







概率与统计(Probability and Statistics)
1 概率
1.1 条件概率(Conditional Probability)
P(A∣B)=P(A∩B)P(B) P(A|B)= \frac {P(A\cap B )}{P(B)} P(A∣B)=P(B)P(A∩B)
A在另外一个事件B已经发生条件下的发生概率。
例题:老王有两个孩子,亲生的!
A:他告诉有一个是男孩子,求另一个是女孩子的概率。
B:我看到了一个是男孩,求另一个是女孩的概率。
答案:A是2/3,B是1/2。
1.2 全概率(Total Probability)
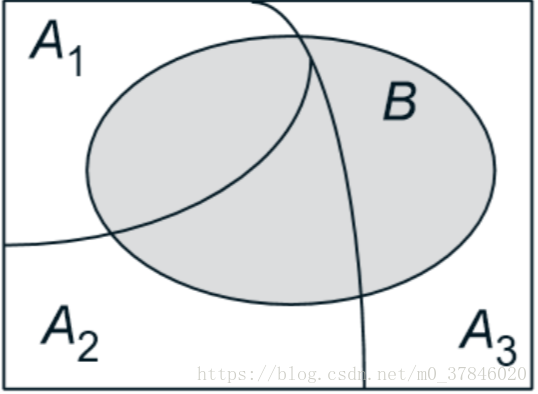
P(B)=P(A1∩B)+…+P(An∩B)=P(B∣A1)P(A1)+…P(B∣An)P(An) P(B)=P(A_1 \cap B)+…+P(A_n \cap B)=P(B|A_1)P(A_1)+…P(B|A_n)P(A_n) P(B)=P(A1∩B)+…+P(An∩B)=P(B∣A1)P(A1)+…P(B∣An)P(An)
1.3 贝叶斯法则(Bayes Rule)
P(Ai∣B)=P(Ai)P(B∣Ai)P(B)=P(Ai)P(B∣Ai)P(B∣A1)P(A1)+…P(B∣An)P(An) P(A_i|B)= \frac {P(A_i)P(B|A_i)}{P(B)}=\frac {P(A_i)P(B|A_i)}{P(B|A_1)P(A_1)+…P(B|A_n)P(A_n)} P(Ai∣B)=P(B)P(Ai)P(B∣Ai)=P(B∣A1)P(A1)+…P(B∣An)P(An)P(Ai)P(B∣Ai)
推导P(A∩B)=P(A∣B)P(B)=P(B∣A)P(A)P(A\cap B )=P(A|B)P(B)=P(B|A)P(A)P(A∩B)=P(A∣B)P(B)=P(B∣A)P(A)
P(H∣D)=P(H)P(D∣H)P(D)
P(H|D)= \frac {P(H)P(D|H)}{P(D)}
P(H∣D)=P(D)P(H)P(D∣H)
等式右边P(H)P(H)P(H)为先验概率,P(D∣H)P(D|H)P(D∣H)为似然概率,P(D)P(D)P(D)为证据。等式左边P(H∣D)P(H|D)P(H∣D)为后验概率。
1.4 独立(Independence)
如果A和B是独立的,那么满足:
P(A∩B)=P(A)P(B)
P(A \cap B)=P(A)P(B)
P(A∩B)=P(A)P(B)
如果P(B)>0,则同时满足:
P(A∣B)=P(A)
P(A|B)=P(A)
P(A∣B)=P(A)
如果A,B独立,如果有事件C,则满足:
P(A∩B∣C)=P(A∣C)P(B∣C)
P(A \cap B|C)=P(A|C)P(B|C)
P(A∩B∣C)=P(A∣C)P(B∣C)
如果A,B独立,且P(B∩C)>P(B \cap C)>P(B∩C)> 0,则满足:
P(A∣B∩C)=P(A∣C)
P(A|B \cap C)=P(A|C)
P(A∣B∩C)=P(A∣C)
2 统计
2.1 二项式概率(Binomial Probabilities)
例如:一个硬币投掷N次,求正面出现k次的概率。
pX(k)=P(X=k)=Cnkpk(1−p)n−k,k=0,1,2…n
p_X(k)=P(X=k)=C_n^kp^k(1-p)^{n-k},k=0,1,2…n
pX(k)=P(X=k)=Cnkpk(1−p)n−k,k=0,1,2…n
2.2 期望(Expectation)
随机变量的平均值。
E[X]=∑xpX(x)
E[X]=\sum xp_X(x)
E[X]=∑xpX(x)
复合函数求期望:
E[g(x)]=∑g(x)pX(x)
E[g(x)]=\sum g(x)p_X(x)
E[g(x)]=∑g(x)pX(x)
2.3 方差(Variance)
随机变量的波动性。
var(X)=E[(X−E[x])2]
var(X)=E[(X-E[x])^2]
var(X)=E[(X−E[x])2]
2.4 协方差(Covariance)
Cov(X,Y)=E[(X−E[X])(Y−E(Y))]
Cov(X,Y)=E[(X-E[X])(Y-E(Y))]
Cov(X,Y)=E[(X−E[X])(Y−E(Y))]
如果X,Y线性相关,则满足:
Cov(X,Y)=E[XY]−E[X]E[Y]
Cov(X,Y)=E[XY]-E[X]E[Y]
Cov(X,Y)=E[XY]−E[X]E[Y]
2.5 概率分布
2.5.1 伯努利分布(Bernoulli Distribution)
代表一次 YES 或者 NO的实验。
f(k;p)=pk(1−p)1−k,k∈0,1
f(k;p)=p^k(1-p)^{1-k},k \in {0,1}
f(k;p)=pk(1−p)1−k,k∈0,1
E(x)=pE(x)=pE(x)=p, Var[x]=pqVar[x]=pqVar[x]=pq.
