






目录
环境准备
在开始今天的课程之前,请确保以下环境已正确安装并配置:
- Python 3.9 或更高版本
- NumPy 库 (
pip install numpy) - Matplotlib 库 (
pip install matplotlib)
验证安装是否成功:
import numpy as np
import matplotlib.pyplot as plt
print("当前numpy版本:", np.__version__)
案例:逻辑回归模型
背景
昨天我们学习了多元线性回归模型。今天我们将进一步探索 逻辑回归,一种用于分类问题的机器学习算法。
假设我们要预测一封邮件是否是垃圾邮件(0 表示正常邮件,1 表示垃圾邮件)。这正是逻辑回归的应用场景。
数据生成
我们将模拟一个简单的二分类数据集。
import sys
import numpy as np
import matplotlib.pyplot as plt
print(f"当前Python版本为:{sys.version}") # 当前Python版本为:3.9.21 (main, Dec 11 2024, 16:35:24) [MSC v.1929 64 bit (AMD64)]
print(f"当前numpy版本为:{np.__version__}") # 当前numpy版本为:1.26.4
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 设置随机种子,确保结果可复现
np.random.seed(42)
# 生成训练数据
m = 100 # 样本数量
X = np.random.rand(m, 2) # 生成两个特征的数据点
# 定义真实关系式
# 如果X的第一列和第二列的和大于1,则标记为垃圾邮件(值为1),否则标记为非垃圾邮件(值为0)
# 布尔值 True 转换为整数 1,布尔值 False 转换为整数 0.
# (X[:, 0] + X[:, 1] > 1) 生成的是一个 NumPy 布尔数组,因此可以使用 astype(int) 方法将其转换为整数数组.内置函数则使用 print(int(2 > 1))
y = (X[:, 0] + X[:, 1] > 1).astype(int) # 如果 x1 + x2 > 1,则为垃圾邮件
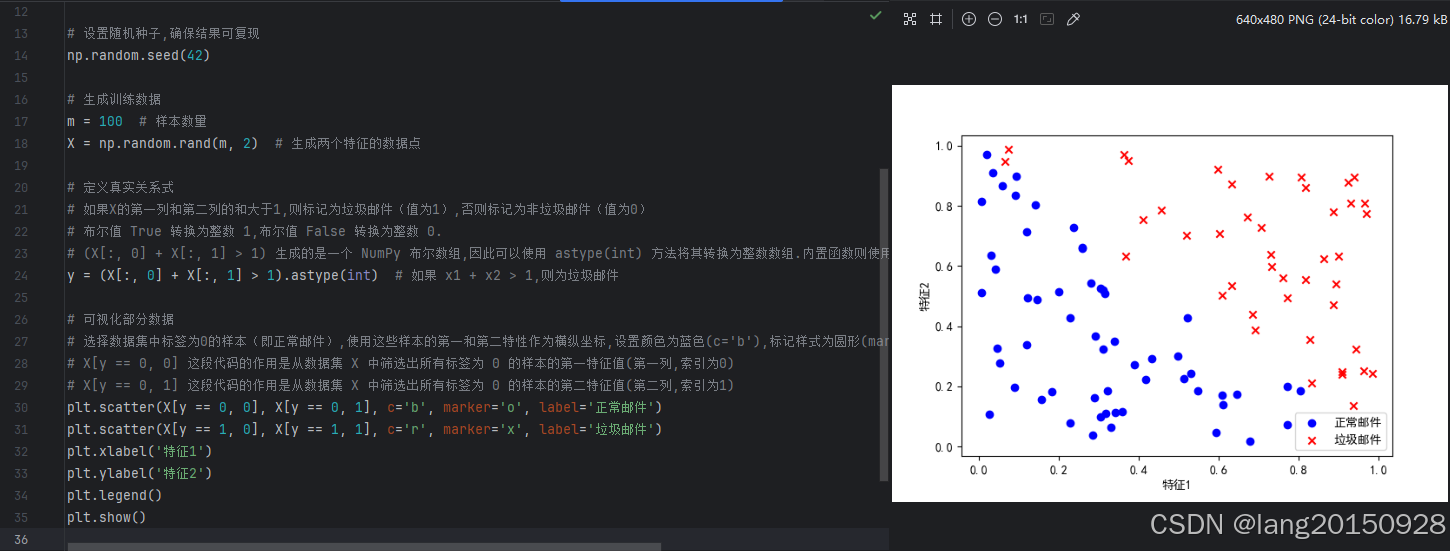
# 可视化部分数据
# 选择数据集中标签为0的样本(即正常邮件),使用这些样本的第一和第二特性作为横纵坐标,设置颜色为蓝色(c='b'),标记样式为圆形(marker='o'),并添加图例标签为'正常邮件'
# X[y == 0, 0] 这段代码的作用是从数据集 X 中筛选出所有标签为 0 的样本的第一特征值(第一列,索引为0)
# X[y == 0, 1] 这段代码的作用是从数据集 X 中筛选出所有标签为 0 的样本的第二特征值(第二列,索引为1)
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='b', marker='o', label='正常邮件')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='r', marker='x', label='垃圾邮件')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
