









📚 今日学习路径
graph TD
A[环境准备] --> B[案例:线性回归模型]
B --> C[数学原理解析]
C --> D[Python实现]
D --> E[模型可视化]
E --> F[扩展思考]
🛠️ 环境配置(Python版)
# 安装必备库
pip install numpy matplotlib
# 验证安装
import numpy as np
import matplotlib.pyplot as plt
print("当前numpy版本:", np.__version__)
🧠 核心案例:单变量线性回归
数据集生成
# 生成训练数据(Java开发者注意:Python不需要显式定义main方法)
np.random.seed(42)
X = 2 * np.random.rand(100, 1) # 生成0-2区间100个数据点
y = 4 + 3 * X + np.random.randn(100, 1) # 真实关系式 + 噪声
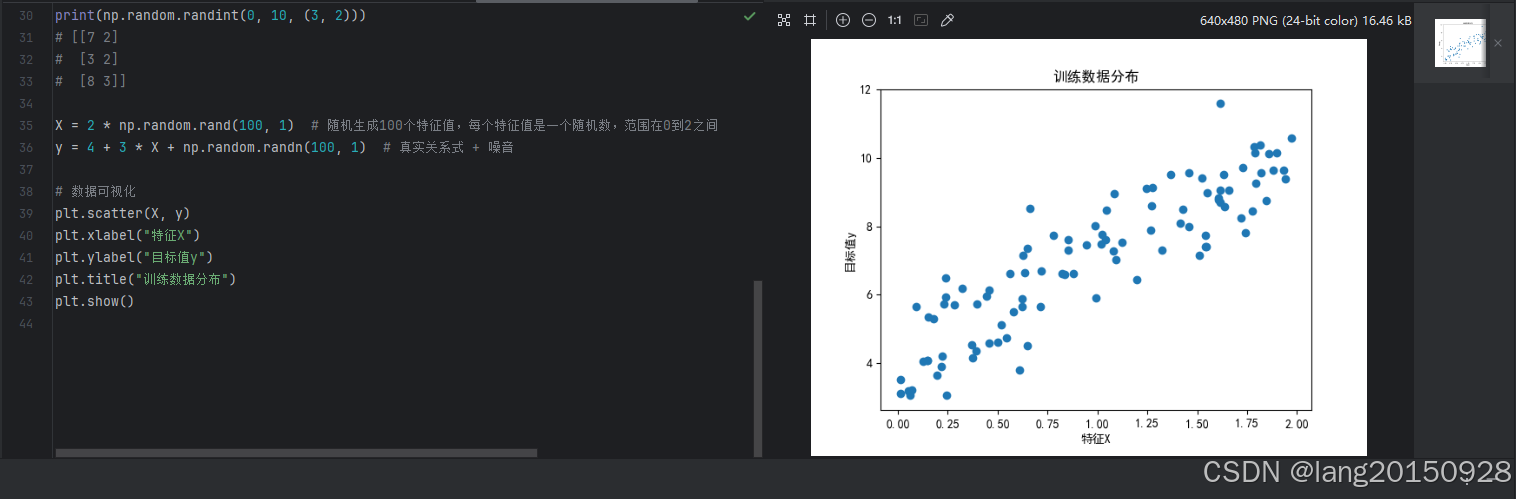
# 数据可视化
plt.scatter(X, y)
plt.xlabel("特征X")
plt.ylabel("目标值y")
plt.title("训练数据分布")
plt.show()
数学原理
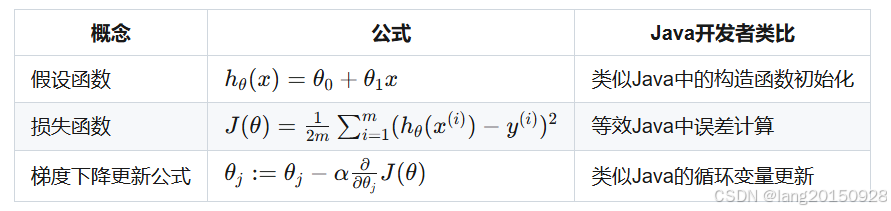
Python实现
class LinearRegression:
def __init__(self, learning_rate=0.01, n_epochs=100):
self.lr = learning_rate # 学习率
self.epochs = n_epochs # 迭代次数
self.theta = None # 参数向量
def fit(self, X, y):
m = X.shape[0] # X.shape[0]表示X的行数,即样本数量,X.shape[1]表示X的列数.此处m是样本数量
# 使用np.c_将一个全为1的列向量(形状为(m,1))与输入矩阵X连接起来,得到一个(m,2)的矩阵
# 目的是为每个样本添加一个偏置项 x0=1,以便模型可以学习偏置参数(即截距项)
X_b = np.c_[np.ones((m, 1)), X] # 添加偏置项x0=1
print(f"X_b={X_b}")
# 使用 np.random.randn(2, 1) 随机生成一个形状为 (2, 1) 的参数向量 theta
# 参数向量包含两个部分:偏置项和权重项
self.theta = np.random.randn(2, 1) # 随机初始化参数
