






前言
记录Adaboost学习
一、集成学习
集成学习的思想很简单,就是通过构建多个学习器来完成学习任务。
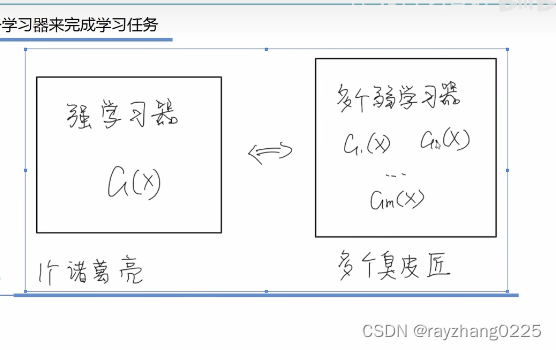
集成学习需要关注的问题:
- 个体学习器如何得到
每个学习器学习的重点不同,要存在差异。**改变训练数据的权值或概率分布(**例如训练集是学习科目,C1学习语文,训练时加大语文训练集的权重)如何改变?(见工作机制) - 如何将个体学习器组合
boosting:
个体学习器见存在强依赖关系、必须串行化生成的序列化方法。即C2学习器训练时需要依赖C1学习器,C3依赖于C2和C1,这就体现了串行,可以使用加法模型,将弱分类器进行线性组合。工作机制:在训练时提高前一轮被弱分类器分错的样本的权值,减小在前一轮被弱分类分对的样本的权值。这样误分的样本在后续就会得到更多的关注。
例如:你现在需要参加期末考试语数英,你有三个分身,分身1先学习,结果语文不错,数学英语不行,那么分身2就减少语文的学习力度,加大数学和英语的时间,测验发现分身2 数学可以,语文和英语不行,那么分身3就要加大英语的学习力度,减小语文和数学的学习时间。考试的时候,你将3个分身带着,就不会挂科啦!整个过程是串行执行的!
加法模型代表的算法有:Adaboost、GBDT、XGBoost、LightGBM等
bagging:个体学习器间不存在强依赖关系,可同时生成的并行化方法。工作机制:从原始样本集中抽取k个训练集(有放回的抽样如:bootstrapping法,随机森林还对特征进行采样),k个训练集分别训练,共得到k个模型(体现了并行),将得到的k个模型通过一定的方式组合起来。对于分类问题可以采用投票的方式组合,对于回归问题可以采用均值作为最后的结果。
二、Adaboost
Adaboost是用来解决二分类问题。

样本的权值

存在3个样本,那么学习器C1训练时每个样本的权值就是1/3。假设C1对样本1分类错误,样本2和样本3分类正确,那么在训练C2时就降低样本2和样本3的权重,假设为1/6。相当于变相的增加了样本1。增大权值可以理解为让样本数量更多。
Adaboost组合方式:加权多数表决
加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用;
减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
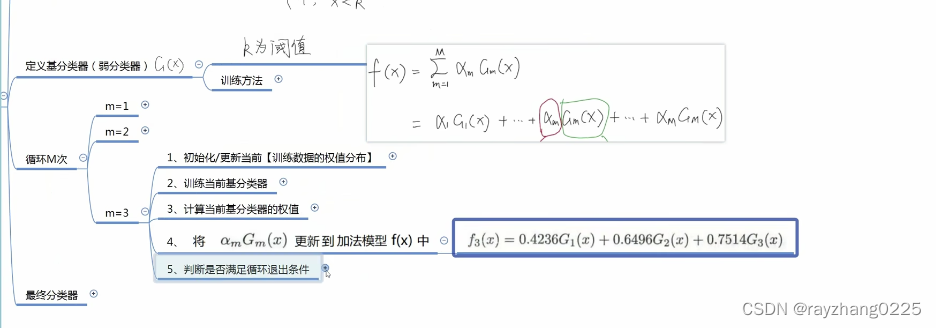
Adaboost算法流程:

