







论文笔记-WWW2024-Harnessing Large Language Models for Text-Rich Sequential Recommendation
LLM-TRSR:利用大语言模型进行丰富文本的序列推荐
论文下载链接: LLM-TRSR
1.摘要
当推荐场景的项目包含丰富的文本信息,比如网购中的产品描述或者社交媒体中的新闻标题,LLM需要长文本才能全面描述用户的历史行为序列。这就带来了以下挑战:
-
文本长度限制:比如GPT-2限制1024 tokens。
-
大量时间和空间开销:Tranformer架构的复杂度是O(n^2),较长的文本会消耗大量的计算资源。
-
次优的模型性能:较长的文本会使模型难以有效捕获用户偏好的变化,从而无法获得最佳性能。
针对以上问题,提出了LLM-TRSR,如图:
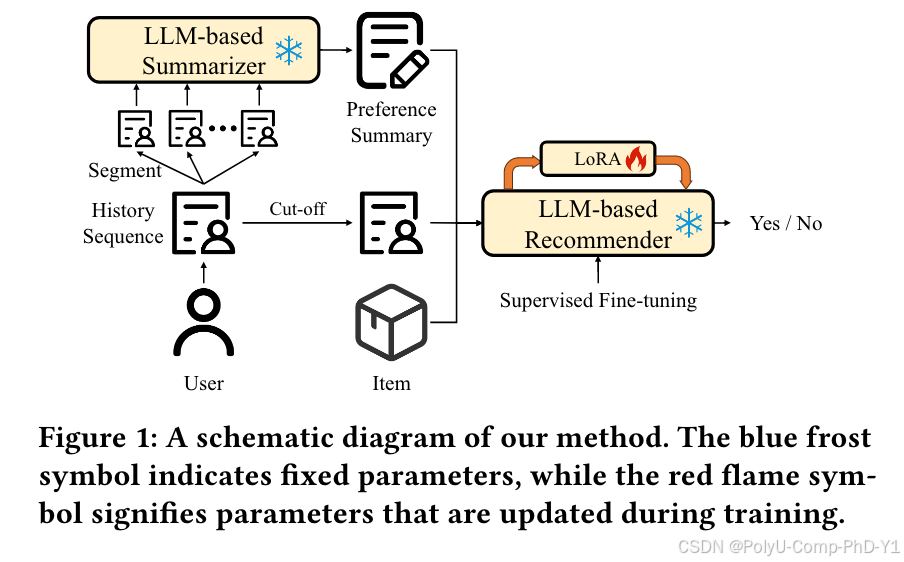
主要包括:
-
对用户历史行为进行分段,采用基于LLM的摘要器总结用户行为块。受CNN和RNN启发,引入两种独特的摘要技术,分别是分层摘要和循环摘要。
-
将包含用户偏好摘要、最近用户交互和候选项目信息的提示文本构建到基于LLM的推荐器中,然后使用SFT技术对其进行微调,生成最终推荐模型。
-
使用LoRA进行参数高效微调,减少内存开销并加快训练过程。
2.相关工作
2.1序列推荐
现有的序列推荐模型主要采用RNN或Transformer等序列建模技术来表示用户行为序列,比如GRU4Rec和BERT4Rec等。
