







作为一名Java老兵,不得不说,String可能是我们每天接触最多,却又最容易被误解的类型。它看起来非常简单,但背后的存储机制却非常复杂。
一、String,你真的了解它吗?
1.1 最基本的概念
Java中的String是什么?官方说法是:String类代表字符串。所有字符串字面值都是String类的实例。
String name = "Claude"; // 字面量方式
String tool = new String("Assistant"); // 构造函数方式
看起来简单,对吧?但这两种创建方式在JVM中的存储方式大相径庭。在深入了解之前,我们先记住一个关键特性:
Java中的String对象是不可变的。一旦创建,内容就不能被修改。
这听起来像是一个限制,但这个看似简单的特性,却是String类设计的基石,影响了它在JVM中的整个存储方式。
1.2 为什么String要设计成不可变?
我曾被这个问题困扰很久,直到了解了以下原因:
- 安全性:String经常用于存储敏感信息(如密码)。不可变意味着没人能修改你的字符串值。
- 线程安全:不可变对象天生是线程安全的,无需额外同步。
- hashCode缓存:String常被用作HashMap的键,不可变性允许缓存其hashCode,提高性能。
- 字符串池优化:只有因为String不可变,JVM才能实现字符串常量池来节省内存。
这最后一点尤为重要,它直接关系到了String在JVM中的存储方式。
二、字符串常量池:String存储的第一个秘密
2.1 什么是字符串常量池?
字符串常量池(String Pool)是JVM内存中的一个特殊区域,用于存储字符串字面量。
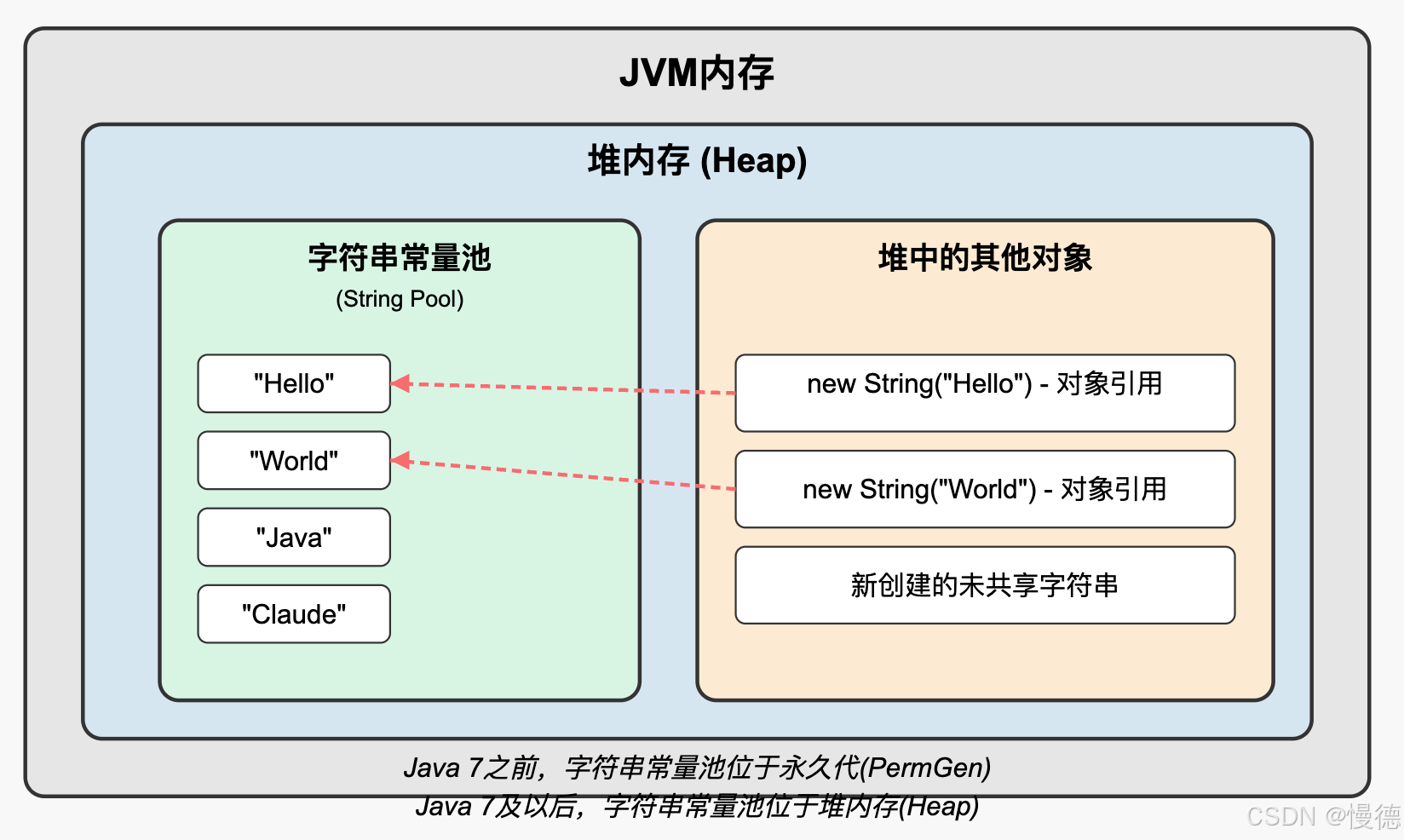
为什么需要这个池?想象一下:如果你在程序中多次使用相同的字符串字面量,如果每次都创建新对象,那将是多么浪费内存!
2.2 字符串常量池的工作原理
字符串常量池的工作原理遵循"享元模式"(Flyweight Pattern):