1、获取二分类训练集;
2、定义基分类器:如LR (可以相同也可以不同);
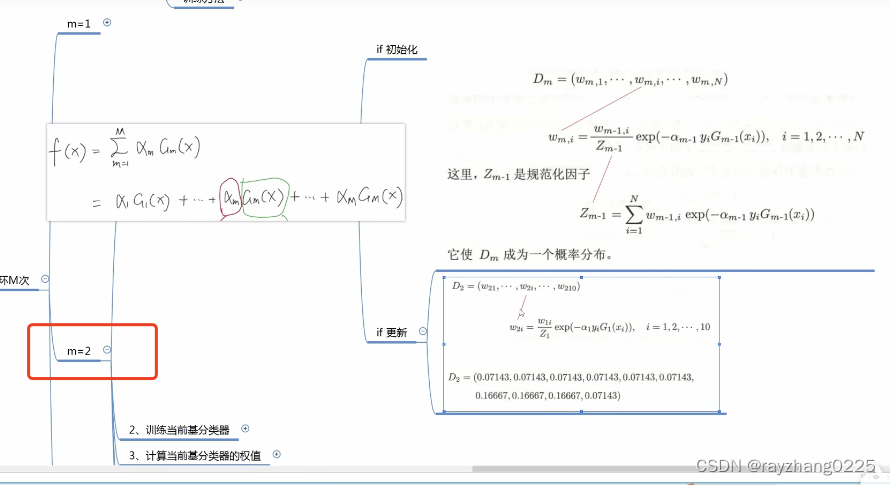
3、循环M次

第一次训练时,将设样本分布是均匀的,权重都为1/N
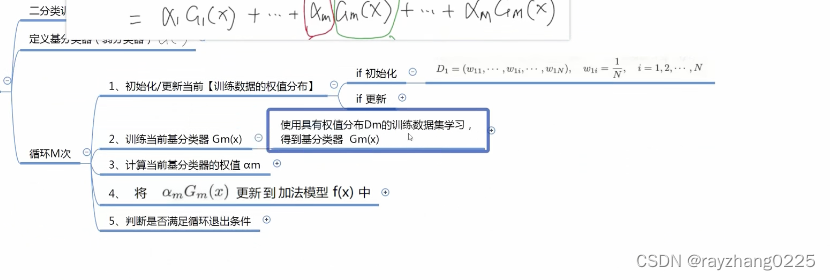
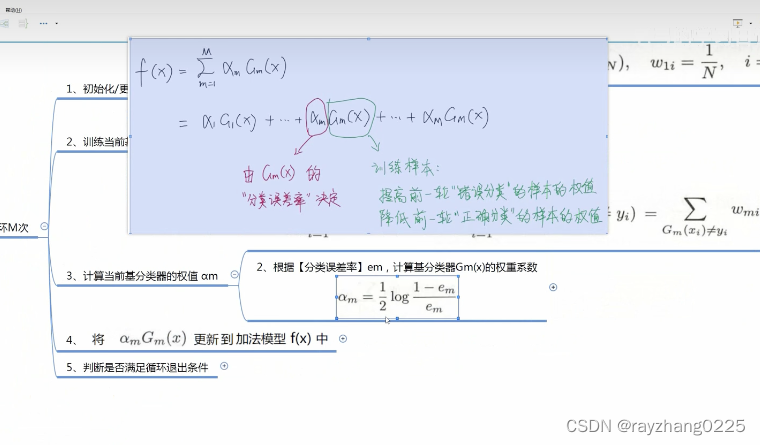
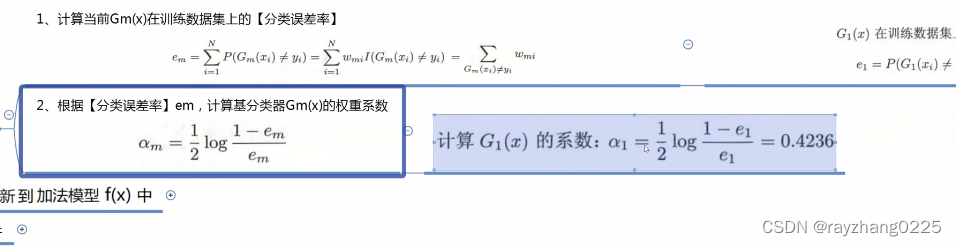
训练完一个弱分类器后,如何确定弱分类的权重呢?即根据弱分类器的分类误差率)

