






一、概念
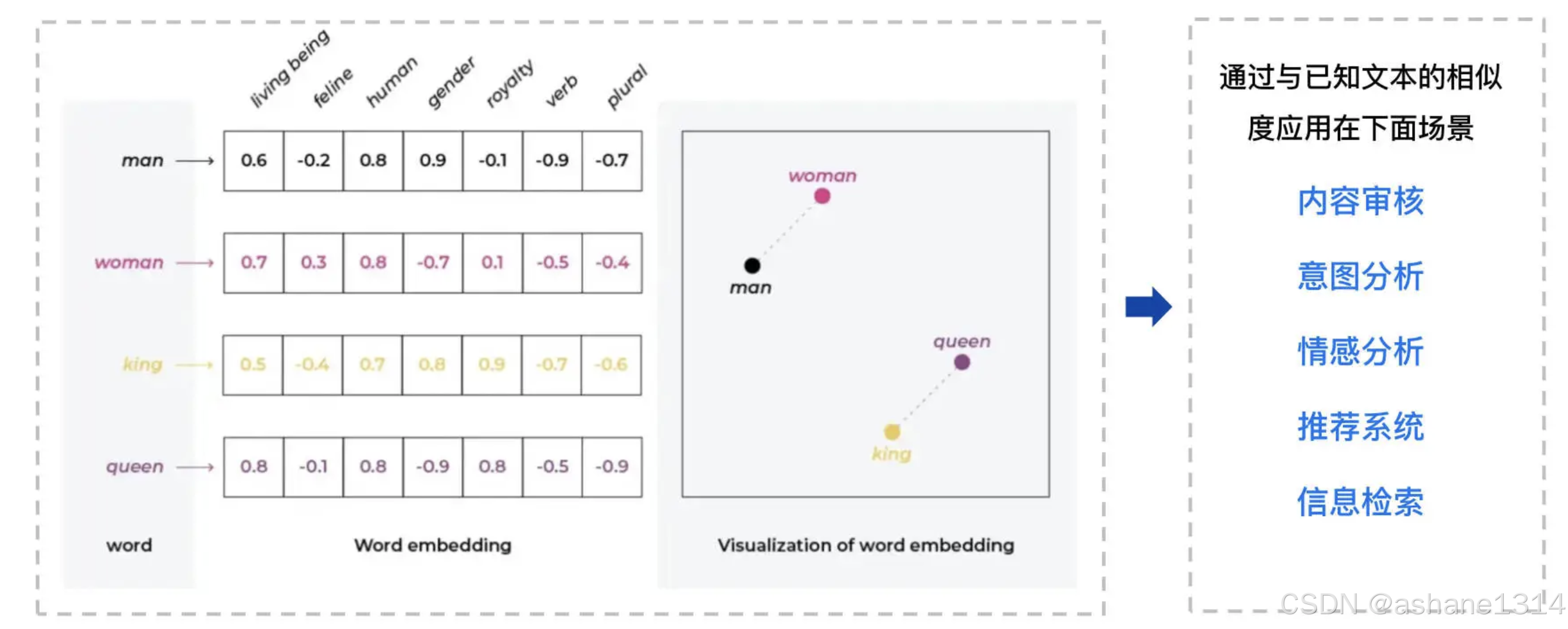
Embedding 嵌入是指将文本、图像、音频、视频等形式的信息映射为高维空间中的密集向量表示。这些向量在语义空间中起到坐标的作用,捕捉对象之间的语义关系和隐含的意义。通过在向量空间中进行计算(例如余弦相似度),可以量化和衡量这些对象之间的语义相似性。在具体实现中,嵌入的每个维度通常对应文本的某种特征,例如性别、类别、数量等。通过多维度的数值表示,计算机能够理解并解析文本的复杂语义结构。例如,“man”和“woman”在描述性别维度上具有相似性,而“king”和“queen”则在性别和王室身份等维度上表现出相似的语义特征。向量是一组在高维空间中定义点的数值数组,而嵌入则是将信息(如文本)转化为这种向量表示的过程。这些向量能够捕捉数据的语义及其他重要特征,使得语义相近的对象在向量空间中彼此邻近,而语义相异的对象则相距较远。向量检索(Vector Retrieval)是一种基于向量表示的搜索技术,通过计算查询向量与已知文本向量的相似度来识别最相关的文本数据。向量检索的高效性在于,它能在大规模数据集中快速、准确地找到与查询最相关的内容,这得益于向量表示中蕴含的丰富语义信息。