2.5.2 多项式分布(Multinomial Distribution)
例子:投掷骰子1000次,其中100次1点,200次2点,300次3点,100次4点,100次5点,200次6点的概率。
f(x1,…,xn;n,p1,…,pk)=Pr(X1=x1and...andXk=xk)
f(x_1,…,x_n;n,p_1,…,p_k)=P_r(X_1=x_1 and ... and X_k=x_k)
f(x1,…,xn;n,p1,…,pk)=Pr(X1=x1and...andXk=xk)
...=n!x1!...xn!p1x1×...×pkxk=Cnx1×Cn−x1x2×...×Cn−x1−...xn−1xn=n!x1!...xn!p1x1×...×pkxk
...=\frac {n!}{x_1!...x_n!}p_1^{x_1}\times...\times p_k^{x_k}=C_n^{x_1}\times C_{n-x_1}^{x_2}\times ...\times C_{n-x_1-...x_n-1}^{x_n}=\frac {n!}{x_1!...x_n!}p_1^{x_1}\times...\times p_k^{x_k}
...=x1!...xn!n!p1x1×...×pkxk=Cnx1×Cn−x1x2×...×Cn−x1−...xn−1xn=x1!...xn!n!p1x1×...×pkxk
2.5.3 泊松分布(Poisson Distribution)
泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。
f(k;λ)=Pr(X=k)=λke−λk!
f(k;\lambda)=Pr(X=k)=\frac{\lambda^ke^{-\lambda}}{k!}
f(k;λ)=Pr(X=k)=k!λke−λ
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。 泊松分布适合于描述单位时间内随机事件发生的次数。
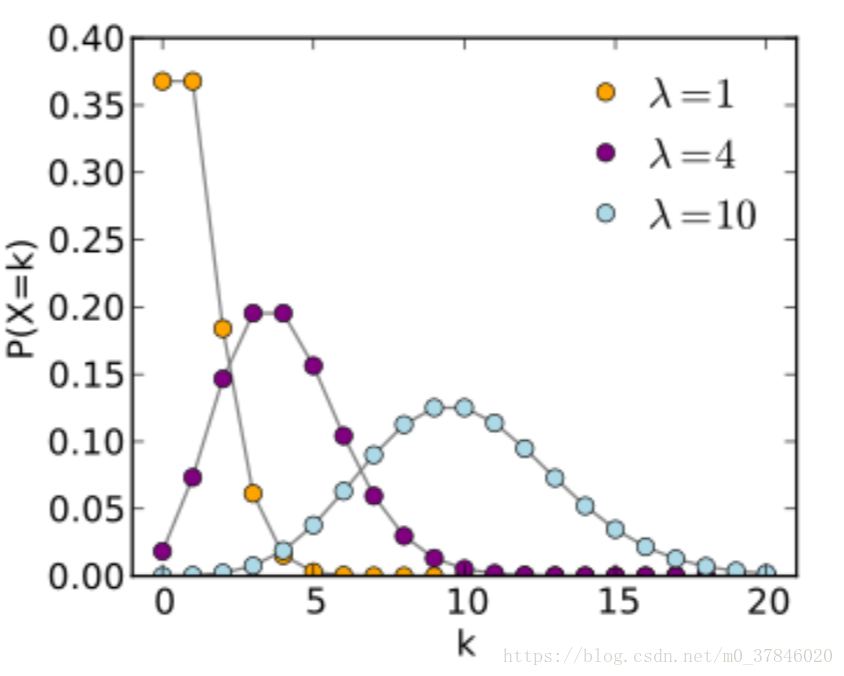
2.5.4 高斯(正态)分布(Gaussian (Normal) Distribution)
常见的一种假设分布。
f(x;μ,σ2)=12πσ2e−(x−μ)22σ2
f(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x;μ,σ2)=2πσ21e−2σ2(x−μ)2
μ是期望,σ2是方差\mu是期望,\sigma^2是方差μ是期望,σ2是方差
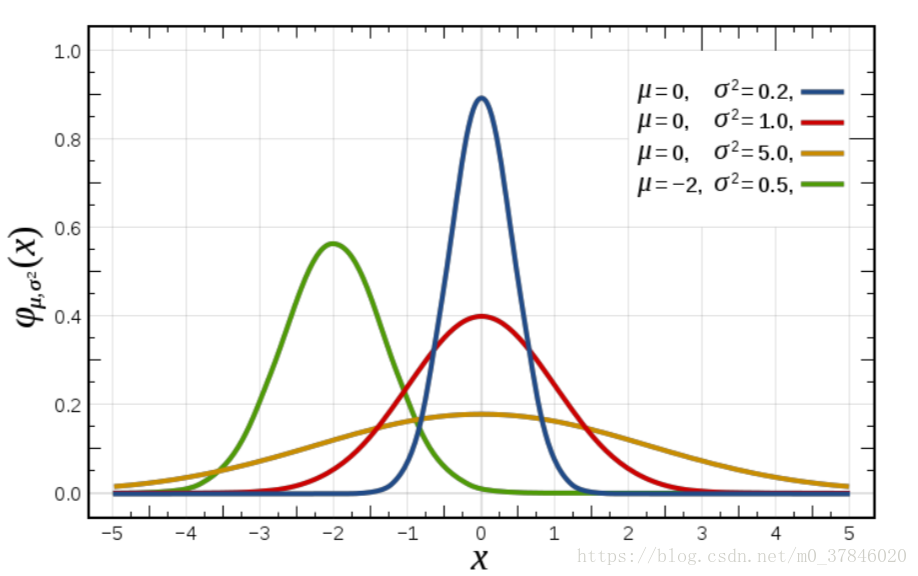
2.5.5 伽马分布(Gamma Distribution)
伽马函数:
Γ(n)=(n−1)!\Gamma(n)=(n-1)!Γ(n)=(n−1)!
Γ(z)=∫0∞xz−1e−xdx \Gamma(z)=\int_{0}^{\infin} x^{z-1}e^{-x}dxΓ(z)=∫0∞xz−1e−xdx
