









 回归问题属于监督学习,目标是发现输入与连续输出之间的关系,例如房价预测。本文介绍了回归问题中的平方误差成本函数、梯度下降法、多元变量成本函数、特征缩放和正则化等概念,并涉及多项式回归、逻辑回归、决策边界和过拟合与欠拟合等主题。
回归问题属于监督学习,目标是发现输入与连续输出之间的关系,例如房价预测。本文介绍了回归问题中的平方误差成本函数、梯度下降法、多元变量成本函数、特征缩放和正则化等概念,并涉及多项式回归、逻辑回归、决策边界和过拟合与欠拟合等主题。
Regression Problems
Regression Problems
-
Supervised learning:
Given a data set that we already know the correct output is like, and want to discover the relationship between the input and the output.
supervised learning is catagorized into “regression” and “classification” problems.- regression - function that generate continuous output
- example:house price prediction
- classification - classify the target into catagories which is a discrete output
- example: classifying whether a tumor is malignant or benign
- regression - function that generate continuous output
-
Unsupervised learning:
Given a data set that doesn’t have any labels or has the same label, and want to find some structure in the data.-
clustering - group a large set of data into groups that is somehow similar or related by different variables or attributes.
- examples:
- News grouping
- Market segmentation
- examples:
-
non-clustering - find struction in a chaotic environment
- examples:
- Cocktail party problem - cocktail party algorithm
- examples:
-
Cost Function(Squared error function/Mean squared error):
J
=
1
2
m
∗
∑
i
=
1
n
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J = \frac{1}{2m}*\sum_{\mathclap{i=1}}^{n} (h_\theta(x^{(i)}) - y^{(i)})^2
