







流式响应接口是一种特殊的 API 接口,它与传统的一次性返回全部响应数据的接口不同,会以流的形式逐步将数据发送给客户端,而不是等所有数据都准备好后再一次性返回。
以下从原理、特点、应用场景、与传统接口的对比几个方面详细解释:
1.基础概念
1.1.原理
在传统的 HTTP 请求 - 响应模式中,服务器会在处理完整个请求后,将完整的响应数据封装在一个 HTTP 响应中一次性发送给客户端。
而流式响应接口则打破了这种模式,服务器在处理请求的过程中,一旦有部分数据准备好,就会立即将这部分数据发送给客户端,客户端可以一边接收数据一边进行处理,无需等待所有数据传输完成。
1.2.特点
- 实时性:数据可以实时传输,客户端能够第一时间获取到最新产生的数据,减少了等待时间。例如,在实时数据监测场景中,客户端可以及时获取到最新的监测数据。
- 节省资源:对于大数据量的响应,流式传输避免了服务器一次性将大量数据加载到内存中,降低了服务器的内存压力;同时,客户端也不需要一次性接收和处理大量数据,减少了客户端的资源占用。
- 渐进式处理:客户端可以在接收到部分数据后就开始进行处理,提高了整体处理效率。比如在视频播放场景中,客户端可以在接收到一定量的视频数据后就开始播放,而不需要等整个视频文件下载完成。
1.3.应用场景
- 大数据传输:当需要传输大量数据(如大文件下载、数据库备份文件传输等)时,流式响应可以避免因一次性传输大量数据导致的内存溢出和网络拥塞问题。
- 实时数据推送:在实时监控、金融行情、在线聊天等场景中,服务器需要实时将最新的数据推送给客户端,流式响应可以保证数据的实时性。
- 长任务处理:对于一些处理时间较长的任务(如复杂的数据分析、批量处理等),服务器可以在处理过程中逐步返回中间结果,让客户端及时了解任务的进展情况。
1.4.与传统接口的对比
| 对比项 | 传统接口 | 流式响应接口 |
|---|---|---|
| 数据返回方式 | 一次性返回全部数据 | 逐步返回数据 |
| 响应时间 | 等待所有数据处理完成后返回 | 部分数据准备好即可返回,实时性高 |
| 服务器资源占用 | 处理过程中需要将所有数据加载到内存 | 数据逐步处理和发送,内存占用低 |
| 客户端处理方式 | 等待所有数据接收完成后再处理 | 可以边接收边处理,提高处理效率 |
2.实现流式响应接口
常见的方式如下,这里我不在逐一展开,我就用Servlet和WebFlux作为示例演示。
- Servlet 3.0异步支持
Servlet3.0引入了异步处理的能力,允许开发者在Servlet中使用AsyncContext来实现流式响应。通过调用startAsync()方法,可以在不同的线程中处理请求,并逐步发送数据。 - Spring WebFlux
Spring WebFlux是Spring框架的一部分,专为响应式编程设计。它支持流式响应,可以使用Mono和Flux来处理异步数据流。通过SseEmitter类,可以轻松实现服务器推送事件 - Server-Sent Events (SSE)
SSE是一种标准的Web技术,允许服务器通过HTTP连接向客户端推送实时更新。在Java中,可以使用Servlet或Spring来实现SSE,客户端通过EventSource API接收数据。 - WebSocket
WebSocket是一种双向通信协议,允许客户端和服务器之间建立持久连接。Java中可以使用Java EE的WebSocket API或Spring的WebSocket支持来实现流式响应,适合需要实时交互的应用场景。 - Reactive Streams
Reactive Streams是一种标准,定义了异步流处理的API。Java中可以使用Reactor或RxJava等库来实现响应式编程,支持流式数据处理和背压机制。
2.1Servlet方式
maven配置,只需要Sping web依赖即可,其余依赖均不需要(这里我使用的是SpringBoot3+jdk17)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
启动类添加扫描Servlet
@SpringBootApplication
@ServletComponentScan
2.1.1传统API
下面的这个api,我们通过访问,即可一次性拿到1到50
@WebServlet("/api/traditional")
public class TraditionalServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setCharacterEncoding("UTF-8");
resp.setContentType("application/json; charset=UTF-8");
