







 本文详细介绍了Java8中新增的并发工具,包括LongAdder如何通过分散热点来提高高并发场景下的性能,以及StampLock的乐观读策略。同时,文章还探讨了CompletableFuture的使用,包括创建实例、获取结果的方法以及其在异步编程中的优势。此外,还简要介绍了Lambda表达式的使用和Disruptor高性能队列的基本原理和优势。
本文详细介绍了Java8中新增的并发工具,包括LongAdder如何通过分散热点来提高高并发场景下的性能,以及StampLock的乐观读策略。同时,文章还探讨了CompletableFuture的使用,包括创建实例、获取结果的方法以及其在异步编程中的优势。此外,还简要介绍了Lambda表达式的使用和Disruptor高性能队列的基本原理和优势。
一、原子操作CAS——LongAdder
JDK1.8时,java.util.concurrent.atomic包中提供了一个新的原子类:LongAdder。根据Oracle官方文档的介绍,LongAdder在高并发的场景下会比它的前辈——AtomicLong 具有更好的性能,代价是消耗更多的内存空间。AtomicLong是利用了底层的CAS操作来提供并发性的,调用了Unsafe类的getAndAddLong方法,该方法是个native方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。
在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时AtomicLong的自旋会成为瓶颈。这就是LongAdder引入的初衷——解决高并发环境下AtomicLong的自旋瓶颈问题。
AtomicLong中有个内部变量value保存着实际的long值,所有的操作都是针对该变量进行。也就是说,高并发环境下,value变量其实是一个热点,也就是N个线程竞争一个热点。
private final long value;
- LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。这种做法和ConcurrentHashMap中的“分段锁”其实就是类似的思路。
- LongAdder提供的API和AtomicLong比较接近,两者都能以原子的方式对long型变量进行增减。但是AtomicLong提供的功能其实更丰富,尤其是addAndGet、decrementAndGet、compareAndSet这些方法。
- addAndGet、decrementAndGet除了单纯的做自增自减外,还可以立即获取增减后的值,而LongAdder则需要做同步控制才能精确获取增减后的值。如果业务需求需要精确的控制计数,做计数比较,AtomicLong也更合适。另外,从空间方面考虑,LongAdder其实是一种“空间换时间”的思想,从这一点来讲AtomicLong更适合。
- 总之低并发、一般的业务场景下AtomicLong是足够了。如果并发量很多,存在大量写多读少的情况,那LongAdder可能更合适。适合的才是最好的,如果真出现了需要考虑到底用AtomicLong好还是LongAdder的业务场景,那么这样的讨论是没有意义的,因为这种情况下要么进行性能测试,以准确评估在当前业务场景下两者的性能,要么换个思路寻求其它解决方案。
对于LongAdder来说,内部有一个base变量,一个Cell[]数组。
base变量:非竞态条件下,直接累加到该变量上。
Cell[]数组:竞态条件下,累加个各个线程自己的槽Cell[i]中。
transient volatile Cell[] cells;
transient volatile long base;
所以,最终结果的计算应该是:
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
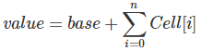
在实际运用的时候,只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对Cell[]数组中的单元Cell。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
而LongAdder最终结果的求和,并没有使用全局锁,返回值不是绝对准确的,因为调用这个方法时还有其他线程可能正在进行计数累加,所以只能得到某个时刻的近似值,这也就是LongAdder并不能完全替代LongAtomic的原因之一。而且从测试情况来看,线程数越多,并发操作数越大,LongAdder的优势越大,线程数较小时,AtomicLong的性能还超过了LongAdder。
二、其他新增
除了新引入LongAdder外,还有引入了它的三个兄弟类:LongAccumulator、DoubleAdder、DoubleAccumulator。LongAccumulator是LongAdder的增强版。LongAdder只能针对数值的进行加减运算,而LongAccumulator提供了自定义的函数操作。通过LongBinaryOperator,可以自定义对入参的任意操作,并返回结果(LongBinaryOperator接收2个long作为参数,并返回1个long)。
LongAccumulator内部原理和LongAdder几乎完全一样。
DoubleAdder和DoubleAccumulator用于操作double原始类型。
1、StampLock
