





火山引擎:邀请可拿145元代金券,畅享671B DeepSeek R1!
火山引擎:邀请可拿3000万tokens,畅享671B DeepSeek R1!
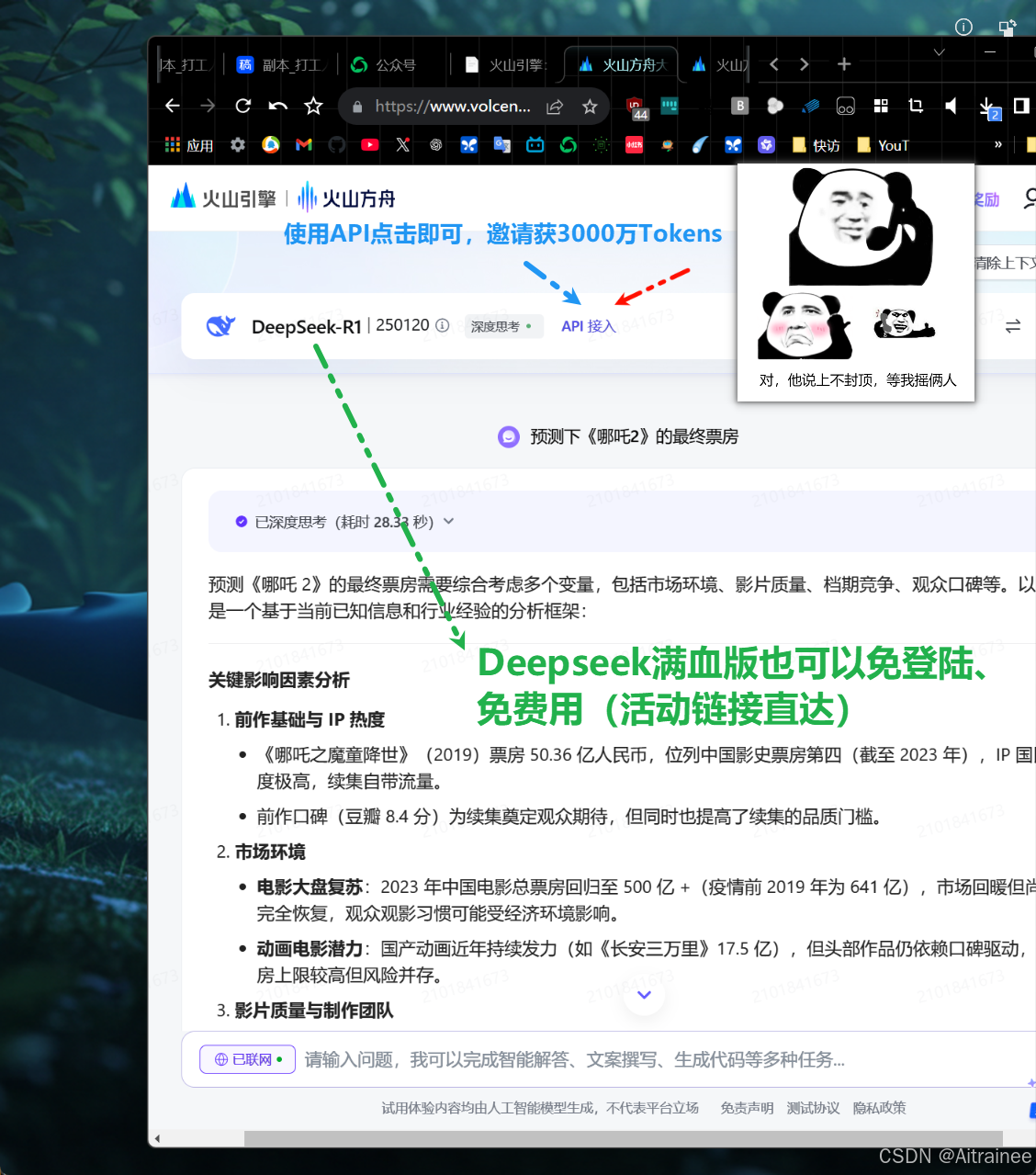
✨从火山方舟接入DeepSeek API服务, 享受大流量+低延迟+低成本服务:延迟低至20ms内,提供高达 500 万 TPM 的全网最高的初始限流,并且全网首家提供超过 50 亿初始离线tokens!
✨现火山方舟大模型体验中心全新上线,免登录即可体验满血+联网版Deep Seek R1 模型及豆包最新版模型
✨邀约活动同步进行中,邀请可拿3000万tokens,畅享671B DeepSeek R1!上不封顶!
每邀请一位好友注册,双方至高可得145元代金券,可抵扣超过3000万 DeepSeek R1 输入tokens!多邀多得,上不封顶!畅享R1和豆包大模型多模态能力!
✔填写推广码注册,获赠15元代金券,约可抵扣375万R1模型输入tokens
✔转发邀请新用户,获赠30元代金券,约可抵扣750万R1模型输入tokens
✔邀请新用户付费,获赠100元代金券,约可抵扣2500万R1模型输入tokens
活动链接:
https://www.volcengine.com/experience/ark?utm_term=202502dsinvite&ac=DSASUQY5&rc=LWL42U2S



















 8889
8889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