print(f"theta={self.theta}")
for epoch in range(self.epochs):
# 梯度下降更新参数
# X_b.dot(self.theta)表示矩阵X_b和参数向量theta的点积,得到预测值
# X_b.dot(self.theta) - y表示预测值与真实值之间的差值
# X_b.T.dot(X_b.dot(self.theta) - y) 表示矩阵X_b的转置和差值的点积
# (1 / m) * X_b.T.dot(X_b.dot(self.theta) - y)表示损失函数的梯度,即损失函数对参数的偏导数
gradients = (1 / m) * X_b.T.dot(X_b.dot(self.theta) - y)
# 使用梯度下降法更新参数
# self.lr * gradients:学习率乘以梯度,表示参数调整的步长
# self.theta -= ...:从当前参数中减去步长,完成一次参数更新
self.theta -= self.lr * gradients
# 每20次打印损失值(类似Java的调试输出)
if epoch % 20 == 0:
# X_b.dot(self.theta) - y:预测值与真实值之间的误差
# np.sum((...) ** 2):计算误差平方和
# (1 / (2 * m)):将误差平方和除以 2m,得到均方误差(MSE)
loss = (1 / (2 * m)) * np.sum((X_b.dot(self.theta) - y) ** 2)
print(f"Epoch {epoch:3d} | Loss: {loss:.4f}")
def predict(self, X):
X_b = np.c_[np.ones((len(X), 1)), X]
return X_b.dot(self.theta)
📊 执行与验证
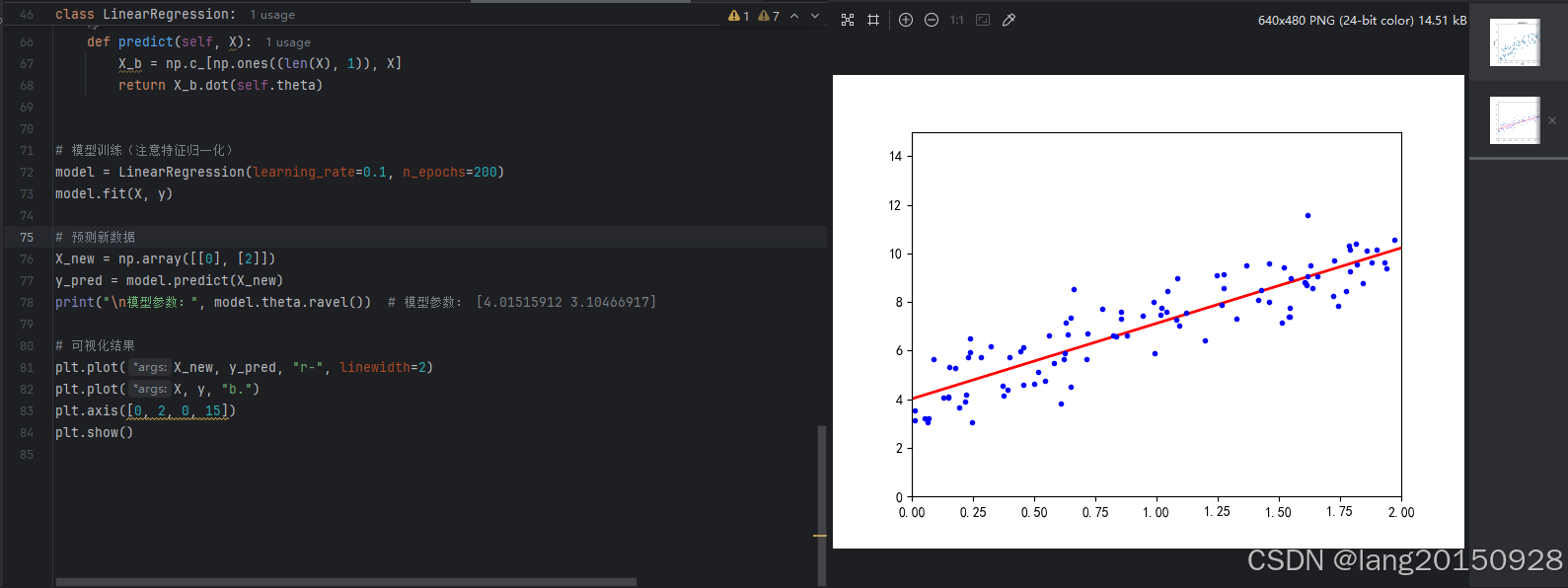
# 模型训练(注意特征归一化)
model = LinearRegression(learning_rate=0.1, n_epochs=200)
model.fit(X, y)
# 预测新数据
X_new = np.array([[0], [2]])
y_pred = model.predict(X_new)
print("\n模型参数:", model.theta.ravel())
# 可视化结果
plt.plot(X_new, y_pred, "r-", linewidth=2)
plt.plot(X, y, "b.")
