







MySQL索引基础
提到MySQL数据库索引,我想大家应该不陌生,在日常工作中我们也是经常接触到。当遇到某一个SQL查询很慢时,经过分析原因后,可能会给某个字段加个索引。但是什么是索引,为什么加索引,以及索引是如何工作的,就是我们今天讨论的话题。
什么是索引
我们知道索引就是为了提高我们查询数据库的效率。就像我们在看一本书,如果我们想了解某个章节的内容,我们可以通过查询目录,找到对应的章节,而不用直接从书中一页一页的翻找。其实数据库的索引就类似于书本的“目录”。
索引的分类
上面的介绍使我们大概了解索引的概念。但是有时候我们会听到各种各样的索引,比如:主键索引、聚簇索引、普通索引、唯一索引等等。
这些索引具体是怎么分类的呢,我们可以从以下四个角度划分:
- 数据结构划分:B+tree索引、Hash索引、Full-text索引
- 物理存储划分:聚簇索引(主键索引)、二级索引
- 逻辑功能划分:主键索引、唯一索引、普通索引
- 字段个数划分:单列索引、联合索引
常见的索引结构
我们知道索引是为了能更好的查询数据,但是索引本身也很大,不可能全部存储到内存里,因此索引往往以索引文件的形式存储到磁盘上。
Hash索引以哈希表为存储数据结构的索引,哈希的思路很简单,就是将值放到数组里,用哈希函数将key换算成确定的位置,然后吧value值放到这个数组的的位置。
但是不可避免的是,多个key值进过哈希函数的运算,会出现同一个值的问题,这个时候就需要拉一个链表。
哈希结构在查找某个区间的时候是很慢的,一般只适合等值查询的场景。
学过二叉搜索树的都知道,二叉搜索树的特点是,每个节点的左儿子小于父节点,父节点又小于右儿子。但是在实际的数据库存储中并不使用二叉树,主要是由于索引不止存在内存中,还要写到磁盘。
如果有上百万个节点,那二叉树的高度也太高了,此时需要的磁盘IO开销也就很大。
InnoDB的索引结构
在前面我们提到我们现在使用的MySQL默认存储基本上都是InnoDB,而InnoDB使用的是B+树索引模型,所有的数据都是存储在B+树中的。
每一个索引在InnoDB里对应一棵B+树中的。
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engin=InnoDB;
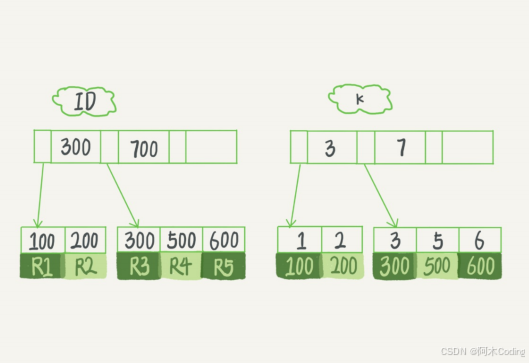
从上图可以看出,索引类型分为主键索引和非主键索引。
主键索引(InnoDB中也称为聚簇索引)的叶子节点是整行数据。
非主键索引的叶子结点是主键的值,非主键索引也叫做二级索引
下面我们讨论一个常见的面试题
基于主键索引和普通索引查询有什么区别?
- 如果查询语句select * from T where id=500,根据主键查询,只需要搜索id这颗B+树
- 如果语句是select * from T where k=5,根据普通索引查询,需要先搜索k索引这棵树,得到Id的值500,再根据id到id索引树搜索,这也就是回表的过程。
主键是否需要自增
在工作中,我们经常会被要求在建表过程中使用自增主键,这样插入新纪录时可以不指定Id值,系统会获取当前id最大值加1作为下一条记录的Id值。
这么做有什么好处?说到这我们先提出一个页分裂的概念,比如在上图中我们需要插入一个Id=400的值,而当前页的数据已经满了,根据B+树的算法,这个时候需要申请一个新的数据页,然后将部分数据挪到后面的数据页。这种情况相爱性能自然会受影响。
有了页分裂就会有业合并,当相邻的两个页由于删除了数据,利用率很低之后,会将数据页合并。
而使用自增主键,每次插入一条新数据,都会追加操作,不会涉及挪动其他数据,自然不会触发叶子节点的分裂。
并且使用自增主键,可以保证有序插入,写数据的成本会相对较低。
另外如果使用其他的业务字段作为主键索引,我们知道非主键索引的叶子节点都是主键的值,一般情况占用的字节会比较多,所以从性能和存储空间的角度考虑,自增主键大多数场景是比较合适的。
什么场景适合业务字段直接做主键?
- 只有一个索引
- 该索引必须是唯一索引
这种也就是典型的KV场景,没有其他索引,不需要考虑索引的叶子节点大小的问题。
覆盖索引
在说覆盖索引之前,我们先看一个查询语句
select * from T where k between 3 and 5;
通过上面主键索引和普通索引的题目,我们可以知道这条SQL查询语句的执行流程:
- 在k索引树上找到k=3的记录,取得Id=300
- 再到Id索引树查到Id=300对应的R3
- 在k索引树取下一个值k=5,取得Id=500
- 再回到Id索引树查到Id=500对应的R4
- 在k索引树取下一个值k=6,不满足,循环结束
这条查询语句由于查询整条记录,所以在通过k索引树,查到主键Id,还有一个回表的过程,通过主键索引,查询
整条记录。
但是如果查询语句是:
select id from T where k between 3 and 5;
由于主键id已经在k索引树,可以直接查询得到,不需要回表,这样索引k已经覆盖了查询需求,也就是覆盖索引。
覆盖索引可以减少树搜索次数,显著提升查询性能,所以覆盖索引是一个常用的性能优化手段。
联合索引
在工作中,我们需要查询的字段有时候会很多,如果每一种查询都设计一个索引,那索引就太多了,毕竟索引也要占空间的。
那我们就可以使用联合索引。
联合索引中有一个最左前缀原则:
craete Table `tuser`(
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY(`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
)engine=InnoDB
我们创建上述表,并创建了一个(name,age)的联合索引。当我们查询:
select * from tuser where name like '张%'
会查到第一个名字以“张”开头的用户,然后向后遍历,直到不满足条件为止。
由于我们创键了联合索引,所以其实就不需要为name字段单独创建索引。
索引下推
上面我们说到了最左前缀原则,但是如果不符合最左前缀的部分该怎么办。
select * from tuser where name like '张%' and age=10 and ismale=1;
由于做前缀原则,查到name以“张”开头的数据后,在MySQL5.6前,一个个回表,到主键索引上找出数据行,再对比字段值。MySQL5.6之后引入索引下推,在索引遍历过程,对索引中包含的字段先判断,直接过滤不满足的条件,减少回表次数。
大家觉的不错可以关注一下我的公众号:阿木Coding,每天都会分享一些面试的干货,期待你的关注。



















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