- 当使用字面量创建字符串时,JVM首先检查字符串常量池中是否存在相同内容的字符串
- 如果存在,返回池中的引用
- 如果不存在,创建新的字符串对象,放入池中,再返回引用
这就是为什么以下代码中的比较结果是true:
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // 输出:true
s1和s2实际上引用的是常量池中的同一个对象!这不仅节省了内存,还能提高字符串比较的性能。
2.3 字符串常量池的位置变迁
字符串常量池在JVM内存中的位置其实经历了变迁:
- Java 7之前:存在于永久代(PermGen)
- Java 7及以后:移到了堆内存(Heap)
- Java 8及以后:随着永久代被移除,字符串常量池只能存在于堆中
这一变迁主要是为了解决永久代大小固定导致的字符串常量池内存溢出问题。移到堆内存后,字符串常量池可以受益于GC机制,动态调整大小。
三、深入理解String对象的内部结构
3.1 String的内部表示方式
String类内部如何存储字符序列?这在Java的不同版本中有所变化:
Java 9之前:
public final class String {
private final char[] value; // 字符数组
private int hash; // 缓存的hash值
// 其他字段和方法...
}
Java 9及以后:
public final class String {
private final byte[] value; // 字节数组
private final byte coder; // 编码方式
private int hash; // 缓存的hash值
// 其他字段和方法...
}
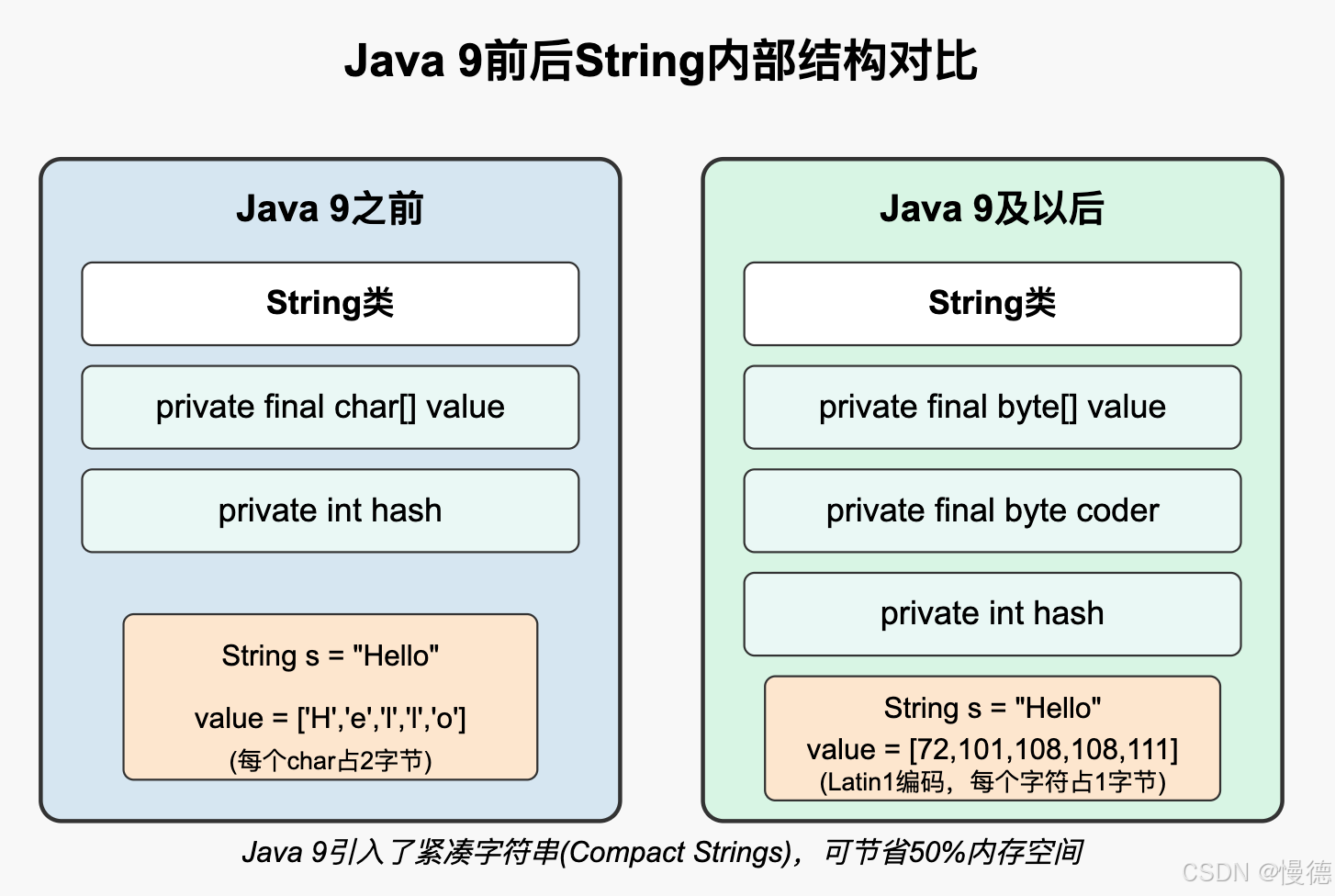
看到了吗?这个变化太有意思了!Java 9引入了一个叫做"紧凑字符串"(Compact Strings)的新特性,将内部表示从char[]改为了byte[]。