J=2m1∗i=1∑n(hθ(x(i))−y(i))2
Either devided by 2 * m or m results in the same thetas, while 2 * m used here is for convenience when taking derivative.
We can cut this function into two parts:
J
(
θ
0
,
θ
1
)
y
(
j
)
=
h
(
x
j
)
=
θ
0
+
t
h
e
t
a
1
∗
x
j
J(\theta_0,\theta_1)\\ y(j) = h(x_j) = \theta_0 + theta_1 * x_j
J(θ0,θ1)y(j)=h(xj)=θ0+theta1∗xj
At first we can set
θ
\theta
θ to 0, and set
θ
\theta
θ to certain values and will get corresponding
h
(
x
)
h(x)
h(x). Then we take the training set to the function to calculate
h
(
x
i
)
h(x_i)
h(xi) and then take the result into the function J and get a discrete
J
(
0
,
θ
1
)
J(0, \theta_1)
J(0,θ1), as plotted below:
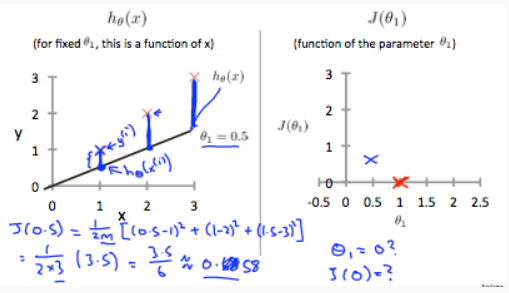
That’s when J is a univariable function. when
θ
0
\theta_0
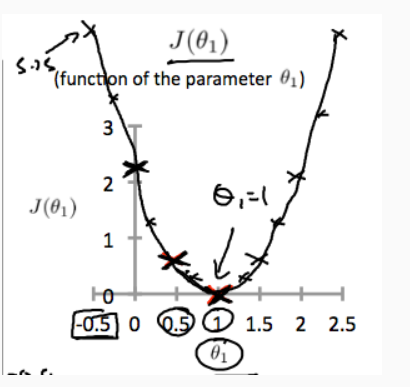
θ0 comes in, the J function would be plotted like this:
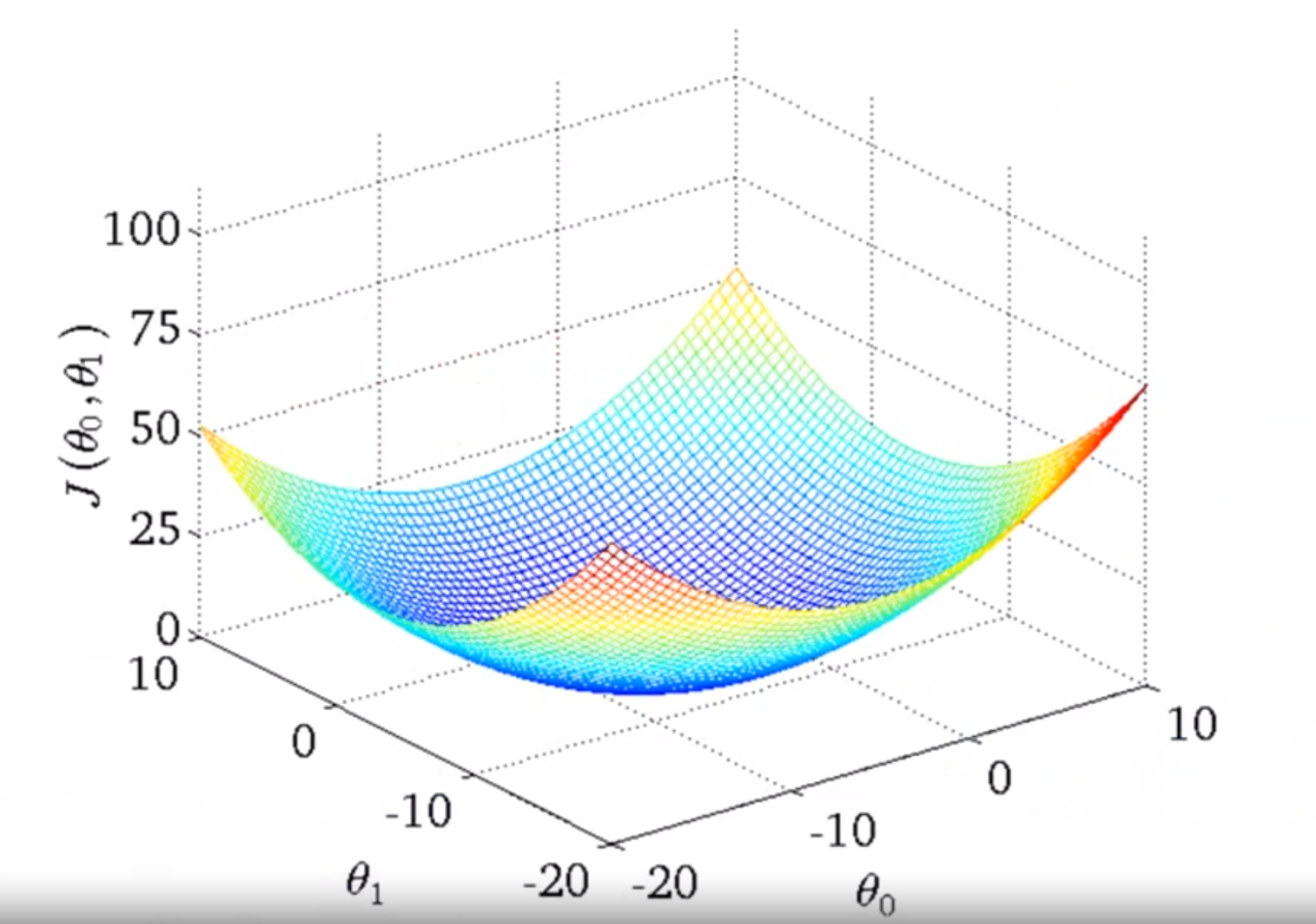
And transfer it in a contour plot will be like this:
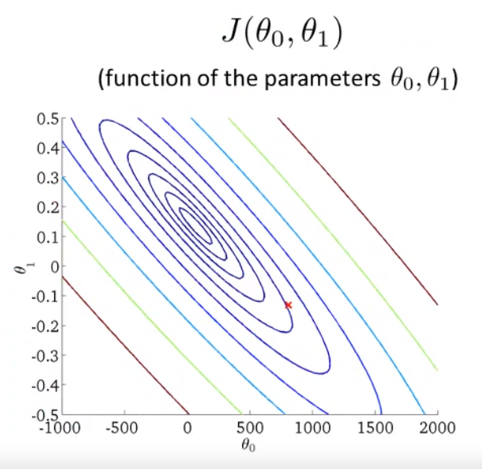
Plotting out our training set and select some fixed value for the two thetaes, we have hs of x. And we can point out the corresponding
J
(
θ
)
J(\theta)
J(θ). matching the hs and the Js gives a clear version of the relationship of these two functions:
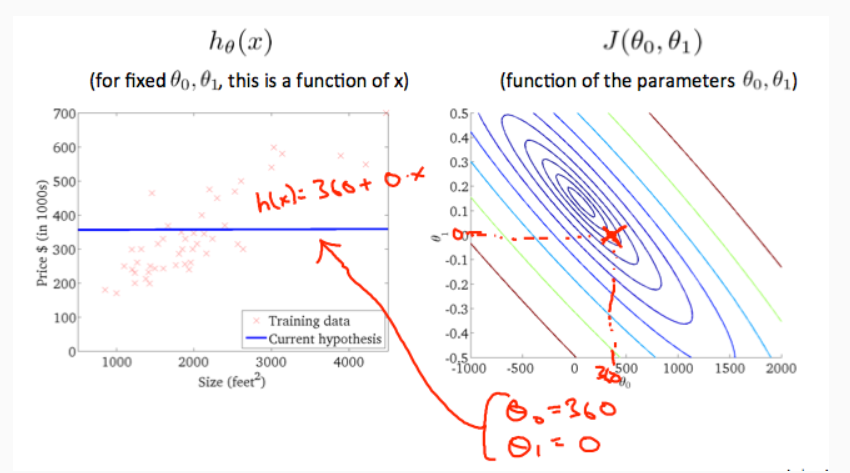
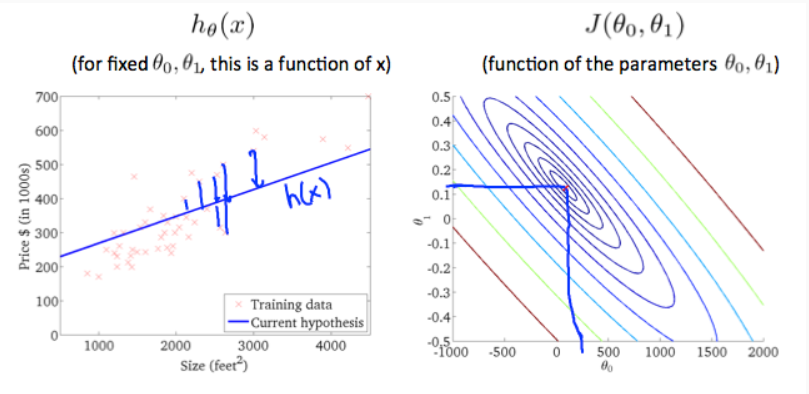
Gradient descent
To minimize all kinds of functions, we use gradient decent. when saying using gradient descent, we always mean that simultaneously subtract the variable.
