







如果说,NumPy是Python通用科学计算库,那么Pandas则是建立在NumPy基础之上的面板数据(panel data)和数据分析(data analysis)通用工具包,当然,这也就是Pandas名称的由来。相比于NumPy提供了较为基础的数组结构数据,Pandas则提供了主要面向面板数据(或者说表格数据)分析处理的数据结构和工具,二维表格数据可以说是数据分析和大多数机器学习场景下最常用的数据结构了,这也是为什么对于大多数Python数据分析师、数据挖掘工程师来说,Pandas会成为最常用的工具包之一的原因。
一、pandas对象类型介绍
Pandas核心定义了三类对象,分别是Series、Index和DataFrame。
- 其中,Series和Numpy中array非常类似,相当于是array的改进版,其中最重要的区别就是Series能够提供显式索引,从而为表结构的行标和列标提供了基础;
- Index则是一种特殊的序列,可以看成是一种显式索引的集合;
- DataFrame则是二维表结构数据的直接表示,是多个Series共同构成的数据结构,同时也是实际使用Pandas过程中最常用的数据结构。
二、series对象创建及基本使用
Pandas 的 Series 对象是一个带索引数据构成的一维数组,其创建方法和array非常类似:通过pd.Series函数并输入一个序列来完成创建。
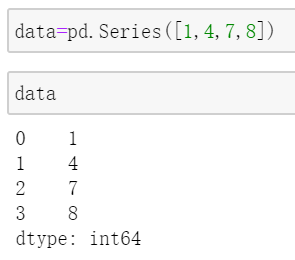
Series具有和array相同的索引方式:
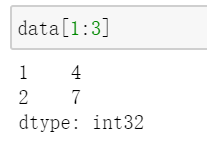
将Series转化为array,通过values:

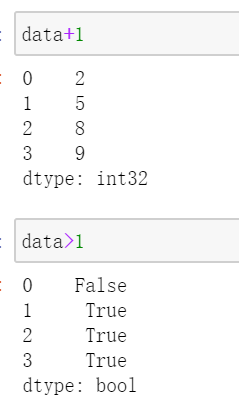
Series和numpy一样,具有广播的特性:
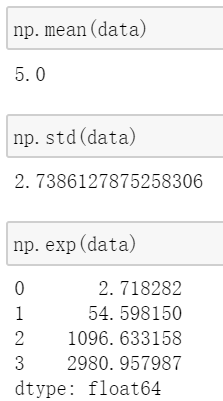
Series具有和array一样的科学计算函数和统计函数:
三、Series的index
Series和array的最显著区别就在于,NumPy 数组通过隐式定义的整数索引获取数值,而 Pandas的Series对象用一种显式定义的索引与数值关联。显式索引的定义让 Series 对象拥有了更强的能力。例如,索引不再仅仅是整数,还可以是任意想要的类型。如果需要,完全可以用字符串定义索引:
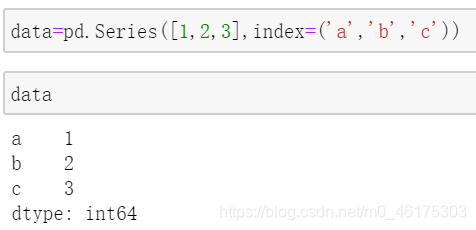
然后可以利用index进行索引:
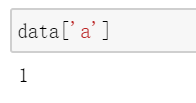
根据索引的名称来索引序列中的某一个元素,和字典非常类似,因此,有的时候我们也会称Series为特殊的字典,甚至,我们可以用字典来创建Series对象:
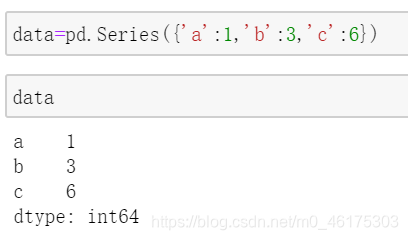
可以通过index属性来查看每个Series的Index.

可以使用in来判断是否包含某元素:
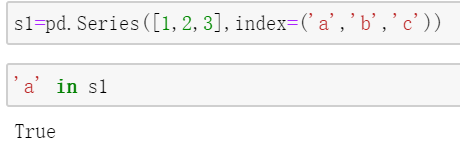
以及和字典类似,使用get方法判断是否包含某元素:

四、Index对象类型介绍
Pandas的Index 对象是一个很有趣的数据结构,可以将它看作是一个不可变数组或有序集合(实际上是一个多集,因为 Index 对象可能会包含重复值)。
3.1 Index的数组属性
首先用整数列表创建一个Index对象:

Index的很多操作都很像数组,可以利用标准python的取值方式来取值,也可以切片:

Index和Numpy有很多相同的属性;