考虑到推荐项目中可能包含丰富的辅助信息,一些研究针对文本丰富的序列推荐场景添加了额外的模块,比如TempRec等。
2.2大语言模型
大语言模型由数千万到数万亿个参数的神经网络组成,使用自监督或半监督学习等方法对大量未标记文本进行大量训练。
大语言模型可以分为两种不同的类型,分别是判别性LLM和生成性LLM。对于判别性LLM, BERT引入了双向转换器架构,并建立了用于模型预训练的掩码语言模型MLM的概念。对于生成式 LLM,GPT首先提出通过预测句子中的下一个单词来预训练模型。
本文选择Llama模型作为摘要器和推荐器。
2.3 LLM4Rec
现有关于大语言模型在推荐系统中的研究可以分为两类:用于推荐系统的判别性LLM和生成性LLM。此外,建模范式可以分为三类:LLM嵌入+推荐系统、LLM标记+推荐系统,以及LLM作为推荐系统。
本文的方法主要利用两种不同的生成式LLM进行推荐,结合了LLM标记+推荐系统范式和LLM作为推荐系统范式。
3.LLM-TRSR
3.1基于LLM的分层用户偏好摘要
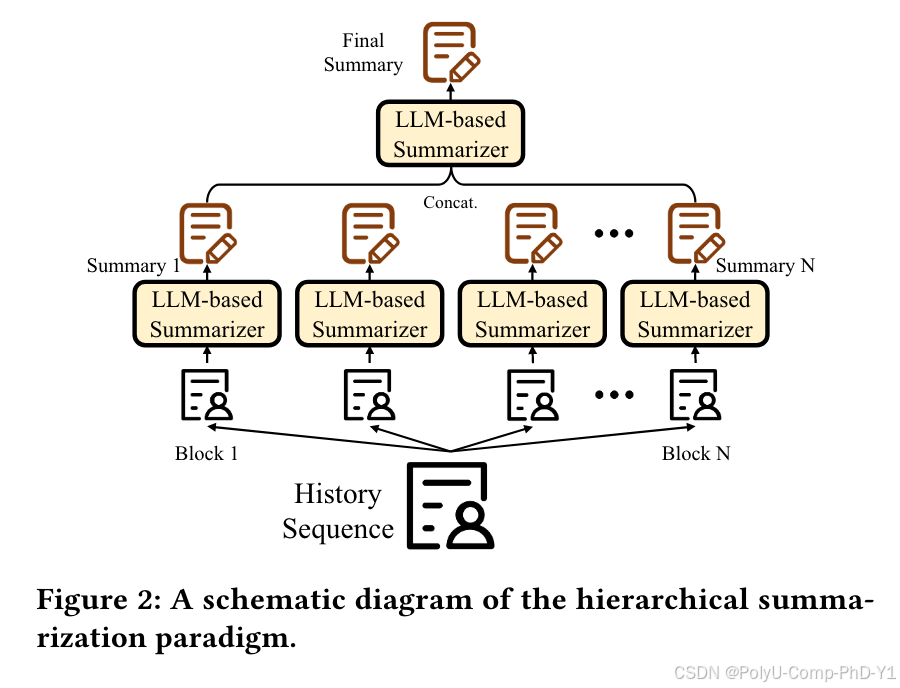
首先对文本进行分段,确保每个块包含与少数项目相关的信息。然后,使用Llama-30b-instruct生成每个文本块的摘要。最后将每个块的摘要输入LLM并指示其进一步总结这些摘要,产生用户偏好的全面摘要。
这个过程与卷积神经网络CNN以分层方式提取更高级别的特征非常相似。下图为分层摘要的示例,示例中仅使用两层就获得了行为序列的最终摘要。实际应用中可以进一步扩展层的数量,就像在卷积神经网络中添加层一样。从理论上讲,这种方法允许处理包含无限数量项目信息的行为序列。

