







NVidia ECCV 2020
code: https://nv-tlabs.github.io/lift-splat-shoot
纯视觉BEV方案
-
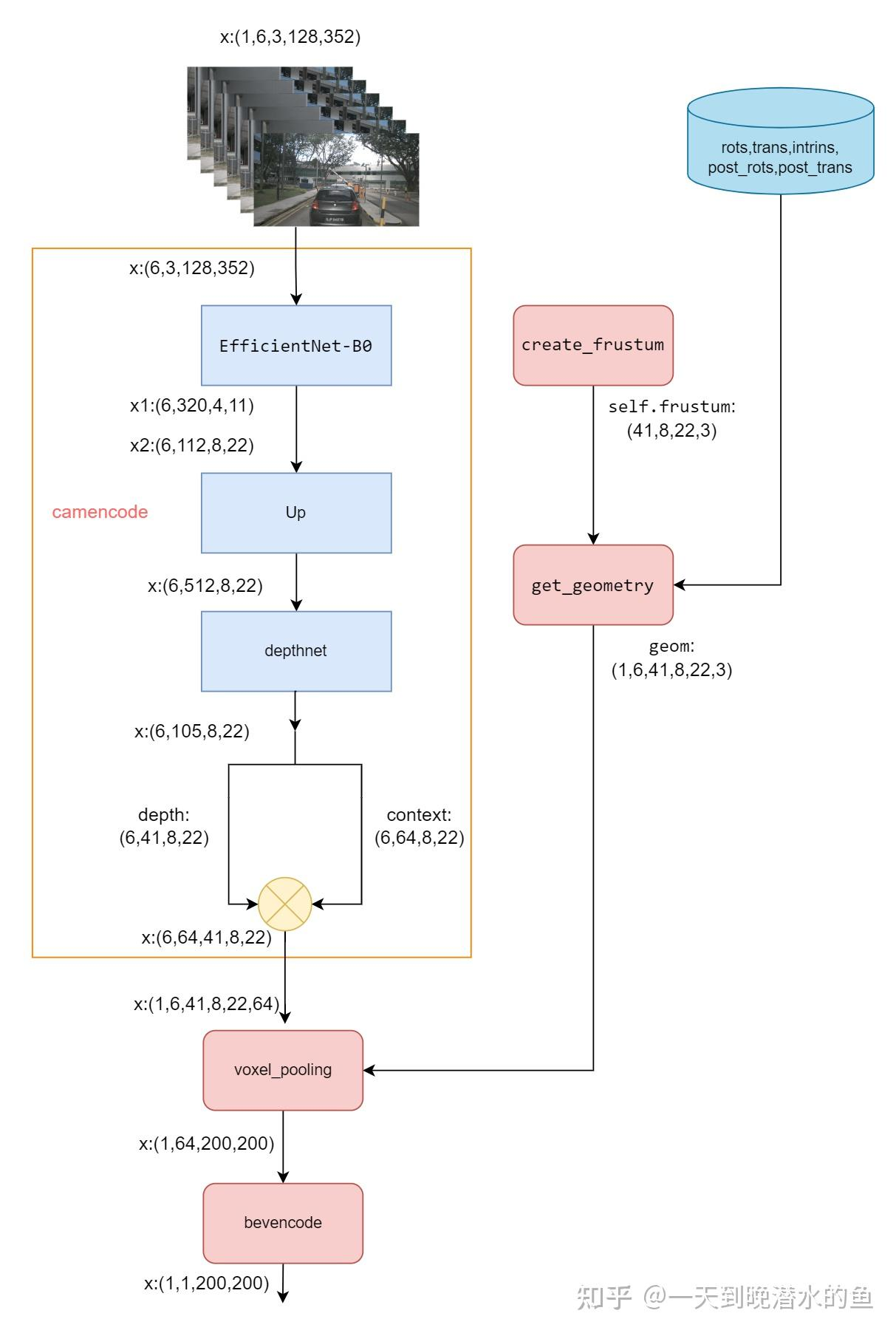
输入:环视N相机,各相机内外参
-
数据集Nuscenes toolkit提供Dataset实现,dataloader每batch内容:
-
allimgs:batchsize,相机数,三通道,图像H,图像W
-
H=128,W=352
-
-
binimgs:01表示真值
-
rots:由相机坐标系->车身坐标系的旋转矩阵,rots = (bs, N, 3, 3);
trans:由相机坐标系->车身坐标系的平移矩阵,trans=(bs, N, 3);
intrinsic:相机内参,intrinsic = (bs, N, 3, 3);
post_rots:由图像增强引起的旋转矩阵,post_rots = (bs, N, 3, 3);
post_trans:由图像增强引起的平移矩阵,post_trans = (bs, N, 3);
binimgs:由于LSS做的是语义分割任务,所以会将真值目标投影到BEV坐标系,将预测结果与真值计算损失;具体而言,在binimgs中对应物体的bbox内的位置为1,其他位置为0;LSS (Lift, Splat, Shoot)代码解析_lss代码-优快云博客
-
-
for batch in valloader:
allimgs, rots, trans, intrins, post_rots, post_trans, binimgs = batch
# x, rots, trans, intrins, post_rots, post_trans
print(allimgs.shape) # torch.Size([4, 6, 3, 128, 352])
print(rots.shape) # torch.Size([4, 6, 3, 3])
print(trans.shape) # torch.Size([4, 6, 3])
print(intrins.shape) # torch.Size([4, 6, 3, 3])
print(post_rots.shape) # torch.Size([4, 6, 3, 3])
print(post_trans.shape) # torch.Size([4, 6, 3])
print(binimgs.shape) # torch.Size([4, 1, 200, 200])-
模型初始化
-
生成视椎 create_frustum
-
参数:
-
downsample=16 输入分辨率下采样倍数
-
-
生成ds:dbound=[4.0, 45.0, 1.0] 距离自车4~45m范围间隔1m,采样41段, [4.0000 ... 44.0000]
-
生成xs:0~351像素,352/16=22 采样22段,[0.0000 16.7143 ... 351.0000]
-
生成ys:0~127像素,128/16=8 采样8段, [18.1429 ... 127.0000]
-
ds xs ys 都expand到shape(41,8,22),dim=-1 stack到一起(41,8,22,3)
-
-
forward过程:
-
生成voxel视图 get_geometry
-
输入:rots, trans, intrins, post_rots, post_trans
-
输出:geom
-
shape:B x N x D x H/downsample x W/downsample x 3=[4, 6, 41, 8, 22, 3]
-
-
-
生成图像+深度特征 get_cam_feats(get_depth_feat)
-
输入:allimgs
-
输出:shape:[4, 6, 41, 8, 22, 64]
-
过程:
-
输入reshape成[B*N, C, imH, imW]=[24,3,128,352]
-