Index和Numpy的不同之处在于,Index对象的索引是不可变的:
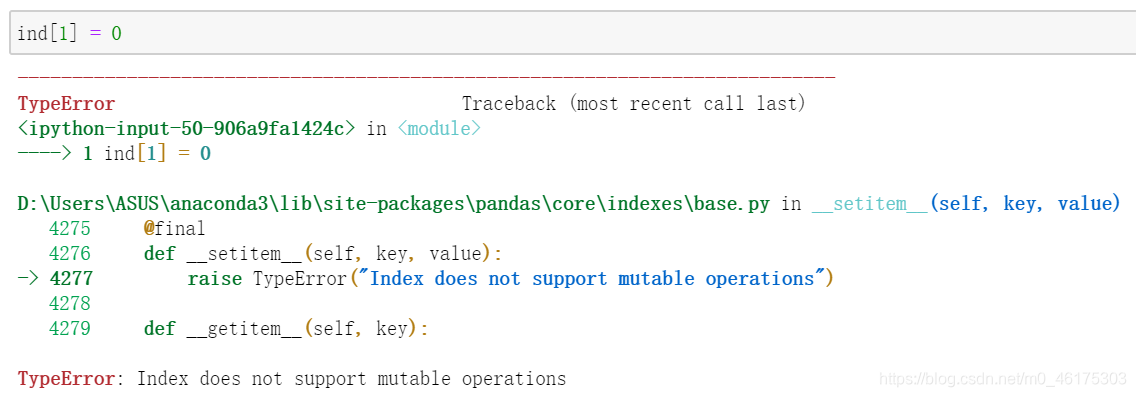
Index 对象的不可变特征使得多个 DataFrame 和数组之间进行索引共享时更加安全,尤其是可以避免因修改索引时粗心大意而导致的副作用。
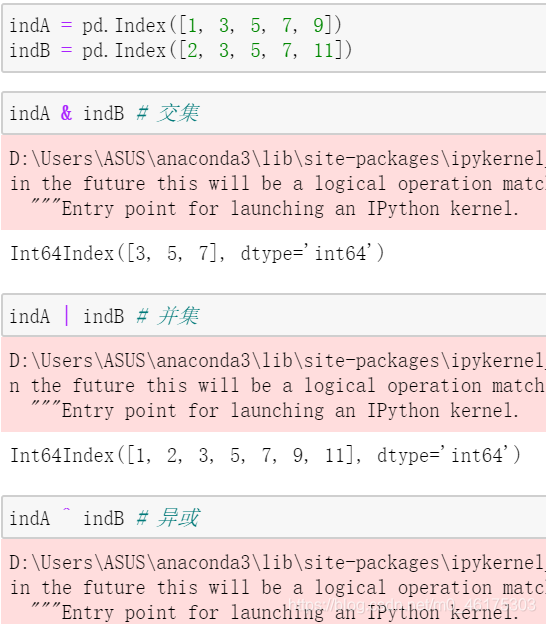
3.2Index的集合属性
Pandas 对象被设计用于实现许多操作,如连接(join)数据集,其中会涉及许多集合操作。Index 对象遵循 Python 标准库的集合( set )数据结构的许多习惯用法,包括并集、交集、差集等:(但部分Index功能将在未来被抛弃)
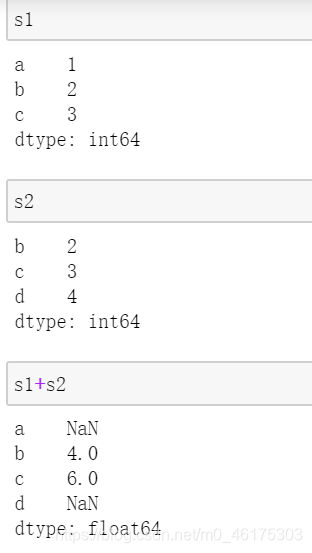
由于index拥有类似集合的属性,因此series也具备了标签对齐的功能。 未对齐 Series 之间的操作结果将包含所涉及的索引的并集。如果在其中一个 Seires 中找不到标签,结果将被标记为 NaN。
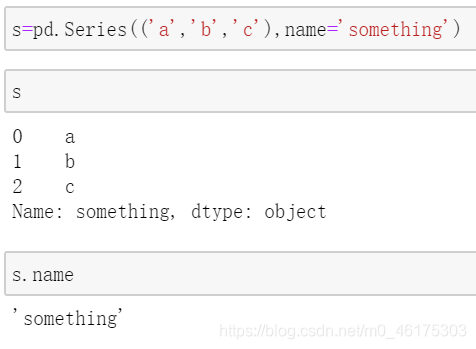
Series的name属性
在创建Series时,可以为其命名。
可以通过rename进行重命名:
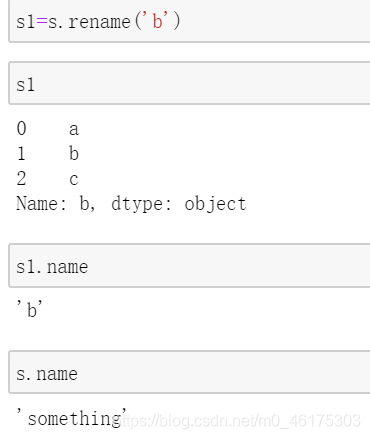
但是注意,s和s1是指向不同对象的。

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









