







Abstract
目前最先进的语义图像分割方法是建立在卷积神经网络(CNN)的基础上的.典型的分割结构由(A)负责下采样的路径组成。用于提取粗语义特征,其次是(B)经过训练以在模型输出端恢复输入图像分辨率的上采样路径,以及©后处理模块,以改进模型预测。DenseNets在图像分类任务上表现出了出色的结果。DenseNets的想法是基于观察的。如果每一层都以前馈的方式直接连接到每一层,那么网络就会更精确,更容易训练。本文将DenseNets扩展到语义分割问题上。我们在城市场景基准数据集(如CamVid和Gatech)上获得了最先进的结果,没有任何后处理模块和预训练。此外,由于模型的智能构造,我们的方法比目前发布的这些数据集的最佳条目有更少的参数。
模型深了参数不一定多:201层的DenseNet在ImageNet和101层的ResNet取得相同精度,模型减少一半(前者20M,后者44M),浮点运算前者 80B/image,后者155B/image。
Architecture
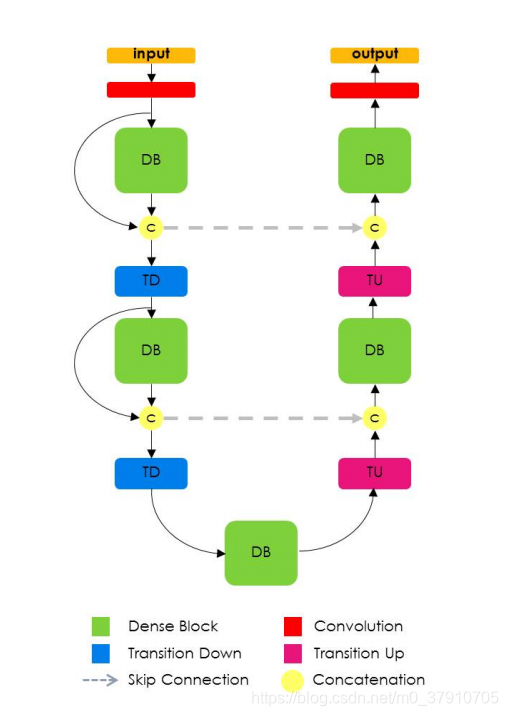
architecture是用dense block构建的。该图由一条具有2次Transition Down路径(TD)和一条有两个Transition Up(TU)重采样路径组成。圆圈表示连接,箭头表示网络中的连接模式。灰色水平箭头表示跳过连接,来自下采样路径的特征映射与上采样路径中的相应特征映射连接。下采样和上采样路径连接方式不同,下采样有特征图跳跃连接,而上采样时没有(因为上采样路径增加了特征图的空间分辨率,特征个数的线性增长将会非常耗内存, 特别是在softmax层前的全分辨率特征图。 为了解决这个限制,在上采样层,dense block没有添加跳跃连接)

Transition down用于特征降维。
Transition up 使用转置卷积上采样特征图,与跳层传来的特征串联,生成新的dense block的输入。但这样会带来特征图数目的线性增长,为了解决这个问题,dense block的输入不与它的输出串联。转置卷积仅对最后一个dense block的特征图使用。最后一个dense block综合了所有之前dense block的信息。同时引入跳层解决之前dense block特征损失的问题。
主要的东西都是DenseNet,FC-DenseNet主要是将其从分类任务引入到了语义分割

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