3.2基于LLM的循环用户偏好摘要

首先将用户行为序列文本分割成块,提取第一个块的摘要。然后将前一个块的摘要和下一个块的用户行为输入到基于LLM的摘要器中,以生成更新的摘要。该过程迭代执行,直到所有块结束,从而产生最终的用户偏好摘要。
如图为循环摘要的示例:

3.3基于LLM的推荐
获得用户偏好的摘要后,使用监督微调SFT的方法来训练基于LLM的推荐模型。

如图所示,构建一个提示文本,由以下五个部分组成:
-
推荐指令:其作用是指示LLM同时考虑偏好摘要和用户最近的行为来完成推荐任务。推荐任务的结构为“是”或“否”的输出。
-
偏好摘要:源于前面提到的分层摘要范式或循环摘要范式,用于表示用户的长期兴趣。
-
最近的用户行为:包括用户最近交互过的项目,表明用户的短期兴趣。
-
候选项目描述:提供候选项目的所有文本属性。
-
最终答案:表示用户是否与该项目进行交互。
使用SFT损失训练基于LLM的推荐器:
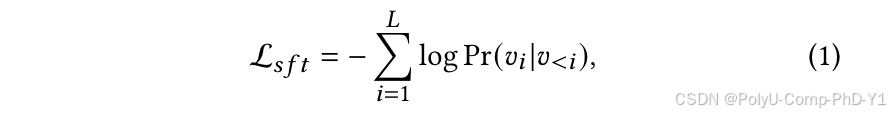
其中,vi是提示文本中的第i个单词,L是提示文本的长度,Pr()由LLM模型根据下一个token预测范式计算。在训练过程中利用低秩适应(LoRA)进行高效的参数微调(PEFT),减少可训练参数的数量。
训练阶段完成后,在测试阶段删除提示文本末尾的“是”或“否”。然后,将这个修改后的提示输入到大语言模型中,并获得模型预测的下一个单词的概率:
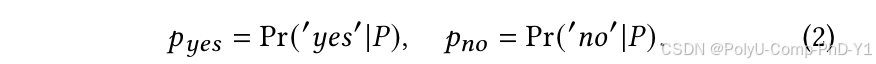
最后,使用softmax函数计算交互概率:
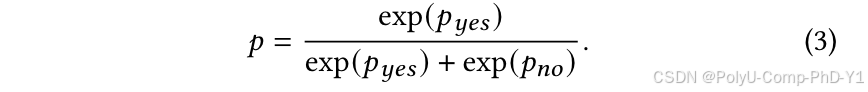
4.实验
4.1设置
数据集:用于产品推荐的Amazon-M2数据集和用于新闻推荐的MIND数据集。
基线:传统方法包括NCF、DIN;先进方法包括DIEN、GRU4Rec、CORE、NARM、SASRec;基于LLM的方法:TALLRec。
评估指标:Recall@K和MRR@K,K可以为3、5和10。
其他:选择具有8位量化的Llama-30b-instruct作为摘要器,并选择具有BF16的Llama-2-7b作为推荐器。
4.2对比实验
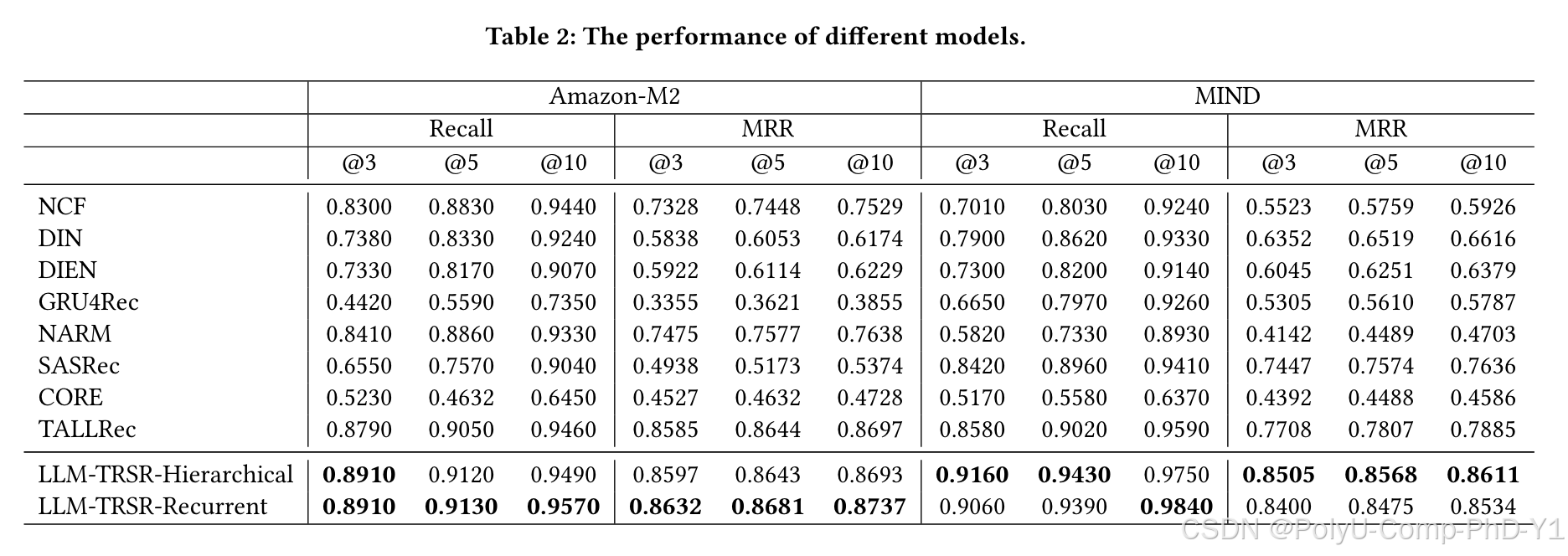
结论:
(1) LLM-TRSR在不同的评估指标和不同的数据集上的性能超过了所有基线方法,证明了有效性。
(2) 基于LLM的推荐方法始终优于传统方法,强调了LLM在序列推荐系统领域的巨大潜力。
(3) 在Amazon-M2数据集上,LLM-TRSR-Recurrent优于LLM-TRSR-Hierarchical,而在MIND数据集上则相反。这表明总结用户偏好的不同范式可能适合不同的场景。例如,循环摘要可以更有效地捕获用户偏好转变,而分层摘要可以更好地捕获用户的总体兴趣。
4.3历史项目数量设置
不同的历史项目数量可能会影响实验结果,如图所示:
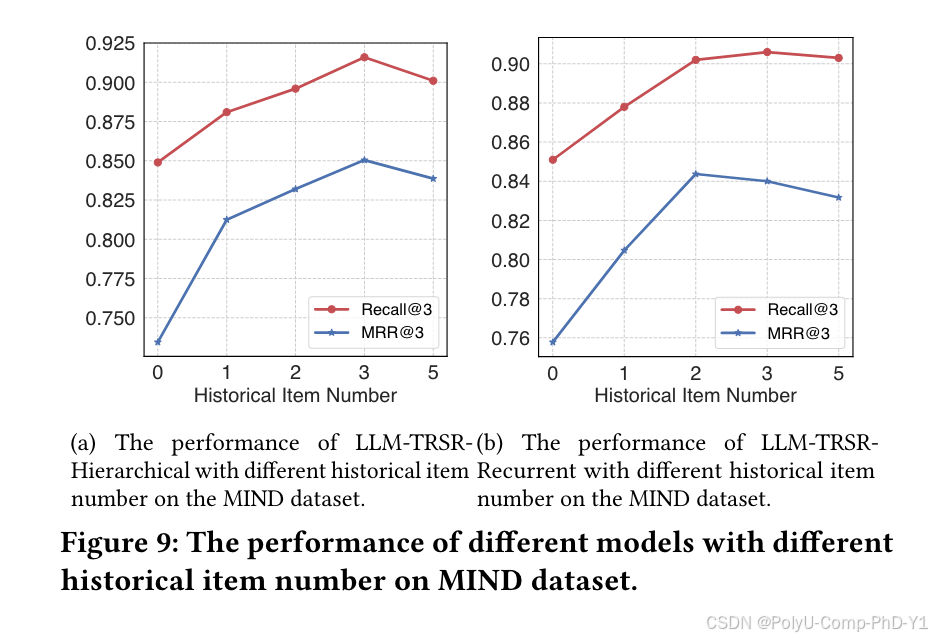
当数量设置为3,性能达到最佳。这表明历史项太少或太多都不利于提高模型性能。此外,即使历史项目的数量设置为0(这意味着模型仅根据用户偏好摘要进行推荐),它仍然可以获得相当好的性能。这强调了方法的有效性。