plt.show()
数学原理解析

Python实现
定义逻辑回归类
class LogisticRegression:
def __init__(self, learning_rate=0.01, n_epochs=100):
self.lr = learning_rate # 学习率
self.epochs = n_epochs # 迭代次数
self.theta = None # 参数向量
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
m, n = X.shape # 样本数量和特征数量
X_b = np.c_[np.ones((m, 1)), X] # 添加偏置项 x0=1
# 随机初始化参数向量 theta
self.theta = np.random.randn(n + 1, 1)
for epoch in range(self.epochs):
z = X_b.dot(self.theta)
h = self.sigmoid(z)
gradients = (1 / m) * X_b.T.dot(h - y.reshape(-1, 1))
self.theta -= self.lr * gradients
if epoch % 20 == 0:
loss = (-1 / m) * np.sum(y * np.log(h + 1e-5) + (1 - y) * np.log(1 - h + 1e-5))
print(f"Epoch {epoch:3d}| Loss: {loss:.4f}")
def predict_proba(self, X):
m = len(X)
X_b = np.c_[np.ones((m, 1)), X]
return self.sigmoid(X_b.dot(self.theta))
def predict(self, X):
return (self.predict_proba(X) >= 0.5).astype(int).ravel()
模型训练与预测
# 创建模型实例
model = LogisticRegression(learning_rate=0.1, n_epochs=200)
# 训练模型
model.fit(X, y)
# 打印模型参数
print("\n模型参数:", model.theta.ravel())
# 预测新数据
X_new = np.array([[0.1, 0.1], [0.8, 0.8]])
y_pred = model.predict(X_new)
print("\n预测结果:", y_pred)
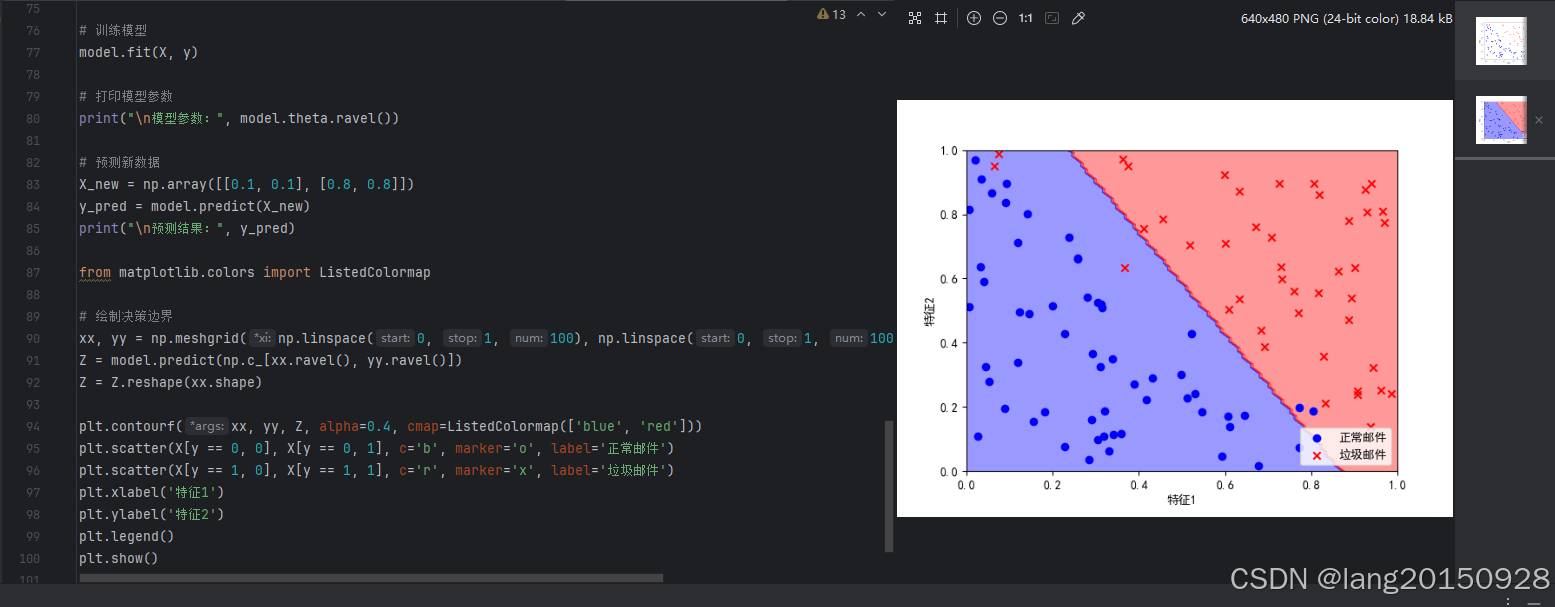