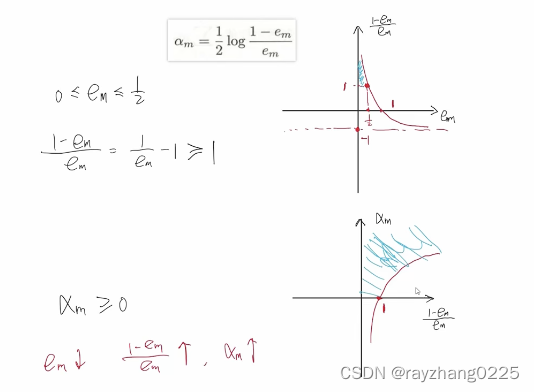
由于em的定义与为[0,1/2],那么
1
−
e
m
e
m
>
=
1
\frac{1-em}{em}>=1
em1−em>=1
将训练好的模型更新到加法模型中

以上为第一次训练,下面讲述如何更新样本权值


二、例题
训练集

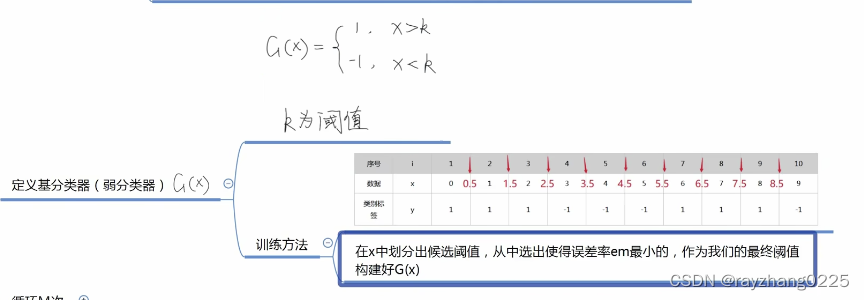


计算分类误差率

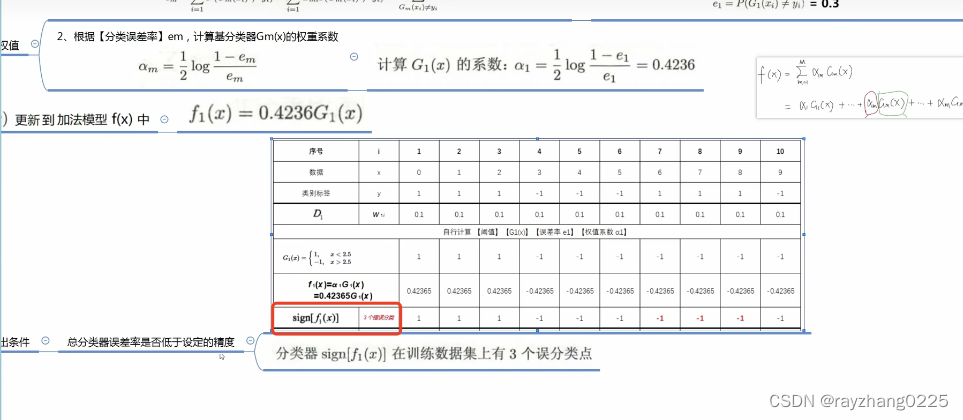


最后的结果
三、加法模型
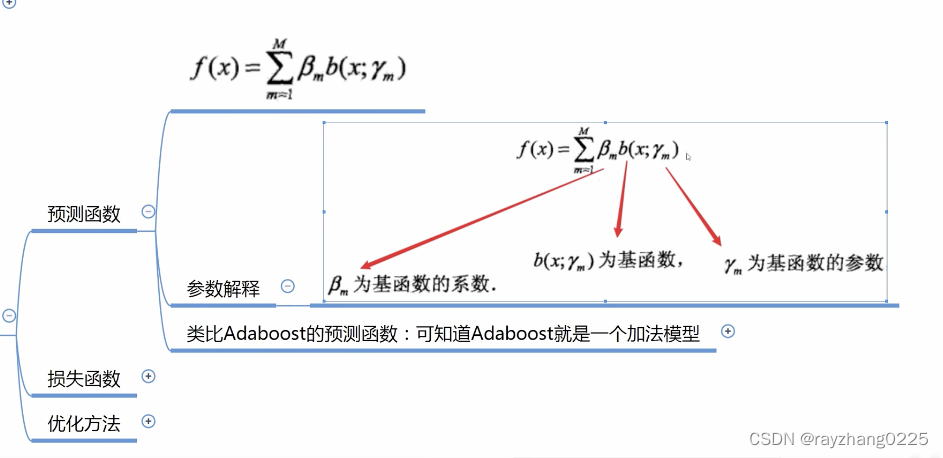