StampedLock是Java8引入的一种新的锁机制,简单的理解可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读锁会完全阻塞写锁,它使用的依然是悲观的锁策略;如果有大量的读线程,他也有可能引起写线程的饥饿。
而StampedLock则提供了一种乐观的读策略,这种乐观策略的锁非常类似于无锁的操作,使得乐观锁完全不会阻塞写线程。它的思想是读写锁中读不仅不阻塞读,同时也不应该阻塞写。
读不阻塞写的实现思路:
在读的时候如果发生了写,则应当重读而不是在读的时候直接阻塞写!即读写之间不会阻塞对方,但是写和写之间还是阻塞的,StampedLock的内部实现是基于CLH的。
参考代码:
public class StampedLockDemo {
// 一个点的x,y坐标
private double x,y;
// Stamped类似一个时间戳的作用,每次写的时候对其+1来改变被操作对象的Stamped值,这样其它线程读的时候发现目标对象的Stamped改变,则执行重读
private final StampedLock slock = new StampedLock();
/**
* 【写锁(排它锁)】
*/
void move (double deltaX, double deltaY) {
//tampedLock调用writeLock和unlockWrite时候都会导致stampedLock的stamp值的变化 即每次+1,直到加到最大值,然后从0重新开始
long stamp = slock.writeLock();
try {
x += deltaX;
y += deltaY;
}finally {
slock.unlockWrite(stamp);
}
}
/**
* 【乐观读锁】
*/
double distanceFromOrigin() {
// tryOptimisticRead是一个乐观的读,使用这种锁的读不阻塞写 , 每次读的时候得到一个当前的stamp值(类似时间戳的作用)
long stamp = slock.tryOptimisticRead();
// 这里就是读操作,读取x和y,因为读取x时,y可能被写了新的值,所以下面需要判断
double currentX = x, currentY = y;
/*
* 如果读取的时候发生了写,则stampedLock的stamp属性值会变化,此时需要重读,
* validate():比较当前stamp和获取乐观锁得到的stamp比较,不一致则失败。
* 再重读的时候需要加读锁(并且重读时使用的应当是悲观的读锁,即阻塞写的读锁)
* 当然重读的时候还可以使用tryOptimisticRead,此时需要结合循环了,即类似CAS方式
* 读锁又重新返回一个stampe值
*/
if(!slock.validate(stamp)) {//如果验证失败(读之前已发生写)
stamp = slock.readLock(); //悲观读锁
try {
currentX = x;
currentY = y;
}finally {
slock.unlockRead(stamp);
}
}
return Math.sqrt(currentX *currentX + currentY *currentY);
}
/**
* 读锁升级为写锁
*/
void moveIfAtOrigin(double newX, double newY) { // upgrade
// 读锁(这里可用乐观锁替代)
long stamp = slock.readLock();
try {
//循环,检查当前状态是否符合
while (x == 0.0 && y == 0.0) {
long ws = slock.tryConvertToWriteLock(stamp);
//如果写锁成功
if (ws != 0L) {
stamp = ws;// 替换stamp为写锁戳
x = newX;//修改数据
y = newY;
break;
}
//转换为写锁失败
else {
slock.unlockRead(stamp); //释放读锁
//获取写锁(必要情况下阻塞一直到获取写锁成功)
stamp = slock.writeLock();
}
}
} finally {
slock.unlock(stamp); //释放锁(可能是读/写锁)
}
}
}
2、CompleteableFuture
Future的不足:Future是Java
5添加的类,用来描述一个异步计算的结果。你可以使用isDone方法检查计算是否完成,或者使用get阻塞住调用线程,直到计算完成返回结果,你也可以使用cancel方法停止任务的执行。
虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的CPU资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式当计算结果完成及时通知监听者呢?
Java的一些框架,比如Netty,自己扩展了Java的 Future接口,提供了addListener等多个扩展方法,Google guava也提供了通用的扩展Future:ListenableFuture、SettableFuture 以及辅助类Futures等,方便异步编程。同时Future接口很难直接表述多个Future 结果之间的依赖性。实际开发中,我们经常需要达成以下目的:
- 将两个异步计算合并为一个,这两个异步计算之间相互独立,同时第二个又依赖于第一个的结果。
- 等待 Future 集合中的所有任务都完成。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