PrintWriter writer = resp.getWriter();
StringBuilder buffer = new StringBuilder();
int lenth = 50;
for (int i = 0 ; i < lenth; i++) {
buffer.append(i);
if (i < lenth - 1) {
buffer.append(",");
}
}
writer.write(buffer.toString());
writer.close();
}
}
我们直接在浏览器访问这个get接口,即能一次性拿到所有的数据。

2.1.2流式响应API
@WebServlet(urlPatterns = "/api/stream",asyncSupported = true)
public class StreamServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setCharacterEncoding("UTF-8");
resp.setContentType("text/event-stream; charset=UTF-8");
AsyncContext asyncContext = req.startAsync(req, resp);
// 设置超时时间为1分钟
asyncContext.setTimeout(1 * 60 * 1000);
int lenth = 50;
Executors.newSingleThreadScheduledExecutor().execute(() -> {
try {
PrintWriter writer = resp.getWriter();
for (int i = 0; i < lenth; i++) {
writer.write(i + "\n\n");
writer.flush();
TimeUnit.SECONDS.sleep(1);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
asyncContext.complete();
}
});
}
}
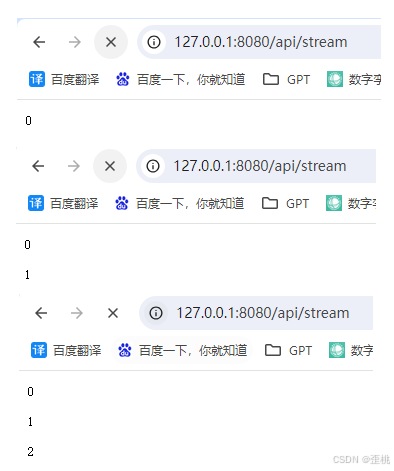
而这个接口,当我在浏览器地址中访问时,他不是一次性给我返回50个数,而是像动态的一样,一次给我一个。例如如下截图。
2.2.WebFlux方式
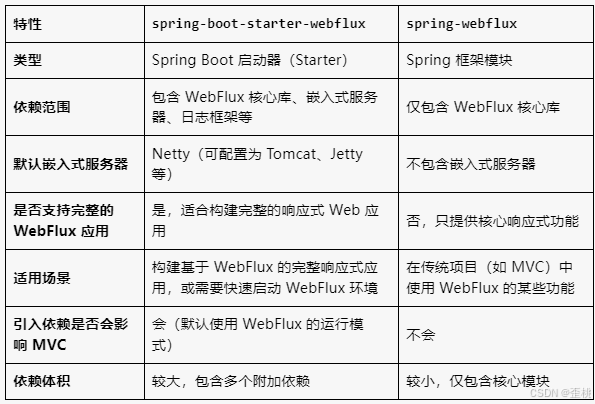
maven依赖需要注意:如果同时引入spring-boot-starter-web和spring-boot-starter-webflux,默认情况下,应用将被视为Spring MVC应用,而不是WebFlux应用。这是因为Spring MVC是基于Servlet API的,而WebFlux是基于反应式编程的。
即,我们引入的依赖是:webflux,而不是web。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
如下是示例代码,具体相关用法,不在进行展开。自行查阅相关文档
@RestController
public class StreamController {
@GetMapping(value = "/api/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Integer> streamData() {
return Flux.range(1, 50).delayElements(Duration.ofSeconds(1));
}
}
浏览器访问该接口的时候,就可以发现,页面上我们看到的数据,在逐步进行输出,而不是一次性给我们全部输出。
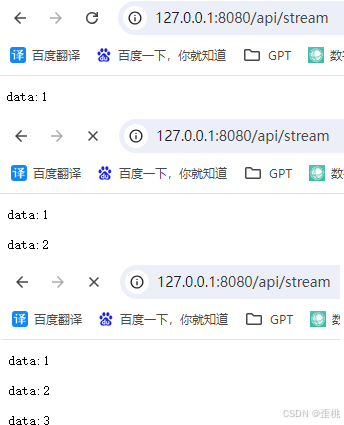
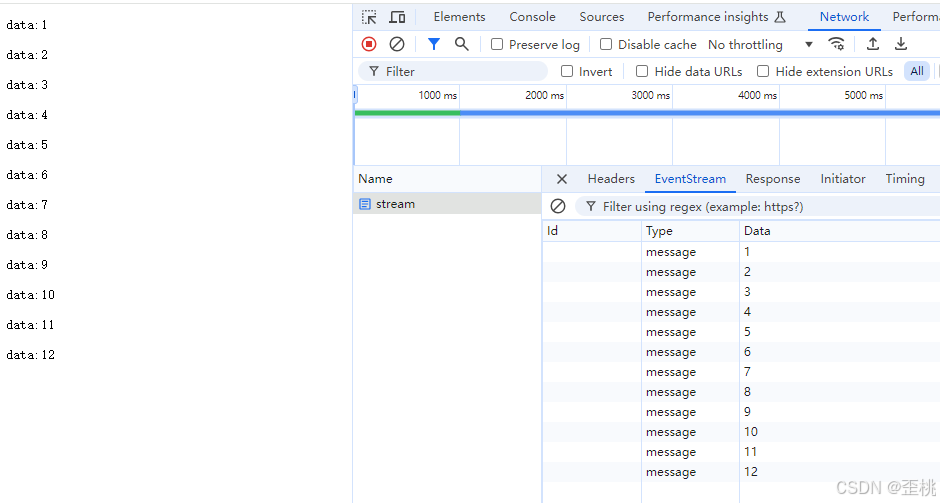
截止目前,你应该知道怎么去开发一个流式响应接口了。那么现在我们来学习,怎么去调用别人的流式响应接口。就像,我们能开发一个http接口了,同时我们也需要去调用别人开发的http接口。
3.调用流式响应接口
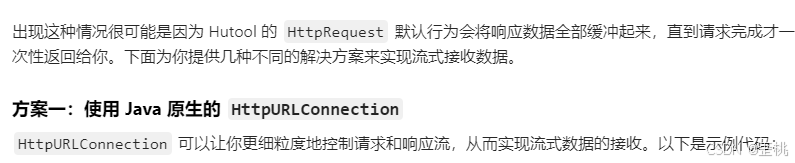
RestTemplate 在处理响应时是一次性等待所有数据返回的。它是一个阻塞式的 HTTP 客户端。因此这里我们不能使用RestTemplate,询问GPT,市面上的大部分AI,都觉得Hutool可以,但是Hutool也是阻塞的。反正我尝试了一个小时,没试出来可以非阻塞。