plt.axis([0, 2, 0, 15])
plt.show()
💡 课后思考题
应用题(难度:⭐️)
当梯度下降停止时,以下哪些条件可能被触发?(多选)
A) 损失值变化小于阈值
B) 达到预设最大迭代次数
C) 梯度向量接近零
D) 学习率达到指定值
参考答案:A、B、C
解析:学习率是固定超参数,不会作为停止条件
代码分析题(难度:⭐️⭐️)
下列哪个操作在梯度计算时效率最高?(假设数据量极大)
# 实现1
gradients = (X_b.T @ (X_b @ theta - y)) / m
# 实现2
error = X_b @ theta - y
gradients = np.zeros(2)
for j in range(2):
gradients[j] = (error * X_b[:, j]).mean()
# 实现3
gradients = []
for j in range(2):
grad = 0
for i in range(m):
grad += (X_b[i] @ theta - y[i]) * X_b[i, j]
gradients.append(grad/m)
答案分析:实现1最优
原因:基于NumPy的向量化计算比循环快100倍以上(参考Java的流式处理优化原理)
原理探究题(难度:⭐️⭐️⭐️)
若学习率α设置过大,可能导致:________
若α过小,可能引发:________
参考答案:
α过大 → 损失函数震荡不收敛
α过小 → 收敛速度过慢,易陷入局部最优
🚀 阶段总结
| 对比维度 | Java开发经验参考 | Python/AI学习要点 |
| 语法差异 | 强类型vs动态类型 | 理解numpy的广播机制 |
| 编程范式 | OOP主导 | 函数式编程与向量化操作的重要性 |
| 调试方式 | IDE单步调试 | Matplotlib可视化调试 |
| 并发处理 | 多线程/线程池 | 数据并行(如Spark MLlib) |
📝 附录:标准化开发流程
1. 问题定义 → 2. 数据收集 → 3. 特征工程 → 4. 模型搭建
↑ ↓
8. 项目部署 ← 7. 超参调优 ← 6. 模型评估 ← 5. 模型训练
🔜 明日学习建议
- 扩展案例:多元线性回归(类似Java的多维数组处理)
- 探索Scikit-learn库的使用(对照Java的Weka库)
- 模型评估指标:MSE、R² score的实现原理
📝 完整案例
import sys
import numpy as np
import matplotlib.pyplot as plt
print(f"当前Python版本为:{sys.version}") # 当前Python版本为:3.9.21 (main, Dec 11 2024, 16:35:24) [MSC v.1929 64 bit (AMD64)]
print(f"当前numpy版本为:{np.__version__}") # 当前numpy版本为:1.26.4
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 生成训练数据(Python不需要定义main方法)
np.random.seed(42)
X = 2 * np.random.rand(4, 1) # 随机生成4个特征值,每个特征值是一个随机数,范围在0到2之间
y = 4 + 3 * X + np.random.randn(4, 1) # 真实关系式 + 噪音
print(X)
# [[0.74908024]
# [1.90142861]
# [1.46398788]
# [1.19731697]]
print(y)
# [[6.01308734]
# [9.47014888]
# [9.97117647]
# [8.35938563]]
m = X.shape[0] # X.shape[0]表示X的行数,即样本数量,X.shape[1]表示X的列数.此处m是样本数量
print(m) # 输出样本数量4
# 生成一个全为1的列向量(形状为(m,1))
print(np.ones((m, 1)))