As intuition in picture, we can say the descent comes as baby step as step walking down the hill, and finally reaching to the bottom of that route. If you start with another position on the hill, you would be reaching another bottom, while it might be real close to the first origin.
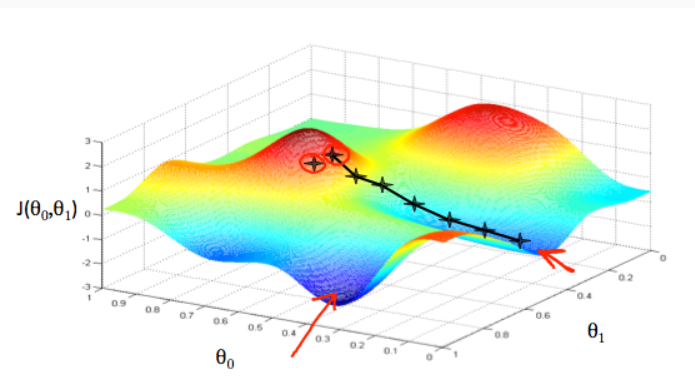
The algorithm is do the calculation repeatidly until convergence:
θ
i
:
=
θ
i
−
α
∂
∂
θ
i
J
(
θ
0
,
θ
1
,
.
.
.
)
\theta_i := \theta_i - \alpha\frac{\partial}{\partial\theta_i}J(\theta_0, \theta_1,...)
θi:=θi−α∂θi∂J(θ0,θ1,...)
The alpha is called the learning rate, which means the step we take when updating parameters and it’s always a positive number. While i is the index number.
Pay attention to what we saying simultaneously update the parameters, it means that calculating each parameters prior to updating them. We shall do it this way:
correct:
t
e
m
p
0
:
=
θ
0
−
α
∂
∂
θ
0
J
(
θ
0
.
.
.
)
t
e
m
p
1
:
=
θ
1
−
α
∂
∂
θ
1
J
(
θ
0
.
.
.
)
.
.
.
θ
0
=
t
e
m
p
0
θ
1
=
t
e
m
p
1
.
.
.
\text{correct:}\\ temp_0 := \theta_0 - \alpha\frac{\partial}{\partial\theta_0}J(\theta_0...)\\ temp_1 := \theta_1 - \alpha\frac{\partial}{\partial\theta_1}J(\theta_0...)\\ ...\\ \theta_0 = temp_0\\ \theta_1 = temp_1\\ ...
correct:temp0:=θ0−α∂θ0∂J(θ0...)temp1:=θ1−α∂θ1∂J(θ0...)...θ0=temp0θ1=temp1...
instead of doing it like this:
Incorrect:
t
e
m
p
0
:
=
θ
0
−
α
∂
∂
θ
0
J
(
θ
0
.
.
.
)
θ
0
=
t
e
m
p
0
t
e
m
p
1
:
=
θ
1
−
α
∂
∂
θ
1
J
(
θ
0
.
.
.
)
θ
1
=
t
e
m
p
1
.
.
.
{\text{Incorrect:}}\\ temp_0 := \theta_0 - \alpha\frac{\partial}{\partial\theta_0}J(\theta_0...)\\ \theta_0 = temp_0\\ temp_1 := \theta_1 - \alpha\frac{\partial}{\partial\theta_1}J(\theta_0...)\\ \theta_1 = temp_1\\ ...
Incorrect:temp0:=θ0−α∂θ0∂J(θ0...)θ0=temp0temp1:=θ1−α∂θ1∂J(θ0...)θ1=temp1...
In the algorithm, alpha controlls the rapidity that the parameter reaches the minimum. Either too small or too large is not appropriate. Too small will take it too many steps to the minimum which would cost a lot of time running the algorithm, while too large could overshot the minimum and may fail to convert or even divert.
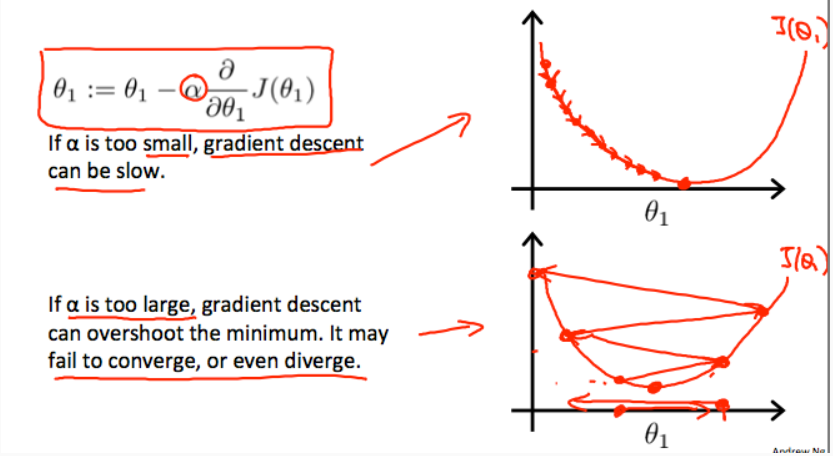
Batch Gradient Descent:
Refers that in every step of gradient descent we’re looking at all the training examples. So when computing the derivatives, we’re computing the sums of each square error
There are other versions of gradient descent that look at small subsets of the training sets at a time.