模型可视化
from matplotlib.colors import ListedColormap
# 绘制决策边界
xx, yy = np.meshgrid(np.linspace(0, 1, 100), np.linspace(0, 1, 100))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4, cmap=ListedColormap(['blue', 'red']))
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='b', marker='o', label='正常邮件')
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='r', marker='x', label='垃圾邮件')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
plt.show()
执行结果如下
当前Python版本为:3.9.21 (main, Dec 11 2024, 16:35:24) [MSC v.1929 64 bit (AMD64)]
当前numpy版本为:1.24.3
Epoch 0| Loss: 68.7178
Epoch 20| Loss: 68.7212
Epoch 40| Loss: 69.1516
Epoch 60| Loss: 69.5656
Epoch 80| Loss: 69.9358
Epoch 100| Loss: 70.2885
Epoch 120| Loss: 70.6434
Epoch 140| Loss: 71.0103
Epoch 160| Loss: 71.3926
Epoch 180| Loss: 71.7909
模型参数: [-1.35725373 1.56133637 0.98597927]
预测结果: [0 1]
扩展思考
思考题 1
逻辑回归模型中的损失函数为什么使用对数损失而不是均方误差?
参考答案:
逻辑回归是一个分类问题,而均方误差适用于回归问题。对数损失能够更好地衡量分类任务中预测概率与真实标签之间的差异。
思考题 2
如果模型的预测结果总是偏向某一类(如总是预测为 0),可能是什么原因?
参考答案:
可能是数据不平衡导致的。可以通过调整类别权重或使用过采样/欠采样技术来解决。
思考题 3
如何判断逻辑回归模型是否存在过拟合或欠拟合?
参考答案:
过拟合:模型在训练集上表现很好,但在测试集上表现较差。可以通过增加正则化项或减少模型复杂度来缓解。
欠拟合:模型在训练集和测试集上表现都不好。可以通过增加模型复杂度或添加更多特征来改善。
总结
今天的学习重点是逻辑回归模型的实现与应用。通过今天的练习,您应该能够:
- 理解逻辑回归的基本原理;
- 使用Python实现梯度下降算法;
- 对模型进行可视化分析。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