3.2 为什么要从char[]改为byte[]?
这个变化看似小,实际上是一个重大的内存优化。原因在于:
- 在Java中,char是16位(2字节)的Unicode字符,即使存储ASCII字符也会占用2字节
- 实际上,大多数字符串只包含Latin-1字符,这些字符可以用一个字节表示
- 通过使用byte[]和一个标识编码的coder字段,Java 9可以:
- 对于Latin-1字符:每个字符只使用1字节存储(LATIN1编码,coder=0)
- 对于其他Unicode字符:每个字符使用2字节存储(UTF-16编码,coder=1)
这个改变可以为大多数字符串节省约50%的内存!作为大规模Java应用的架构师,我必须说,这是一个令人惊叹的优化。
3.3 String对象的内存布局
我们再深入一步,看看一个String对象在内存中的实际布局:
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
public class StringMemoryLayout {
public static void main(String[] args) {
// 查看JVM信息
System.out.println(VM.current().details());
// 创建字符串
String s = "Hello, JVM!";
// 打印String对象的内存布局
System.out.println(ClassLayout.parseInstance(s).toPrintable());
}
}
/* 输出示例 (Java 11, 64位系统):
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 int String.hash 0
16 1 byte String.coder 0
17 3 (alignment/padding gap)
20 4 byte[] String.value [72, 101, 108, 108, 111, 44, 32, 74, 86, 77, 33]
24 0 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 3 bytes internal + 0 bytes external = 3 bytes total
*/
通过JOL工具(Java Object Layout),我们可以看到一个String对象包含:
- 对象头:包含类型信息、GC信息、锁信息等(12字节)
- 实例字段:
- hash值(4字节)
- coder编码标识(1字节)
- 内部对齐填充(3字节)
- value数组的引用(4字节,这是指向实际字节数组的指针)
总共24字节,不包括存储实际字符的byte数组的大小。
四、new String(“abc”) vs “abc”:看似相同,实则不同
4.1 创建方式的差异
这可能是新手最容易混淆的部分。请看:
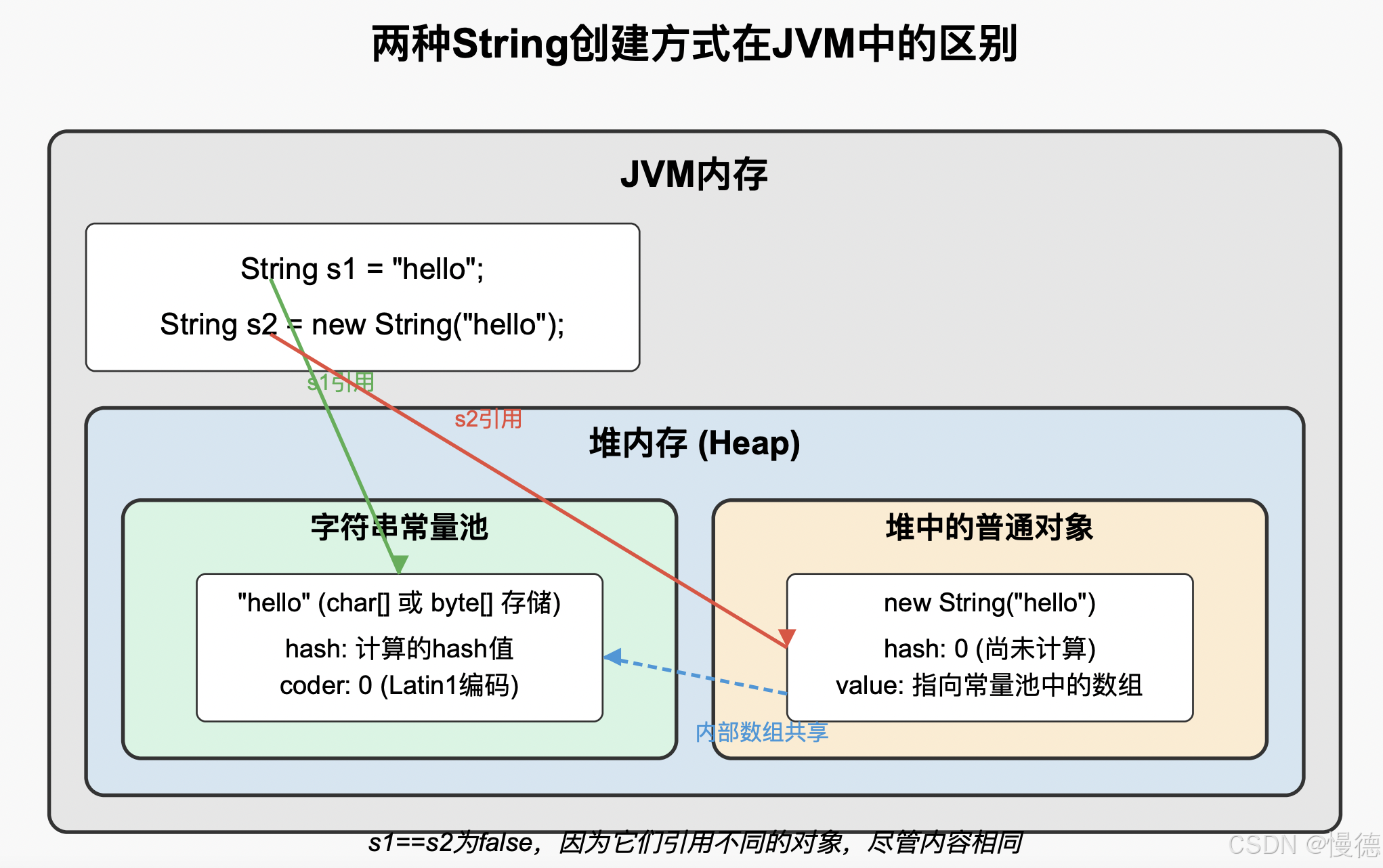
String s1 = "hello";
String s2 = new String("hello");
System.out.println(s1 == s2); // 输出:false
为什么会输出false?因为这两种创建方式在JVM中的处理方式完全不同:
-
使用字面量创建(
"hello"):- 查找字符串常量池,如果存在"hello"则返回其引用
- 如果不存在,在常量池中创建"hello",并返回其引用
-
使用new关键字创建(
new String("hello")):- 首先,检查字符串常量池中是否存在"hello"
- 如果不存在,在常量池中创建"hello"
- 然后,在堆内存中创建一个新的String对象
- 新对象的内部字符数组指向常量池中的"hello"的字符数组(共享内部存储)
- 返回堆中对象的引用
4.2 要创建几个对象?