(note:’:=’ means assignment same as ‘=’ in java, ‘=’ here means equalty same as ‘==’ in java
Version of Cost Function with Multiple Variable
Hypothesis with multiple variable:
Use n to denote the number of features and $x_n$ denotes the value of nth feature. with combination with superscript m, we get the nth parameter of mth training example:
x
j
(
i
)
=
value of feature j in the
i
t
h
training example
x
(
i
)
=
the input(features) of the
i
t
h
training example
x_j^{(i)} = \text{value of feature j in the }i^{th} \text{ training example}\\ x^{(i)} = \text{the input(features) of the }i^{th} \text{ training example}
xj(i)=value of feature j in the ith training examplex(i)=the input(features) of the ith training example
So the hypothesis function becomes like this:
h
(
θ
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
h(\theta) = \theta_0 + \theta_1x_1 + \theta_2x_2 + ... + \theta_nx_n
h(θ)=θ0+θ1x1+θ2x2+...+θnxn
When we use vectors to describe, we assume there is a
x
0
x_0
x0 that equals 1, thus we get a vector that index from 0. assume
X
→
\overrightarrow{X}
X as a vector and parameters
θ
→
\overrightarrow{\theta}
θ as another vector, and we get two (n+1) by 1 vectors, and the function is like this:
h
(
θ
)
=
[
θ
0
θ
1
θ
2
.
.
.
θ
n
]
[
x
1
x
1
x
2
.
.
.
x
n
]
h(\theta) = \begin{bmatrix}\theta_0&\theta_1&\theta_2&...&\theta_n\end{bmatrix}\begin{bmatrix}x_1\\x_1\\x_2\\...\\x_n\end{bmatrix}
h(θ)=[θ0θ1θ2...θn]⎣⎢⎢⎢⎢⎡x1x1x2...xn⎦⎥⎥⎥⎥⎤
which is called multivariate linear regression.
Gradient Descent for multiple variables:
The gradient descent equation itself is generally the same form. We just have to repeat it for ‘n’ features:
repeat until convergence
:
{
θ
0
:
=
θ
0
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
0
(
i
)
θ
1
:
=
θ
1
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
1
(
i
)
θ
2
:
=
θ
2
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
2
(
i
)
.
.
.
}
\text{repeat until convergence}:\{\\ \theta_0 := \theta_0 - \frac{\alpha}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})\cdot{x_0^{(i)}}\\ \theta_1 := \theta_1 - \frac{\alpha}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})\cdot{x_1^{(i)}}\\ \theta_2 := \theta_2 - \frac{\alpha}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})\cdot{x_2^{(i)}}\\ ...\\ \}
repeat until convergence:{θ0:=θ0−mαi=1∑m(hθ(x(i))−y(i))⋅x0(i)θ1:=θ1−mαi=1∑m(hθ(x(i))−y(i))⋅x1(i)θ2:=θ2−mαi=1∑m(hθ(x(i))−y(i))⋅x2(i)...}
Or, in a compact form:
θ
j
:
=
θ
j
−
α
m
∑
i
=
1
n
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
⋅
x
j
(
i
)
for j:= 0...n
\theta_j := \theta_j - \frac{\alpha}{m}\sum_{i=1}^{n}(h_\theta(x^{(i)} - y^{(i)}))\cdot{x_j^{(i)}} \text{ for j:= 0...n}
θj:=θj−mαi=1∑n(hθ(x(i)−y(i)))⋅xj(i) for j:= 0...n
Feature Scaling and Mean Normalization:
It’s a trick to make the gradient descent more faster when u have features that range in different order of magnitude. Theta descend quickly on small ranges and slowly on large ranges, and so will oscillate inefficiently down to the optimum when the variables are very uneven.
The way to prevent this is to modify the ranges of our input variables so that they are all roughly the same. Ideally:
−
1
≤
x
j
≤
1
o
r
−
0.5
≤
x
j
≤
0.5
-1\le x_j \le1\\ or\\ -0.5 \le x_j \le 0.5
−1≤xj≤1or−0.5≤xj≤0.5
Two techniques to help with this are feature scaling and mean normalization. Feature scaling involves dividing the input values by the range (i.e. the maximum value minus the minimum value) of the input variable, resulting in a new range of just 1. Mean normalization involves subtracting the average value for an input variable from the values for that input variable resulting in a new average value for the input variable of just zero. To implement both of these techniques, adjust your input values as shown in this formula:
x
j
:
=
x
j
−
μ
s
j
x_j := \frac{x_j - \mu}{s_j}
xj:=sjxj−μ
Practical Tips to Get Gradient Descent Working Correctly:
One way is to plot the cost function J of theta after each iteration. Our goal is to make sure the gradient descent would converge after iteration of algorithm. A pleasant iteration may look like this:
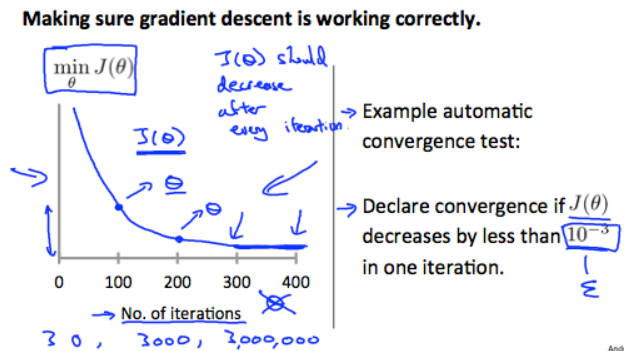
There are some common seen bug casing the plot unsatisfactory when doing iteration:
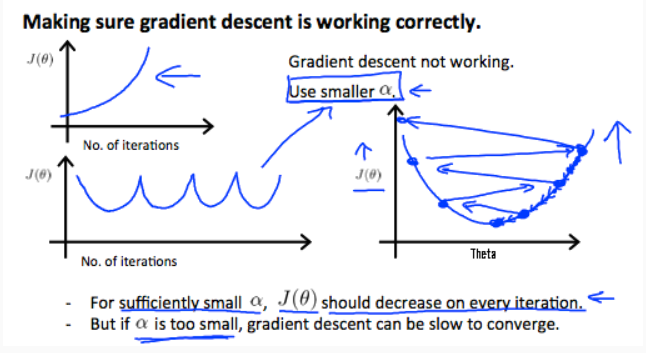
and they always cause by using large alpha, the learning rate. There’s a way for us to roughly get a workable alpha, which is to try out running gradient descent with a range of value of theta. Such as 0.001 and 0.01, and these different values of alpha plot J of theta as a function of number of iterations, and then pick the value of alpha that seems to be causing J to decrease rapidly. We can also increase the learning rate threefold to get 0.003, and so on.