# [[1.]
# [1.]
# [1.]
# [1.]]
# 使用np.c_将一个全为1的列向量(形状为(m,1))与输入矩阵X连接起来,得到一个(m,2)的矩阵
X_b = np.c_[np.ones((m, 1)), X]
print(X_b)
# [[1. 0.74908024]
# [1. 1.90142861]
# [1. 1.46398788]
# [1. 1.19731697]]
# 矩阵转置
print("X_b.T:", X_b.T)
# X_b.T: [[1. 1. 1. 1. ]
# [0.74908024 1.90142861 1.46398788 1.19731697]]
# 矩阵乘法
print(X_b.T.dot(X_b))
# [[4. 5.3118137 ]
# [5.3118137 7.75338042]]
import sys
import numpy as np
import matplotlib.pyplot as plt
print(f"当前Python版本为:{sys.version}") # 当前Python版本为:3.9.21 (main, Dec 11 2024, 16:35:24) [MSC v.1929 64 bit (AMD64)]
print(f"当前numpy版本为:{np.__version__}") # 当前numpy版本为:1.26.4
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 生成训练数据(Python不需要定义main方法)
np.random.seed(42)
X = 2 * np.random.rand(100, 1) # 随机生成100个特征值,每个特征值是一个随机数,范围在0到2之间
y = 4 + 3 * X + np.random.randn(100, 1) # 真实关系式 + 噪音
# 数据可视化
plt.scatter(X, y)
plt.xlabel("特征X")
plt.ylabel("目标值y")
plt.title("训练数据分布")
plt.show()
class LinearRegression:
def __init__(self, learning_rate=0.01, n_epochs=100):
self.lr = learning_rate # 学习率
self.epochs = n_epochs # 迭代次数
self.theta = None # 参数向量
def fit(self, X, y):
m = X.shape[0] # X.shape[0]表示X的行数,即样本数量,X.shape[1]表示X的列数.此处m是样本数量
# 使用np.c_将一个全为1的列向量(形状为(m,1))与输入矩阵X连接起来,得到一个(m,2)的矩阵
# 目的是为每个样本添加一个偏置项 x0=1,以便模型可以学习偏置参数(即截距项)
X_b = np.c_[np.ones((m, 1)), X] # 添加偏置项x0=1
print(f"X_b={X_b}")
# 使用 np.random.randn(2, 1) 随机生成一个形状为 (2, 1) 的参数向量 theta
# 参数向量包含两个部分:偏置项和权重项
self.theta = np.random.randn(2, 1) # 随机初始化参数
print(f"theta={self.theta}")
for epoch in range(self.epochs):
# 梯度下降更新参数
# X_b.dot(self.theta)表示矩阵X_b和参数向量theta的点积,得到预测值
# X_b.dot(self.theta) - y表示预测值与真实值之间的差值
# X_b.T.dot(X_b.dot(self.theta) - y) 表示矩阵X_b的转置和差值的点积
# (1 / m) * X_b.T.dot(X_b.dot(self.theta) - y)表示损失函数的梯度,即损失函数对参数的偏导数
gradients = (1 / m) * X_b.T.dot(X_b.dot(self.theta) - y)
# 使用梯度下降法更新参数
# self.lr * gradients:学习率乘以梯度,表示参数调整的步长
# self.theta -= ...:从当前参数中减去步长,完成一次参数更新
self.theta -= self.lr * gradients
# 每20次打印损失值(类似Java的调试输出)
if epoch % 20 == 0:
# X_b.dot(self.theta) - y:预测值与真实值之间的误差
# np.sum((...) ** 2):计算误差平方和
# (1 / (2 * m)):将误差平方和除以 2m,得到均方误差(MSE)
loss = (1 / (2 * m)) * np.sum((X_b.dot(self.theta) - y) ** 2)
print(f"Epoch {epoch:3d} | Loss: {loss:.4f}")
def predict(self, X):
X_b = np.c_[np.ones((len(X), 1)), X]
return X_b.dot(self.theta)
# 模型训练(注意特征归一化)
model = LinearRegression(learning_rate=0.1, n_epochs=200)
model.fit(X, y)
# 预测新数据
X_new = np.array([[0], [2]])
y_pred = model.predict(X_new)
print("\n模型参数:", model.theta.ravel()) # 模型参数: [4.01515912 3.10466917]
# 可视化结果
plt.plot(X_new, y_pred, "r-", linewidth=2)
plt.plot(X, y, "b.")
plt.axis([0, 2, 0, 15])
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