现在来一道经典面试题:
String s = new String("hello");
这行代码会创建几个对象?
答案是:1个或2个
- 如果字符串常量池中已经存在"hello",则只会在堆中创建一个新的String对象
- 如果字符串常量池中不存在"hello",则会先在常量池创建"hello",再在堆中创建一个新的String对象
我第一次遇到这个问题时,感觉自己就像在看一道数学题:“如果小明有5个苹果…”。但现在理解了内部机制,这个问题就变得清晰了。
4.3 intern()方法:手动入池
String类提供了一个叫intern()的方法,它可以:
- 检查字符串常量池中是否存在与当前字符串内容相同的字符串
- 如果存在,返回常量池中的字符串引用
- 如果不存在,将当前字符串添加到常量池,并返回其引用
换句话说,intern()方法可以将堆中的字符串手动"入池":
String s1 = new String("hello");
String s2 = s1.intern();
String s3 = "hello";
System.out.println(s1 == s2); // false,s1是堆中对象,s2是常量池中对象
System.out.println(s2 == s3); // true,都是常量池中的同一个对象
这个方法在特定场景下(如大量重复字符串处理)可以用来优化内存使用。
五、深入剖析:String对象的内存优化
5.1 字符串拼接的内存问题
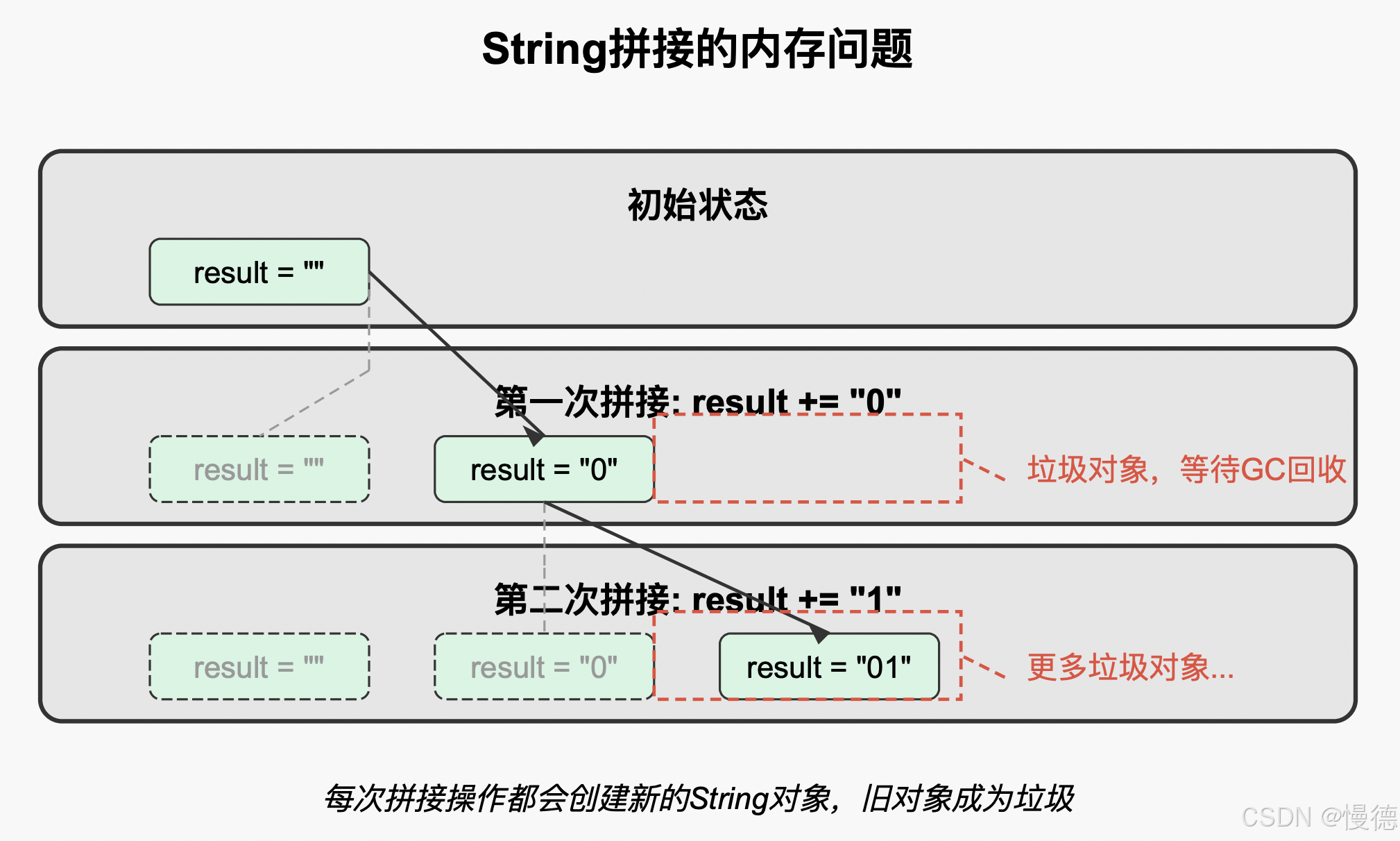
String result = "";
for (int i = 0; i < 10000; i++) {
result += i; // 每次循环都会创建新的String对象!
}
上面的代码看起来无害,但实际上是内存效率的噩梦!由于String的不可变性,每次使用+=操作符,都会创建一个新的String对象。这意味着循环会创建10000个中间String对象,这些对象随后就变成了垃圾,等待被回收。
5.2 解决方案:StringBuilder
为了解决这个问题,Java提供了StringBuilder类(以及线程安全的StringBuffer):
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10000; i++) {
sb.append(i); // 不会创建中间对象
}
String result = sb.toString(); // 只在最后创建一个String对象
StringBuilder内部使用可变的字符数组,可以在不创建新对象的情况下进行字符串拼接。只有在调用toString()方法时,才会创建一个新的String对象。
5.3 编译器的优化:隐式StringBuilder
有趣的是,Java编译器会自动优化某些字符串拼接操作。例如:
String result = "Hello" + " " + "World" + "!";
会被编译器优化为:
String result = new StringBuilder().append("Hello").append(" ").append("World").append("!").toString();
但要注意的是,这种优化不会应用于循环中的字符串拼接。所以在循环中,仍然需要显式使用StringBuilder。
六、String的字符编码:UTF-16的故事
6.1 为什么String内部使用UTF-16编码?