Polynomial Regression:
We can improve our features and the form of the hypothesis function in a couple of different ways:
We can combine multiple features into one. For example, we can combine
x
1
x_1
x1 and
x
2
x_2
x2 into a new feature
x
3
x_3
x3 by taking
x
1
∗
x
2
x_1*x_2
x1∗x2
Our hypothesis function need not to be linear when it doesn’t fit the data well. We can change the behavior of the curve of our hypothesis function by making it quadratic, cubic or square root function(or any other form).
For example, if we have a function like:
h
(
θ
)
=
θ
0
+
θ
1
x
1
h(\theta) = \theta_0 + \theta_1x_1
h(θ)=θ0+θ1x1
Then we can create additional features based on x1 to get quadratic function:
h
(
θ
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
1
2
h(\theta) = \theta_0 + \theta_1x_1 + \theta_2x_1^2
h(θ)=θ0+θ1x1+θ2x12
or the cubic function:
h
(
θ
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
1
2
+
θ
3
x
1
3
h(\theta) = \theta_0 + \theta_1x_1 + \theta_2x_1^2 + \theta_3x_1^3
h(θ)=θ0+θ1x1+θ2x12+θ3x13
and we can create new features
x
2
x_2
x2,
x
3
x_3
x3 where
x
2
=
x
1
2
x_2 = x_1^2
x2=x12,
x
3
=
x
1
3
x_3 = x_1^3
x3=x13.
To make it a square root function, we could do:
h
(
θ
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
1
h(\theta) = \theta_0 + \theta_1x_1 + \theta_2\sqrt{\smash[b]{x_1}}
h(θ)=θ0+θ1x1+θ2x1
One important thing to keep in mind is that if we do this making our features 2 or 3 or more times, then feature scaling becomes very important. Cause if x 1 x_1 x1 has range 1 - 1000, the x 1 x_1 x1 square becomes 1 - 100000.
Normal Equation:
Instead of iterative method like gradient descent, we can solve for the optimal value for theta all at one go.
Without proving, just given the method to calculate the theta.
First we set X is a m by (n+1) matrix a combination of vectors of each training example, and y a m dimensional vector containing each known result. And then we get theta:
θ
=
(
X
T
X
)
−
1
X
T
y
\large{\theta} = (\large{X}^{\large{T}}\large{X})^{-1}\large{X}^{\large{T}}y
θ=(XTX)−1XTy
- Example: m=4
| x 0 x_0 x0 | Size(feet) x 1 x_1 x1 | Number of bedrooms x 2 x_2 x2 | Number of floors x 3 x_3 x3 | Age of home(years) x 4 x_4 x4 | Price 1000 1000 1000y |
|---|---|---|---|---|---|
| 1 | 2104 | 5 | 1 | 45 | 460 |
| 1 | 1416 | 3 | 2 | 40 | 232 |
| 1 | 1534 | 3 | 2 | 30 | 315 |
| 1 | 852 | 2 | 1 | 36 | 178 |
X = [ 1 2104 5 1 45 1 1416 3 2 40 1 1534 3 2 30 1 852 2 1 36 ] y = [ 460 232 315 178 ] θ = ( X T X ) − 1 X T y \large{X} = \begin{bmatrix}1 & 2104 & 5 & 1 & 45\\1 & 1416 & 3 & 2 & 40 \\ 1 & 1534 & 3 & 2 & 30 \\ 1 & 852 & 2 & 1 & 36 \end{bmatrix} \space \space \space \space y = \begin{bmatrix}460 \\ 232 \\ 315 \\ 178 \end{bmatrix}\\ \large{\theta} = (\large{X}^T\large{X})^{-1}\large{X}^Ty X=⎣⎢⎢⎢⎡11112104141615348525332122145403036⎦⎥⎥⎥⎤ y=⎣⎢⎢⎢⎡460232315178⎦⎥⎥⎥⎤θ=(XTX)−1XTy
There is no need to do features scaling when using normal equation. The following is a comparison of gradient descent and normal equation:
| Gradient Descent | Normal Equation |
|---|---|
| need to choose alpha | no need to choose alpha |
| needs many iteration | no need to iterate |
| O ( k n 2 ) O(kn^2) O(kn2) | O ( n 3 ) O(n^3) O(n3), need to calculate inverse of X T X \large{X}^T\large{X} XTX |
| works well with large n | slow if n is large |
In addition, gradient descent still works for some classification problems while normal equation doesn’t.