二、嵌入模型
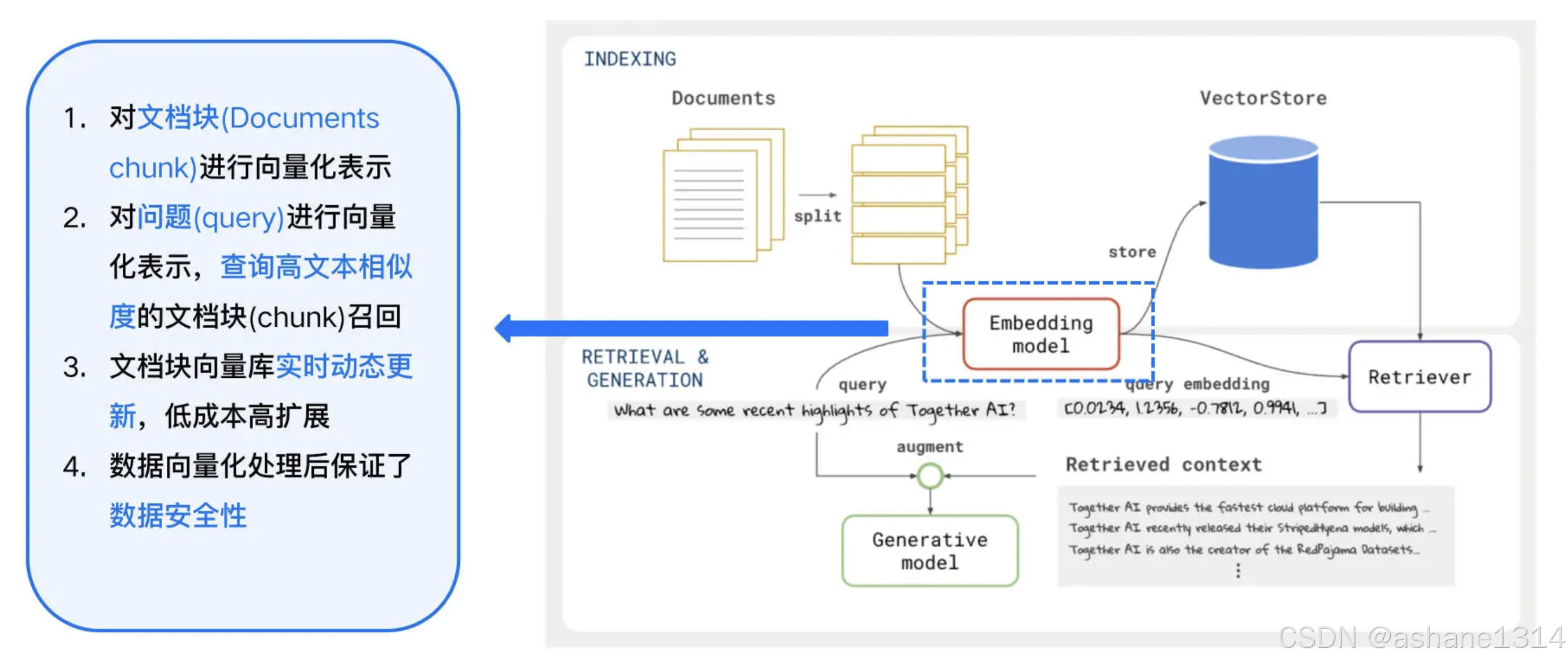
Embedding Model 将输入的文档片段(Chunks)和查询文本(Query)转换为嵌入向量(Vectors),这些向量捕捉了文本的语义信息,并可在向量空间中与其他嵌入向量进行比较。
三、Embedding Model 嵌入模型评估
在选择适合的嵌入模型时,需要综合考虑多个因素,包括特定领域的适用性、检索精度、支持的语言、文本块长度、模型大小以及检索效率等因素。同时以广泛受到认可的 MTEB(Massive Text Embedding Benchmark)和 C-MTEB(Chinese Massive Text Embedding Benchmark)榜单作为参考,通过涵盖分类、聚类、语义文本相似性、重排序和检索等多个数据集的评测,开发者可以根据不同任务的需求,评估并选择最优的向量模型,以确保在特定应用场景中的最佳性能。


















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