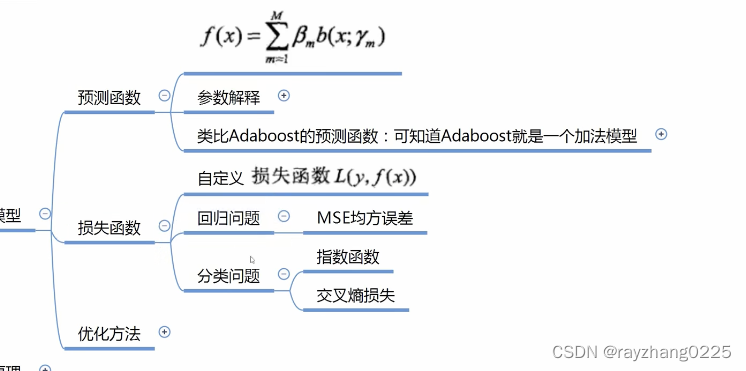
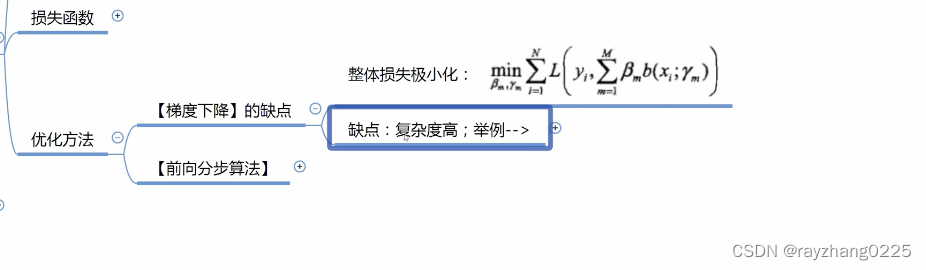

前向分布算法

四、Adaboost算法原理
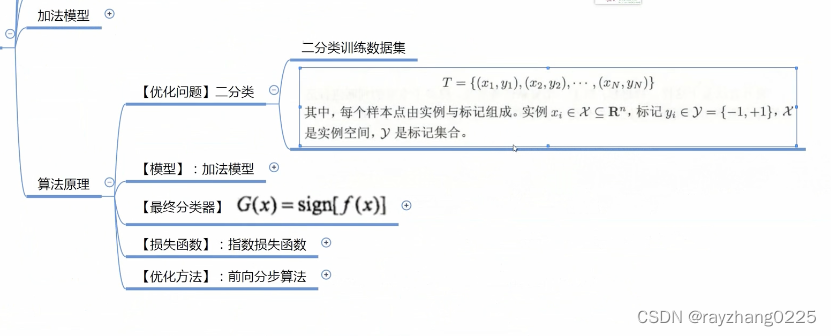

由于这里的标签是-1和1,当预测值f(x)和y同号时,损失小于等于1,当f(x)越大,损失越小。异号则会导致损失大于等于1。总之就是分类错误损失就会非常大,分类正确损失就会很小。此时的损失函数和训练数据的权值同理,就可以将损失函数作为训练数据的权值(因为训练数据分类错误时应给予更大的权值)。