4.4参数设置
(1)推荐器参数大小设置
本文选择Llama-2-7b作为基于LLM的推荐器的骨干模型。为了研究不同参数大小的推荐器的性能,实验选择了Pythia中的模型作为比较,分别是Pythia-1.4b和Pythia-2.8b。结果如图所示:
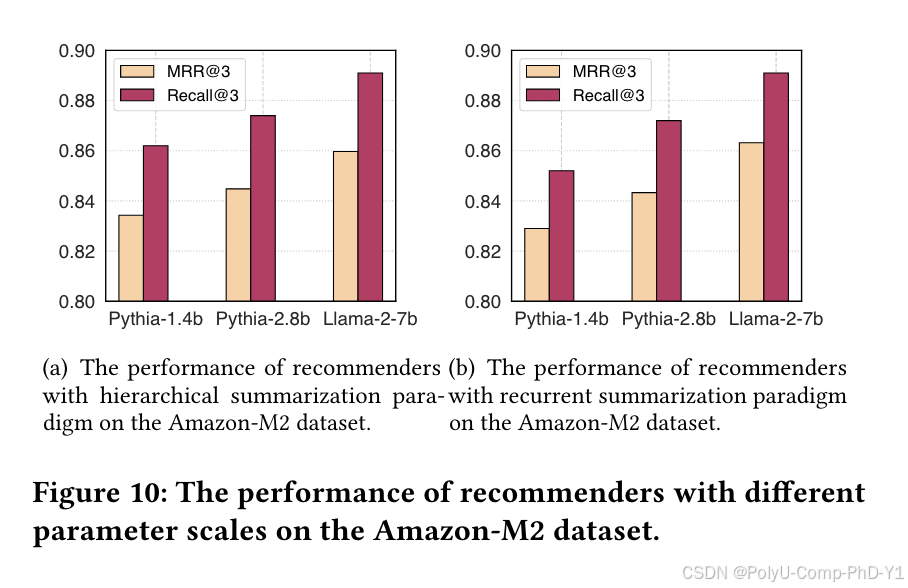
从结果中可以看出,规模较大的模型通常会获得更好的性能,但较大的模型也需要更多的计算资源。因此,在实际应用场景中,在模型性能和计算开销之间取得平衡是一个值得考虑的问题。
(2)摘要器参数大小设置
本文选择Llama-30b-instruct模型作为摘要器,利用其零样本摘要功能进行用户偏好摘要。为了研究不同规模的LLM在总结用户偏好方面的差异能力,选用Llama-2-13b作为摘要器进行实验。实验结果如图:
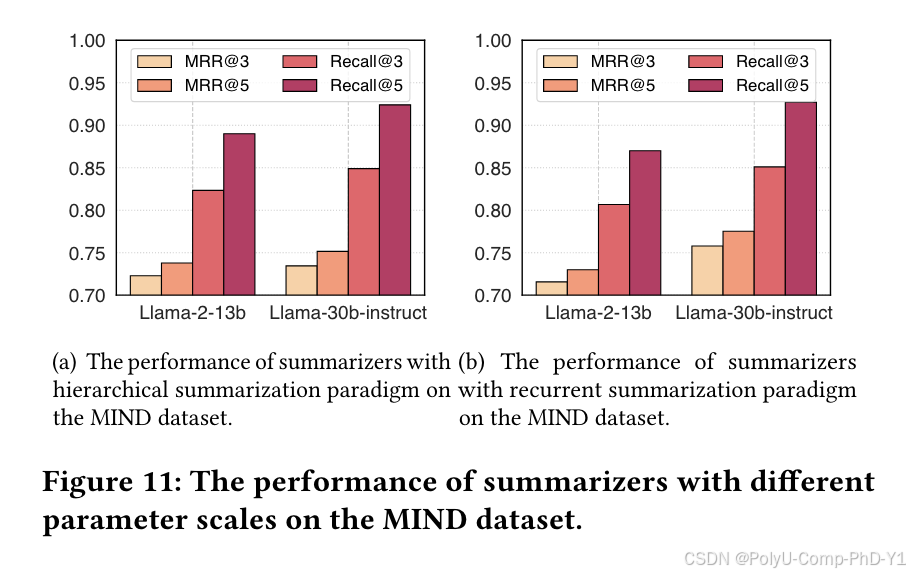
Llama-30b-instruct的摘要能力显著超过Llama-2-13b,这表明只有具有大量参数的LLM才能熟练地执行零样本用户偏好摘要的任务。
5.总结
提出LLM-TRSR,首先对用户行为序列进行分段,然后采用基于LLM的摘要器来封装用户偏好(包括分层摘要和循环摘要),最后使用基于LLM的推荐器来执行推荐任务,并使用监督微调SFT和低秩适应LoRA对参数进行微调。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









