种新颖的LLM-InS,通过利用来自热启动用户和热启动项目的模式,为冷启动项目模拟真实交互,从而克服了传统冷启动模型“嵌入模拟器”的限制。
LLM-InS的创新包括:基于大语言模型的筛选、优化和更新阶段。首先通过在内容和协作空间中共同建模用户-物品关系,识别冷启动项目的潜在用户候选者。然后,通过使用经过微调的LLM进行优化处理,从而确定虚拟交互。最后,在更新阶段,LLM-InS基于这些模拟和真实交互,在一个统一的推荐模型中训练冷启动和热启动项目。

















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