Java诞生于1995年,那时Unicode字符集还很小,使用16位字符(即char类型)来表示所有字符是合理的。但随着Unicode的扩展,16位已经不够用了。
Java决定在内部使用UTF-16编码来表示字符串。在UTF-16中:
- 基本多语言平面(BMP)中的字符用一个16位单元表示
- 补充平面中的字符(如表情符号🙂)用两个16位单元表示(称为代理对)
这导致了一些有趣的情况:
String emoji = "🙂";
System.out.println(emoji.length()); // 输出2,而不是1
System.out.println(emoji.codePointCount(0, emoji.length())); // 输出1,实际字符数
6.2 Java 9后紧凑字符串的编码选择
如前所述,Java 9引入了紧凑字符串优化,使用byte[]而不是char[]来存储字符。具体的编码选择逻辑是:
- 检查字符串中的每个字符
- 如果所有字符都可以用Latin-1编码(即一个字节表示),则使用LATIN1编码(coder=0)
- 如果有任何字符需要超过一个字节,则使用UTF-16编码(coder=1)
这个选择是自动的,对开发者透明,但了解它可以帮助我们理解内存使用情况。
七、String的池化策略:更多优化细节
7.1 字符串常量池的大小限制
字符串常量池的大小是有限制的,可以通过JVM参数-XX:StringTableSize来设置。这个参数指定字符串常量池中的桶(bucket)数量。
在早期的Java版本中,默认值较小(如1009),这在处理大量字符串时可能导致性能问题。在现代JVM中,默认值已经增加:
- Java 7u40之前:1009
- Java 7u40到Java 8:60013
- Java 8u20及以后:默认值为65536
如果应用程序使用大量唯一的字符串,增加这个值可能会提高性能。
7.2 不是所有字符串都会自动入池
只有字符串字面量会自动入池,而使用new String()或其他方式创建的字符串不会自动入池。例如:
String s1 = "hello"; // 自动入池
String s2 = new String("hello"); // 不会自动入池
String s3 = s1 + s2; // 不会自动入池
String s4 = s3.intern(); // 手动入池
此外,有些字符串操作也会导致字符串入池,如常量折叠(constant folding):
String s1 = "hel" + "lo"; // 编译时常量折叠,等同于 "hello",会入池
final String prefix = "hel";
String s2 = prefix + "lo"; // 也会被折叠,因为prefix是final
7.3 实际应用中的优化策略
基于对String在JVM中存储原理的理解,我们可以采取一些优化策略:
- 适当使用intern()方法:对于大量重复的长字符串,可以考虑使用intern()方法节省内存
- 避免不必要的String对象创建:如字符串拼接使用StringBuilder
- 注意字符编码:使用Latin-1可表示的字符可以节省内存
- 调整StringTableSize:对于处理大量唯一字符串的应用程序,可以考虑增加字符串常量池大小
但请记住,过早优化是万恶之源!在没有性能问题之前,不要过度关注这些细节。
八、面试中的String存储相关问题
8.1 经典面试题及答案
作为一名面试官,我经常会问以下关于String的问题:
-
Q:
String s = new String("hello");创建了几个对象?
A: 取决于常量池中是否已有"hello"。如果没有,则创建2个对象(一个在常量池,一个在堆);如果已有,则创建1个对象(仅在堆中)。 -
Q: 为什么String被设计为不可变?
A: 安全性(适合存储敏感信息)、线程安全、hashCode缓存、字符串常量池优化等原因。 -
Q: Java 9对String存储有哪些优化?
A: 引入了紧凑字符串,将内部表示从char[]改为byte[],增加coder字段表示编码方式,对于Latin-1字符可节省50%内存。 -
Q: 字符串拼接使用"+"和StringBuilder有什么区别?
A: 在循环中使用"+"会创建大量临时对象,而StringBuilder使用可变的字符数组,只在最后创建一个String对象,性能更好。 -
Q: 字符串常量池的位置在JVM中有什么变化?
A: Java 7之前在永久代,Java 7及以后在堆内存,这是为了解决永久代大小固定导致的字符串常量池溢出问题。
8.2 如何在面试中答得更出彩
要在面试中脱颖而出,不仅要知道答案,还要展示深度:
- 解释原理时举例说明:如展示字符串常量池的工作原理
- 提及性能影响:如讨论不同String操作对GC的影响
- 提及实际经验:如分享曾经通过调整StringTableSize解决过的性能问题
- 展示对JVM演进的了解:如讨论Java各版本对String实现的改进
九、总结
String在Java中如此基础,却包含了如此丰富的设计细节和优化考量。从不可变性、字符串常量池、到内部表示的演进,每一个决策都体现了Java设计者对性能和内存使用的深思熟虑。
作为Java开发者,理解这些细节不仅能帮助我们写出更高效的代码,还能帮助我们理解JVM的内存模型和优化思路。
下次当你写下一个简单的String s = "hello"时,希望你能想起这个看似简单的语句背后,JVM为你做了多少工作!
回顾这些年的Java开发经历,不得不感叹,即使是像String这样每天都在使用的基础类型,也值得我们花时间深入研究,正如那句老话所说:“细节决定成败”。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