3.1.HttpURLConnection
以豆包为例,在我一步步的指引下,最后用java.net.HttpURLConnection实现了。
被调用的流式接口如下,也就是上面我们的例子
@RestController
public class StreamController {
@GetMapping(value = "/api/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Integer> streamData() {
return Flux.range(1, 50).delayElements(Duration.ofSeconds(1));
}
}
@Log4j2
public class StreamApiCallerWithHttpURLConnection {
public static void main(String[] args) {
try {
log.info("开始调用:{}", DateUtils.getNowDateStr());
URL url = new URL("http://localhost:8080/api/stream");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
// 获取响应码
int responseCode = connection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
if (!line.isEmpty()) {
log.info("时间:{},接收数据:{}",DateUtils.getNowDateStr(), line);
}
}
}
}
connection.disconnect();
} catch (IOException e) {
e.printStackTrace();
}
}
}
效果展示,我们于15秒开始,然后每隔1秒,就会接到来自/api/stream的返回数据。正如我们接口每隔1秒返回一个数字一样。
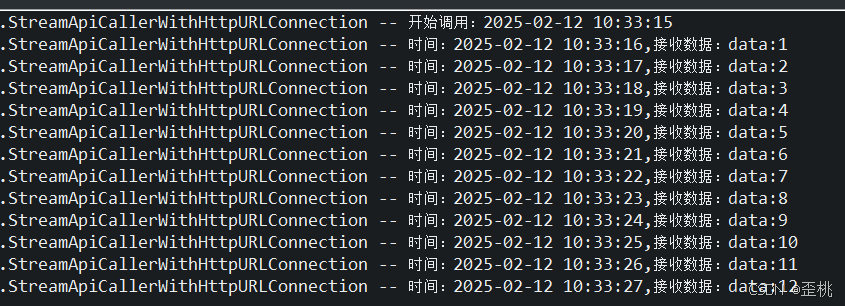
然后如果使用的其他http工具时,需要注意,这里我以其他AI给的hutool的给的代码为例,说一下错误示范。
其他AI我就不在说了,这里就以GPT4.0 mini写了错误代码示范(其中log是我为了方便看加的)
@Log4j2
public class StreamApiCallerWithHutool {
public static void main(String[] args) {
log.info("开始调用:{}", DateUtils.getNowDateStr());
// 发起 GET 请求到流式接口
HttpResponse response = HttpRequest.get("http://localhost:8080/api/stream")
.execute();
try (InputStream inputStream = response.bodyStream();
BufferedInputStream bis = new BufferedInputStream(inputStream)) {
byte[] buffer = new byte[1024];
int bytesRead;
StringBuilder dataBuilder = new StringBuilder();
// 逐块读取响应流
while ((bytesRead = bis.read(buffer)) != -1) {
String chunk = new String(buffer, 0, bytesRead, StandardCharsets.UTF_8);
dataBuilder.append(chunk);
// 处理接收到的数据块
processData(dataBuilder);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭响应
response.close();
}
}
private static void processData(StringBuilder dataBuilder) {
String data = dataBuilder.toString();
int index;
// 逐行处理数据
while ((index = data.indexOf("\n")) != -1) {
String line = data.substring(0, index).trim();
if (!line.isEmpty()) {