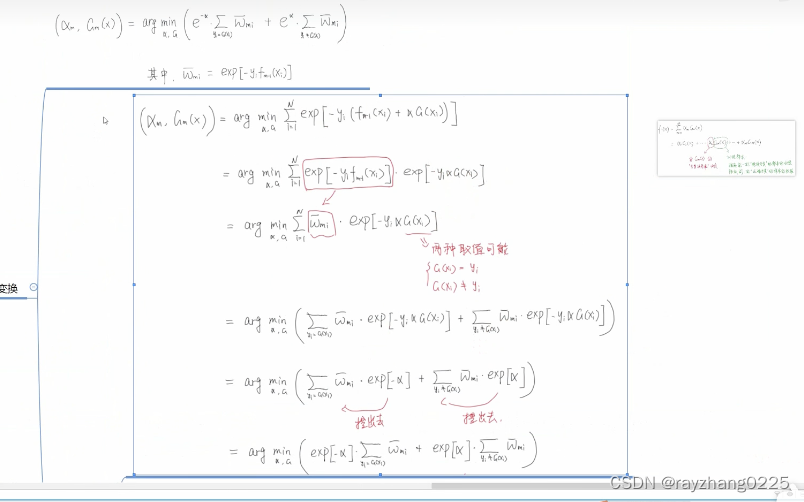

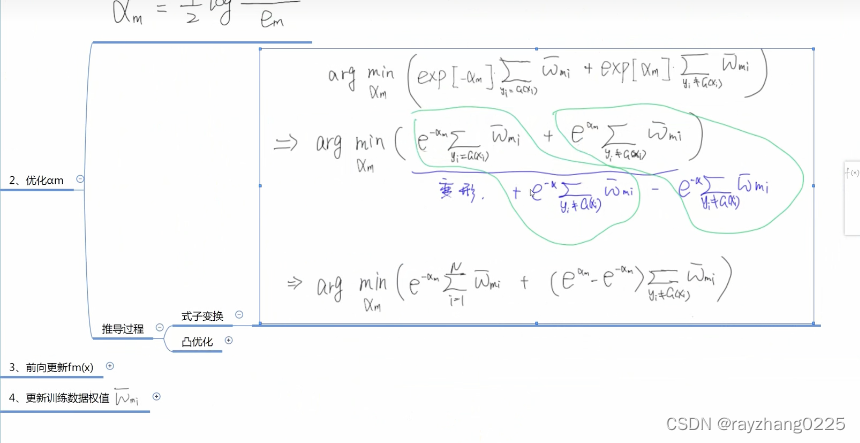
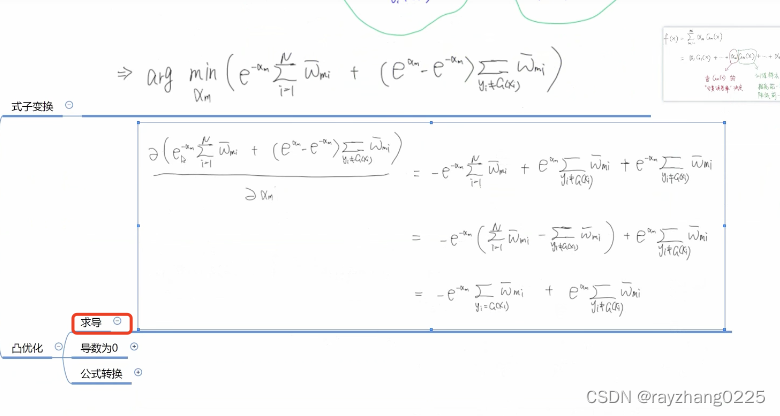

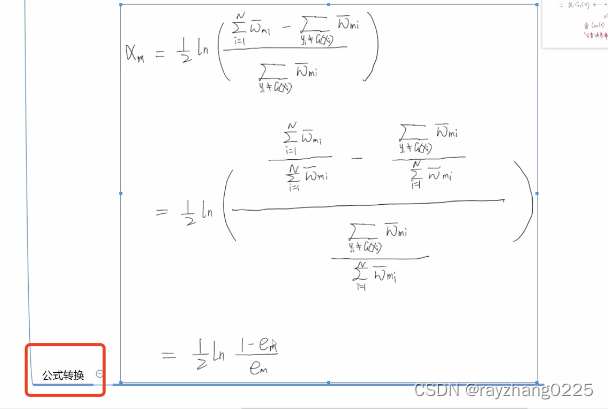


一个做了归一化,一个没有。

references:
B站up——老弓的学习日记


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









