









 本文探讨了C/C++中的内存对齐问题,通过实例揭示了内存对齐的原因和规则。内存对齐是为了满足硬件平台的访问限制和提高CPU的内存访问效率,通过对结构体成员和整体大小的特定对齐方式,确保数据存储的规范性。
本文探讨了C/C++中的内存对齐问题,通过实例揭示了内存对齐的原因和规则。内存对齐是为了满足硬件平台的访问限制和提高CPU的内存访问效率,通过对结构体成员和整体大小的特定对齐方式,确保数据存储的规范性。
- 从一个例子引出内存对齐:
#include<iostream>
using namespace std;
struct st1{
char a;
int b;
short c;
}s1;
struct st2{
short c;
char a;
int b;
}s2;
int main()
{
cout << "sizeof(s1) is " << sizeof(s1) << endl;
cout << "sizeof(s2) is " << sizeof(s2) << endl;
system("pause");
return 0;
}按照正常的思维,在32位操作系统下,int占4个字节,char占一个字节,short占2个字节,那么这一个结构体应该占用7个字节,然后运行上述程序结果如下,结构体s1占12个字节,结构体s2占8个字节。进一步我们发现这两个结构体里面的成员变量类型虽然一样,但是变量顺序不同,可能是导致两个结构体所占的内存不同原因,那这是怎么回事呢?
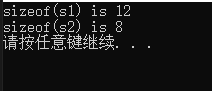
查阅之后,说这是一个内存对齐的问题,那么什么是内存对齐呢?我们知道现代计算机的内存空间管理都是以字节进行划分的,似乎对于任何类型的变量都可以从任意地址开始,但是实际的计算机系统会对基本类型的数据在内存中存放的位置有限制,会要求这些数据的首地址的值是某个数k(通常是4或者8)的倍数,这就是所谓的内存对齐。
- 为什么要用内训对齐呢?
先看一下内存对齐的规则:
- 对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是min(#param pack()指定的数,这个数据成员的自身长度)的倍数。
- 在数据成员完成各自对其之后,结构体本身也要进行对齐,对齐将按照#param pack指定的数值或者结构的最大数据成员长度中,比较小的那个进行。
其中#param pack该预处理指令用来改变对齐参数,默认情况下,C编译器为每一个变量或者数据单元按照其自然对界条件分配空间,也可以通过下面的方法来改变对齐参数:
使用伪指令#param pack(n),c编译器将按照n字节对齐
使用伪指令#param pack(),取消自定义字节的对齐方式以上面的程序为解释一下对其的规则为:
S1:char占一个字节,起始偏移为0,int占4个字节,min(#param pack()指定的数,这个数据成员的自身长度)=4,所以int按照4字节进行对齐,起始偏移必须为4,在char后编译器会添加3个额外字节,short占2个字节,加上前面的char和int,所以short起始偏移为8,正好是2的倍数,无需添加额外的字节,此时规则1的成员对齐结束,内存状态为:

总共是10个字节,还要进行结构本身对齐,S1结构中对大数据成员长度为int,4个字节。而默认的#param pack指定的值为8,所以按照规则2,以4字节进行对齐,即结构本身必须是4的倍数,需要添加2个额外的字节使结构本身大小为12。此时的内存状态为:
![]()
到此内存对齐结束,S1占用了12个字节而非7个字节。同理对结构体S2进行分析,short占两个字节,偏移为0,char占1个字节偏移是2,int占4个字节,偏移是4,所以要在char后面补上一个字节,总共刚好是8个字节,是4的倍数,所以最终结构大小为8个字节。
- 所以进行内存对齐的主要作用是:
- 平台原因:不是所有的硬件平台都能访问任意地址上的数据,某些硬件平台只能在某些地址处取某些特定累心多个数据,否则抛出硬件异常
- 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。

















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