Classification(binary classification/mutiple classification):
Logistic Regression:
The prediction is between 0 and 1:
0
≤
h
θ
(
x
)
≤
1
0 \le h_\theta(x) \le 1
0≤hθ(x)≤1
which the output of h estimate the probability that y = 1 on input x
So we need a function to generate output only between 0 and 1. Thats when we found Sigmoid function/Logistic function to meet our need:
g
(
z
)
=
1
1
+
e
−
z
g(z)=\frac{1}{1 + e^{-z}}
g(z)=1+e−z1
Sigmoid function can restrain the output beween 0 and 1, which look like this:

So we can take our hypothesis function into z, like:
h
θ
(
x
)
=
g
(
θ
T
x
)
z
=
θ
T
x
h_\theta(x) = g(\theta^{T}x)\\ z = \theta^{T}x
hθ(x)=g(θTx)z=θTx
Descision boundary:
Suppose
- predict “y = 1” if the output is greater than or equal to 0.5
- predict “y = 0” if the output is less than 0.5
In other word, the boundary can be defined by parameterized x x x, whether it is greater or smaller than 0
The decision boundary is a property, not of the trading set, but of the hypothesis under the parameters. So, so long as we’re given my parameter vector theta, that defines the decision boundary. But the training set is not what we use to define the decision boundary. The training set may be used to fit the parameters θ \theta θ.
The hypothesis doesn’t need to be linear, and could be a function that describes a circle like:
(
e
.
g
.
z
=
θ
0
+
θ
1
x
1
2
+
θ
2
x
2
3
)
(e.g.\space z = \theta_0 + \theta_1x_1^2 + \theta_2x_2^3)
(e.g. z=θ0+θ1x12+θ2x23)
or any shape to fit our data.
Logistic regression cost funciton:
Using the same cost function as linear regression may cause multiple local optima, plotting a wavy or we say non-convex figure. So we have to find a better cost function:
J
(
θ
)
=
1
m
∑
i
=
1
m
Cost
(
h
θ
(
x
(
i
)
,
y
(
i
)
)
Cost
(
h
θ
(
x
)
,
y
)
=
−
l
o
g
(
h
θ
(
x
(
i
)
)
)
J(\theta) = \frac{1}{m}\sum_{i=1}^m \text{Cost} (h_\theta(x^{(i)}, y^{(i)})\\ \text{Cost}(h_\theta(x), y) = -log(h_\theta(x^{(i)}))
J(θ)=m1i=1∑mCost(hθ(x(i),y(i))Cost(hθ(x),y)=−log(hθ(x(i)))
Writing the cost function in this way guarantees that J of theta is convex for logistic regression.
When y = 1, we get the following plot for J of theta vs H of theta:
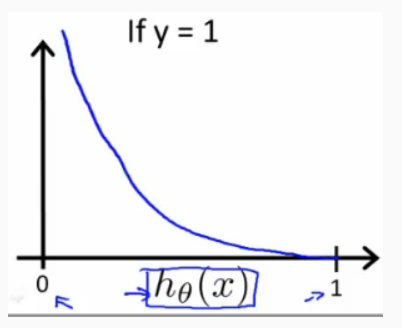
Similarly, when y = 0:
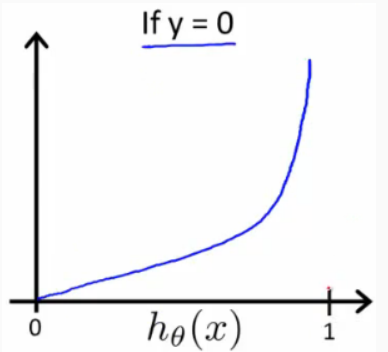
Whether the y is 0 or 1, if our hypothesis reach the other side of y, the cost function would approach infinity:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
0
if
h
θ
(
x
)
=
y
C
o
s
t
(
h
θ
(
x
)
,
y
)
→
∞
if
y
=
0
and
h
θ
(
x
)
→
1
C
o
s
t
(
h
θ
(
x
)
,
y
)
→
∞
if
y
=
1
and
h
θ
(
x
)
→
0
Cost(h_\theta(x), y) = 0 \space\space\text{if}\space\space h_\theta(x) = y\\ Cost(h_\theta(x), y) \to \infin \space\space\text{if}\space\space y = 0 \space\space\text{and}\space\space h_\theta(x) \to 1\\ Cost(h_\theta(x), y) \to \infin \space\space\text{if}\space\space y = 1 \space\space\text{and}\space\space h_\theta(x) \to 0
Cost(hθ(x),y)=0 if hθ(x)=yCost(hθ(x),y)→∞ if y=0 and hθ(x)→1Cost(hθ(x),y)→∞ if y=1 and hθ(x)→0
To make the cost function simpler, we can combine the two condition together adding a coeffecient of treated y:
y
(
i
)
ln
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
ln
(
1
−
h
θ
(
x
(
i
)
)
)
y^{(i)}\ln{h_\theta(x^{(i)})} + (1 - y^{(i)})\ln{(1 - h_\theta(x^{(i)}))}
y(i)lnhθ(x(i))+(1−y(i))ln(1−hθ(x(i)))
So the J of theta would end up looking like this:
J
(
θ
)
=
1
m
∑
i
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
,
y
)
=
−
1
m
[
∑
i
=
1
m
y
(
i
)
ln
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
ln
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta) = \frac{1}{m}\sum_{i = 1}^m Cost(h_\theta(x^{(i)}, y)\\ = -\frac{1}{m}[\sum_{i=1}^m y^{(i)}\ln{h_\theta(x^{(i)}}) + (1 - y^{(i)})\ln(1 - h_\theta(x^{(i)}))]
J(θ)=m1i=1∑mCost(hθ(x(i),y)=−m1[i=1∑my(i)lnhθ(x(i))+(1−y(i))ln(1−hθ(x(i)))]
And the gradient descent algorithm is identical to the one we used in linear regression, while h’s in the two functions are different:
R
e
p
e
a
t
:
{
θ
j
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