log.info("时间:{},接收数据:{}",DateUtils.getNowDateStr(), line);
}
// 移除已处理的行
data = data.substring(index + 1);
}
// 保留未处理完的数据
dataBuilder.setLength(0);
dataBuilder.append(data);
}
}
注意观察,我们在45分40秒的时候发送,按照流式响应,我们应该在45分41秒开始接收到第一个数据,然后每隔一秒接收到一个,但是事实是,我们在46分31秒才收到,时间刚好过去50秒(也就是我们流式接口返回所有数据所需要的时间),并且后面的数据时间都是同一个46分31秒,也就是说,data1到data50是一次性返回的。
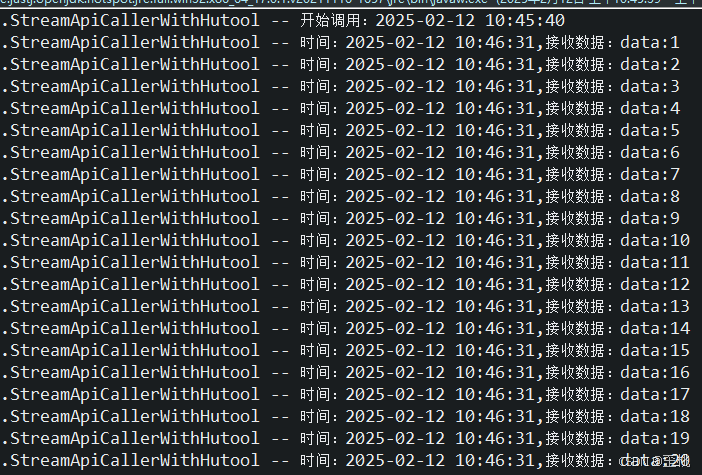
GPT4.0mini不行,那我们就换GPT4.0,4.0版本则告诉我们不支持。建议我们换Webclient

3.2.webClient /webflux
一般情况下,不推荐同时引入:starter-web和starter-webflux,容易引起一些列的冲突问题。
如果你的项目同时需要 Spring MVC 和 WebFlux(例如,部分接口使用阻塞式 MVC,部分使用响应式 WebFlux),可以同时引入两个依赖,但需要明确设置默认的运行模式:
servlet:使用 Spring MVC(阻塞式)。
reactive:使用 Spring WebFlux(非阻塞式)。
none:不启用 Web 环境(适用于非 Web 应用)
spring.main.web-application-type=reactive
<!-- Spring Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring WebFlux (包含 WebClient) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
如果仅仅只是想用WebClient。可以用下面的方式。
<dependencies>
<!-- Spring MVC -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring WebFlux,仅引入 WebClient,不引入 WebFlux 的运行时 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
</dependencies>
详细代码如下
import org.springframework.web.reactive.function.client.WebClient;
import lombok.extern.log4j.Log4j2;
import reactor.core.publisher.Flux;
@Log4j2
public class StreamApiCallerWithWebClient {
public static void main(String[] args) {
log.info("开始调用:{}", DateUtils.getNowDateStr());
// 创建 WebClient 实例
WebClient webClient = WebClient.create("http://localhost:8080");
// 调用流式接口
Flux<Integer> stream = webClient.get()
.uri("/api/stream")
.retrieve()
.bodyToFlux(Integer.class);
// 实时打印每次返回的数据
stream.subscribe(
data -> {
log.info("时间:{},接收数据:{}",DateUtils.getNowDateStr(), data);
}, // 处理每一条数据
error -> System.err.println("Error: " + error), // 处理错误
() -> System.out.println("Stream complete!") // 流结束时执行
);
// 保证主线程不会提前退出
try {
Thread.sleep(60000); // 根据流时间调整
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
效果呈现
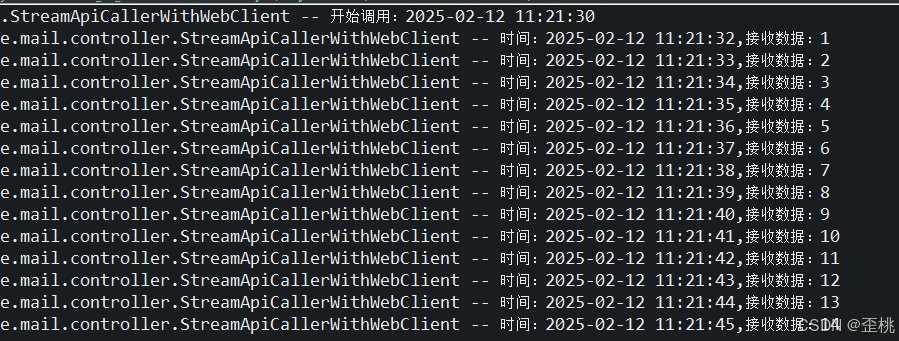
完毕!

















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









