






使用 NumPy 和 SciPy 实现通用注意力机制
1.定义词向量
import numpy as np
from scipy.special import softmax
# 首先,我们定义四个单词的词向量,每个向量维度为3。
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])
words = np.array([word_1, word_2, word_3, word_4])这些词向量可以表示为矩阵 ,其中每一行代表一个单词的嵌入。
word_1, word_2, word_3, word_4:每个都是维度为3的词向量,代表一个单词在嵌入空间中的表示。
words:将这些词向量堆叠成一个矩阵,其中每行代表一个单词的嵌入。
2.生成权重矩阵
接下来,我们生成三个权重矩阵
# 生成权重矩阵
np.random.seed(42) # 设置随机数种子,确保每次运行代码时生成的权重矩阵相同。
W_Q = np.random.randint(3, size=(3, 3))
W_K = np.random.randint(3, size=(3, 3))
W_V = np.random.randint(3, size=(3, 3))这些权重矩阵用于将词向量转换为查询(Query)、键(Key)和值(Value)。
3.计算查询、键和值
我们通过矩阵乘法计算查询、键和值
# generating the queries, keys and values
Q = words @ W_Q
K = words @ W_K
V = words @ W_V4.计算得分
得分矩阵通过查询和键的转置相乘得到。
# scoring the query vectors against all key vectors
scores = Q @ K.T5.计算权重
使用softmax函数将得分转换为概率分布。
# computing the weights by a softmax operation
weights = softmax(scores / np.sqrt(K.shape[1]), axis=1)数学上,softmax函数定义为:
在这里,我们首先对得分进行缩放,以保持数值稳定性:,这里的
是键向量的维度,用于缩放注意力得分。
然后应用softmax函数:
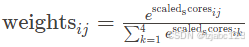
6.计算注意力输出
最后,通过加权和的方式计算注意力输出。
# computing the attention by a weighted sum of the value vectors
attention = weights @ V
print(attention)[[0.98522025 1.74174051 0.75652026]
[0.90965265 1.40965265 0.5 ]
[0.99851226 1.75849334 0.75998108]
[0.99560386 1.90407309 0.90846923]]
数学上,这可以表示为:
其中,每个元素 是所有值向量的加权和:
总结,这个过程涉及的主要步骤是:
将输入词向量与权重矩阵相乘,得到查询、键和值。
计算查询与键的点积,得到得分。
使用softmax函数将得分转换为概率分布,得到注意力权重。
将注意力权重与值矩阵相乘,得到最终的注意力输出。
通过这种方式,注意力机制允许模型动态地聚焦于输入序列中最相关的部分,从而生成更准确的输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