}
Repeat:\{\\ \theta_j = \theta_j - \alpha\frac{\partial}{\partial\theta_j}J(\theta)\\ \}
Repeat:{θj=θj−α∂θj∂J(θ)}
After working out the derivative part to get:
R
e
p
e
a
t
:
{
θ
j
=
θ
j
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
}
Repeat:\{\\ \theta_j = \theta_j - \frac{\alpha}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)}\\ \}
Repeat:{θj=θj−mαi=1∑m(hθ(x(i))−y(i))xj(i)}
A vectorized implementation is:
h
=
g
(
X
θ
)
J
(
θ
)
=
1
m
⋅
(
−
y
T
ln
(
h
)
−
(
1
−
y
)
T
ln
(
1
−
h
)
)
h = g(X\theta)\\ J(\theta) = \frac{1}{m}\cdot (-y^T\ln(h) - (1 - y)^T\ln(1 - h))
h=g(Xθ)J(θ)=m1⋅(−yTln(h)−(1−y)Tln(1−h))
Note that feature scaling also work for logistic regression.
Advanced Optimization Algorithm:
There are more safisticated algorithms given by experts to calculate the optimal theta:
- Conjugate gradient
- BFGS
- L-BFGS
The advantage of using these is that they’re much more faster than just simply applying gradient descent, mostly because that they could choose a more suitable learning rate during iteration, some of them can even choose better alpha for each iteration.
The disadvange is that they’re more complicate. It’s not easy for us to really figure out what they’re doing in the inner loop, unless we have expertise upon the area.
To apply these in octave, we first have to write a costFunction() ourselves returning a J of theta, and a vector containing each gradient of thetaes:
function [jVal, gradient] = costFunction(theta)
jVal = [code to compute J(theta)];
gradient(1) = [code to compute J(theta) partial to theta1]
...
gradient(n) = [code to compute J(theta) partial to thetan]
Then call two built-in functions to make the advanced optimized algorithm works:
Multiclass Classification:
The main idea of multiclass classification is seperating each set of data from other. Similar with binary classification, we’ll have cost funtion. What’s different is that we’ll calculate each cost function for each sort of data. In practice, we basically choose one class and then lump all the others into a single second class. Then do this repeatedly, apply binary logistic regression to each case, and use the hypothesis that returned the highest value as our prediction:
y
∈
{
0
,
1
,
2
,
.
.
.
,
n
}
h
θ
(
0
)
(
x
)
=
P
(
y
=
0
∣
x
;
θ
)
h
θ
(
1
)
(
x
)
=
P
(
y
=
1
∣
x
;
θ
)
.
.
.
h
θ
(
n
)
(
x
)
=
P
(
y
=
n
∣
x
;
θ
)
prediction
=
max
(
h
θ
(
i
)
(
x
)
)
y \in \{0, 1, 2, ..., n\}\\ h_\theta ^{(0)}(x) = P(y = 0\mid x; \theta)\\ h_\theta ^{(1)}(x) = P(y = 1\mid x; \theta)\\ ...\\ h_\theta ^{(n)}(x) = P(y = n\mid x; \theta)\\ \text{prediction} = \max(h_\theta ^{(i)}(x))
y∈{0,1,2,...,n}hθ(0)(x)=P(y=0∣x;θ)hθ(1)(x)=P(y=1∣x;θ)...hθ(n)(x)=P(y=n∣x;θ)prediction=max(hθ(i)(x))
To summarize, after we train out each classifier, we take the x to predict into every cost function and pick the class that maximizes h.
Underfitting and Overfitting:
When fitting the data, we may encounter these kinds of problem:
- underfitting: when the power of our hypothesis function is too small. For instance, we fit a quadratic model of data with a straight line, the data won’t fit the line well:
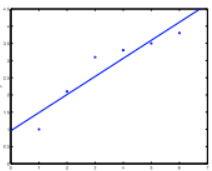
- overfitting: when the power we set to our hypothesis function is too large, or when we add too many features, we may get a line fit almost every given data perfectly. But it doesn’t mean the prediction works well.
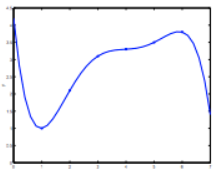
To deal with overfitting, we have two options:
- Reduce the number of features:
- Manually select which features to keep
- Use a model selection algorithm
- Regularization:
- Keep all the features, but reduce the magnitude of parameter theta j
Regularization works well when we have a lot of slightly useful features
Regularization:
Penalize some of the thetaes to make them smaller would cause:
- simpler hypothesis
- less prone to overfitting
If we have overfitting problem, we can reduce the weight that some of the terms if our function carry by increasing their cost.