EfficientNet 提特征 get_eff_depth x.shape=[24, 512, 8, 22]
-
卷积提深度特征 depthnet x.shape=[24, 105, 8, 22]
-
dim=1前41维split,softmax归一化分布 get_depth_dist depth.shape=[24, 41, 8, 22]
-
x和depth维度展开,x dim=1后64维点乘 depth
-
输出shape[24, 64, 41, 8, 22] = [24, 1, 41, 8, 22] * [24, 64, 1, 8, 22]
-
-
reshape成[4, 6, 41, 8, 22, 64] 返回
-
B*N拆开,64移到最后一维
-
-
-
-
对齐bev特征 voxel_pooling
-
输入:geom_feats, cam_feats
-
输出:shape=[4, 64, 200, 200]
-
过程:
-
cam feats只保留通道维(C=64),reshape=(B*N*D*H*W, 64)
-
目的:其他所有维度(跨batch 跨相机 跨深度 跨像素)放在统一的bev空间,统一制作索引
-
-
voxel视图(geom_feats)转到voxel索引(数值类型long)
-
参数:
-
ROI物理距离范围与采样间距:xbound=[-50.0, 50.0, 0.5] ybound=[-50.0, 50.0, 0.5] zbound=[-10.0, 10.0, 20.0]
-
dx tensor([ 0.5000, 0.5000, 20.0000]) xyz每个方向取voxel的物理距离间隔
-
bx tensor([-49.7500, -49.7500, 0.0000]) xyz每个方向ROI起始坐标
-
nx tensor([200, 200, 1]) xyz每个方向voxel数量
-
-
自车坐标系下的物理坐标转换到整数索引:
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() -
reshape到(B*N*D*H*W,3)
-
拼接batch id,shape=(B*N*D*H*W,4)用于后面还原batch维
-
4维含义:012:x、y、z方向voxel索引、3:batch id
-
没有拼相机id:之后到bev空间不再有相机概念
-
-
-
过滤掉ROI外的voxel索引(即xyz方向上index超过nx规定的0~199/0~199/0)
-
对voxel索引用类似幂次底的方法计算一个ranks,按照ranks的argsort排序索引indices,对:(1)cam feats内容(2)voxel索引的内容(3)ranks自己,重新排序,
-
完成后ranks自己的内容按数值升序
-
-
用cumsum得到ranks中非相邻重复的rank位置,只保留cam feats和voxel索引中这部分位置对应的元素
-
目的:避免不同相机的voxel空间对bev空间中某位置重复投影
-
-
构建一个(B,C,1,200,200)大小的placeholder,按voxel索引把cam feats对应索引位置的数值填进去,完成:2D特征映射到bev空间
-
dim=0 batch id,按刚才拼接上的第4维batch id 填回去
-
dim=2 z方向voxel索引
-
dim=3 x方向voxel索引
-
dim=4 y方向voxel索引
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
-
-
-
-
FFN bevencode
-
基于resnet18 conv+bn+relu+Upsample
-
-
BCEWithLogitsLoss,正负样本加权pos_weight
https://zhuanlan.zhihu.com/p/706010941

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