推导Γ(z+1)=∫0∞xze−xdx=[−xze−x]0∞+∫0∞zxz−1e−xdx=z∫0∞xz−1e−xdx=zΓ(z)\Gamma(z+1)=\int_{0}^{\infin} x^{z}e^{-x}dx=[-x^ze^{-x}]_0^{\infin}+\int_{0}^{\infin}zx^{z-1}e^{-x}dx=z\int_{0}^{\infin} x^{z-1}e^{-x}dx=z\Gamma(z)Γ(z+1)=∫0∞xze−xdx=[−xze−x]0∞+∫0∞zxz−1e−xdx=z∫0∞xz−1e−xdx=zΓ(z)
伽玛分布(Gamma Distribution)是统计学的一种连续概率函数,是概率统计中一种非常重要的分布。“指数分布”和“χ2\chi^2χ2分布”都是伽马分布的特例。 Gamma分布中的参数α称为形状参数(shape parameter),β称为尺度参数(scale parameter)。
X∼Γ(α,β)≡Gamma(α,β)
X\sim\Gamma(\alpha,\beta)\equiv Gamma(\alpha,\beta)
X∼Γ(α,β)≡Gamma(α,β)
f(x;α,β)=βαxα−1e−βxΓ(α),x>0,α>0,β>0
f(x;\alpha,\beta)=\frac{\beta^\alpha x^{\alpha-1}e^{-\beta x}}{\Gamma(\alpha)},x>0,\alpha>0,\beta>0
f(x;α,β)=Γ(α)βαxα−1e−βx,x>0,α>0,β>0
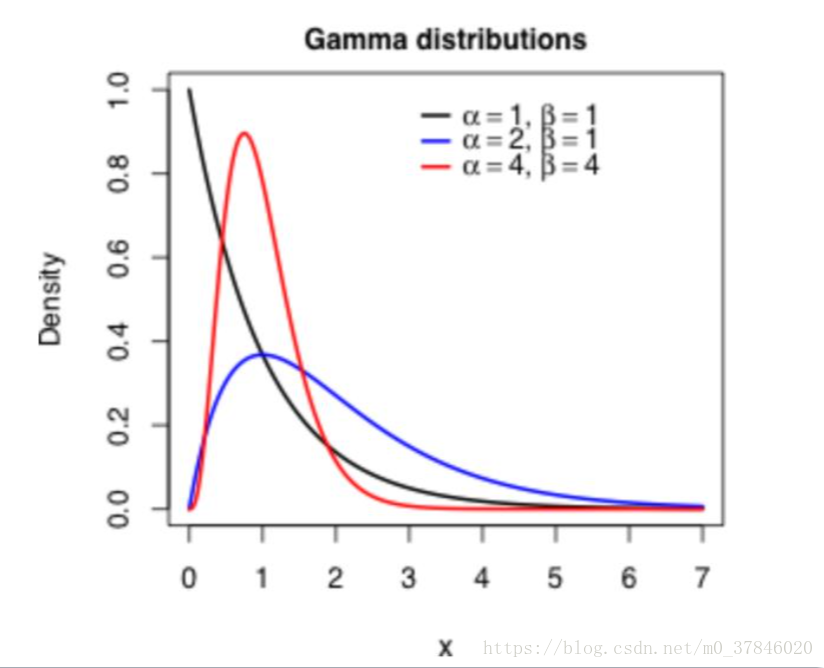
2.5.6 贝塔分布(Gamma Distribution)
贝塔分布(Beta Distribution) 是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,在机器学习和数理统计学中有重要应用。在概率论中,贝塔分布,也称B分布,是指一组定义在(0,1) 区间的连续概率分布。
f(x;α,β)=constant×xα−1(1−x)β−1=xα−1(1−x)β−1∫01uα−1(1−u)β−1du
f(x;\alpha,\beta)=constant\times x^{\alpha-1}(1-x)^{\beta-1}=\frac{x^{\alpha-1}(1-x)^{\beta -1}}{\int_0^1u^{\alpha-1}(1-u)^{\beta-1}du}
f(x;α,β)=constant×xα−1(1−x)β−1=∫01uα−1(1−u)β−1duxα−1(1−x)β−1
...=Γ(α+β)Γ(α)Γ(β)xα−1(1−x)β−1=1B(α,β)xα−1(1−x)β−1
...=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta -1}=\frac{1}{B(\alpha,\beta)}x^{\alpha-1}(1-x)^{\beta -1}