Say if we wanted to make the following function more quadratic:
θ
0
+
θ
1
x
+
θ
2
x
2
+
θ
3
x
3
+
θ
4
x
4
\theta_0 + \theta_1x + \theta_2x^2 + \theta_3x^3 + \theta_4x^4
θ0+θ1x+θ2x2+θ3x3+θ4x4
We’ll want to eliminate the influence of
θ
3
x
3
\theta_3x^3
θ3x3 and
θ
4
x
4
\theta_4x^4
θ4x4 . Without actually getting rid of these features or changing the form of our hypothesis, we can instead modify our cost function:
min
θ
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
1000
⋅
θ
3
2
+
1000
⋅
θ
4
2
\min_\theta \frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2 + 1000\cdot\theta_3^2 + 1000\cdot\theta_4^2
θminm1i=1∑m(hθ(x(i))−y(i))2+1000⋅θ32+1000⋅θ42
We’ve added two extra terms at the end to inflate the cost of
θ
3
\theta_3
θ3 and
θ
4
\theta_4
θ4. Now, in order for the cost function to get close to zero, we will have to reduce the values of
θ
3
\theta_3
θ3 and
θ
4
\theta_4
θ4 to near zero. This will in turn greatly reduce the values of
θ
3
\theta_3
θ3 and
θ
4
\theta_4
θ4 in our hypothesis function. As a result, we see that the new hypothesis (depicted by the pink curve) looks like a quadratic function but fits the data better due to the extra small terms
θ
3
x
3
\theta_3x^3
θ3x3 and
θ
4
x
4
\theta_4x^4
θ4x4.
To generallize, we make our cost function like this:
min
θ
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
\min_\theta \frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda\sum_{j=1}^n \theta_j^2
θminm1i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2
while the λ \lambda λ is the regularization parameter.
Gradient descent:
when doing gradient descent, the thetaes will have to subtract the extra part:
Repeat:
{
θ
0
:
=
θ
0
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
i
)
θ
j
:
=
θ
j
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
α
λ
m
θ
j
)
}
θ
j
:
=
(
1
−
α
m
)
θ
j
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
,
j
=
(
1
,
2
,
3
,
4
,
.
.
.
,
n
)
without 0
\text{Repeat:}\{\\ \theta_0 := \theta_0 - \frac{\alpha}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)}\\ \theta_j := \theta_j - \frac{\alpha}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\alpha\lambda}{m}\theta_j)\\ \}\\ \large{\theta_j} := (1 - \frac{\alpha}{m})\theta_j - \frac{\alpha}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)}, \space\space j = (1, 2, 3, 4, ..., n)\space\text{without 0}
Repeat:{θ0:=θ0−mαi=1∑m(hθ(x(i))−y(i))x0(i)θj:=θj−mαi=1∑m(hθ(x(i))−y(i))xj(i)+mαλθj)}θj:=(1−mα)θj−mαi=1∑m(hθ(x(i))−y(i))xj(i), j=(1,2,3,4,...,n) without 0
which is exactly the same as what gradient descent was doing before, just a little bit of difference of appearance.
Notice the
(
1
−
α
m
)
(1 - \frac{\alpha}{m})
(1−mα) is going to be a little bit smaller than 1
Normal equation:
θ = ( X T X + λ ⋅ L ) − 1 X T y w h e r e L = [ 0 1 1 . . 1 ] \theta = (\large{X}^T\large{X} + \lambda\cdot L)^{-1}X^Ty\\ where \space\space L = \begin{bmatrix}0&&&&&\\&1&&&&\\&&1&&&\\&&&.&&\\&&&&.&\\&&&&&1\end{bmatrix} θ=(XTX+λ⋅L)−1XTywhere L=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡011..1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
Regularized logistic regression:
Recall the cost function of the logistic regression was:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
ln
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
ln
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta) = -\frac{1}{m}\sum_{i=1}^m\lbrack y^{(i)}\ln(h_\theta(x^{(i)})) + (1 - y^{(i)})\ln(1 - h_\theta(x^{(i)}))\rbrack
J(θ)=−m1i=1∑m[y(i)ln(hθ(x(i)))+(1−y(i))ln(1−hθ(x(i)))]
We can regularize this equation by adding a term to the end:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
ln
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
ln
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta) = -\frac{1}{m}\sum_{i=1}^m\lbrack y^{(i)}\ln(h_\theta(x^{(i)})) + (1 - y^{(i)})\ln(1 - h_\theta(x^{(i)}))\rbrack + \frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2
J(θ)=−m1i=1∑m[y(i)ln(hθ(x(i)))+(1−y(i))ln(1−hθ(x(i)))]+2mλj=1∑nθj2
The second sum exclude
θ
0
\theta_0
θ0. But when we compute it as a vector, we should take
θ
0
\theta_0
θ0 into account. We should continuously update the two following equations:
Repeat:
{
θ
0
:
=
θ
0
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
i
)
θ
j
:
=
θ
j
−
α
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
α
λ
m
θ
j
}
\text{Repeat:}\{\\ \theta_0 := \theta_0 - \frac{\alpha}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)}\\ \theta_j := \theta_j - \frac{\alpha}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\alpha\lambda}{m}\theta_j\\ \}
Repeat:{θ0:=θ0−mαi=1∑m(hθ(x(i))−y(i))x0(i)θj:=θj−mαi=1∑m(hθ(x(i))−y(i))xj(i)+mαλθj}

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