...=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1=B(α,β)1xα−1(1−x)β−1
3 贝叶斯定理的例子(补充)
老王的闺女在沙漠里面举行了婚礼,沙漠里一年只有5天下雨,可惜的是天气预报说结婚那天会下雨,天气预报说会下雨,有90%的概率真的下雨,那么婚礼那天真下雨的概率是多少?
解析:设事件A为天气预报说下雨,事件B为真的下雨。
这道题我们所求为P(B∣A)P(B|A)P(B∣A),罗列一下我们已经知道的条件。P(A∣B)=0.9,P(A∣notB)=0.1,P(B)=5/365,P(notB)=360/365P(A|B)=0.9,P(A|not B)=0.1,P(B)=5/365,P(not B)=360/365P(A∣B)=0.9,P(A∣notB)=0.1,P(B)=5/365,P(notB)=360/365。
所以P(B∣A)=P(A∣B)×P(B)/P(A),P(A)=P(A∣B)⋅P(B)+P(A∣notB)⋅P(notB)=0.111P(B|A)=P(A|B)\times P(B)/P(A),P(A)=P(A|B)⋅P(B)+P(A|notB)⋅P(notB)=0.111P(B∣A)=P(A∣B)×P(B)/P(A),P(A)=P(A∣B)⋅P(B)+P(A∣notB)⋅P(notB)=0.111
求解结束。
4 辛普森悖论(Simpson’s paradox)
“校长,不好了,有很多男生在校门口抗议,他们说今年研究所女生录取率42%是男生21%的两倍,我们学校遴选学生有性别歧视”,校长满脸疑惑的问秘书:“我不是特别交代,今年要尽量提升男生录取率以免落人口实吗?”
秘书赶紧回答说:“确实有交代下去,我刚刚也查过,的确是有注意到,今年商学院录取率是男性75%,女性只有49%;而法学院录取率是男性10%,女性为5%。二个学院都是男生录取率比较高,校长这是我作的调查报告。”

“秘书,你知道为什么个别录取率男皆大于女,但是总体录取率男却远小于女吗?”
此例这就是统计上著名的辛普森悖论(Simpson’s Paradox)。
{ba>fedc>hg̸⇒b+da+c>f+he+g\left\{
\begin{array}{l}
\frac ba>\frac fe\\
\frac dc>\frac hg
\end{array}
\right.\not\Rightarrow\frac{b+d}{a+c}>\frac{f+h}{e+g}
{ab>efcd>gh̸⇒a+cb+d>e+gf+h
为了避免辛普森悖论出现,就需要斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响,同时必需了解该情境是否存在其他潜在要因而综合考虑。

















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









