



 本文详细讲述了书生·浦语大模型的最新进展,包括其从单一任务模型向通用大模型的转变,7月到1月的三次关键升级,以及英特尔M2对性能的优化。模型在对话交互、长上下文理解等方面的能力提升,同时强调了开源工具体系和部署解决方案的重要性。
本文详细讲述了书生·浦语大模型的最新进展,包括其从单一任务模型向通用大模型的转变,7月到1月的三次关键升级,以及英特尔M2对性能的优化。模型在对话交互、长上下文理解等方面的能力提升,同时强调了开源工具体系和部署解决方案的重要性。
本次视频介绍了书生·浦语大模型的全链路开源体系,重点在于通用人工智能的发展趋势,特别是从特定任务模型向通用大模型的转变,以及书生模型在7月、9月和1月的升级,包括支持多模态、8K语境和不同尺寸的模型,以及在语言建模能力、对话交互和智能体框架方面的提升。
## 要点
- 通用人工智能的发展方向:从单一任务模型转向通用大模型,解决多种任务和模态。
- 书生·浦语模型升级:7月升级支持8K语境和工具体系,8月发布对话模型和智能体框架,9月发布中等尺寸模型与优化工具链。
- 英特尔M2开源:提升模型性能,支持复杂场景,提供不同尺寸的模型以适应不同需求。
- 模型能力亮点:长上下文理解、对话与创作、数学能力等,例如通过模型进行行程规划和情感对话。
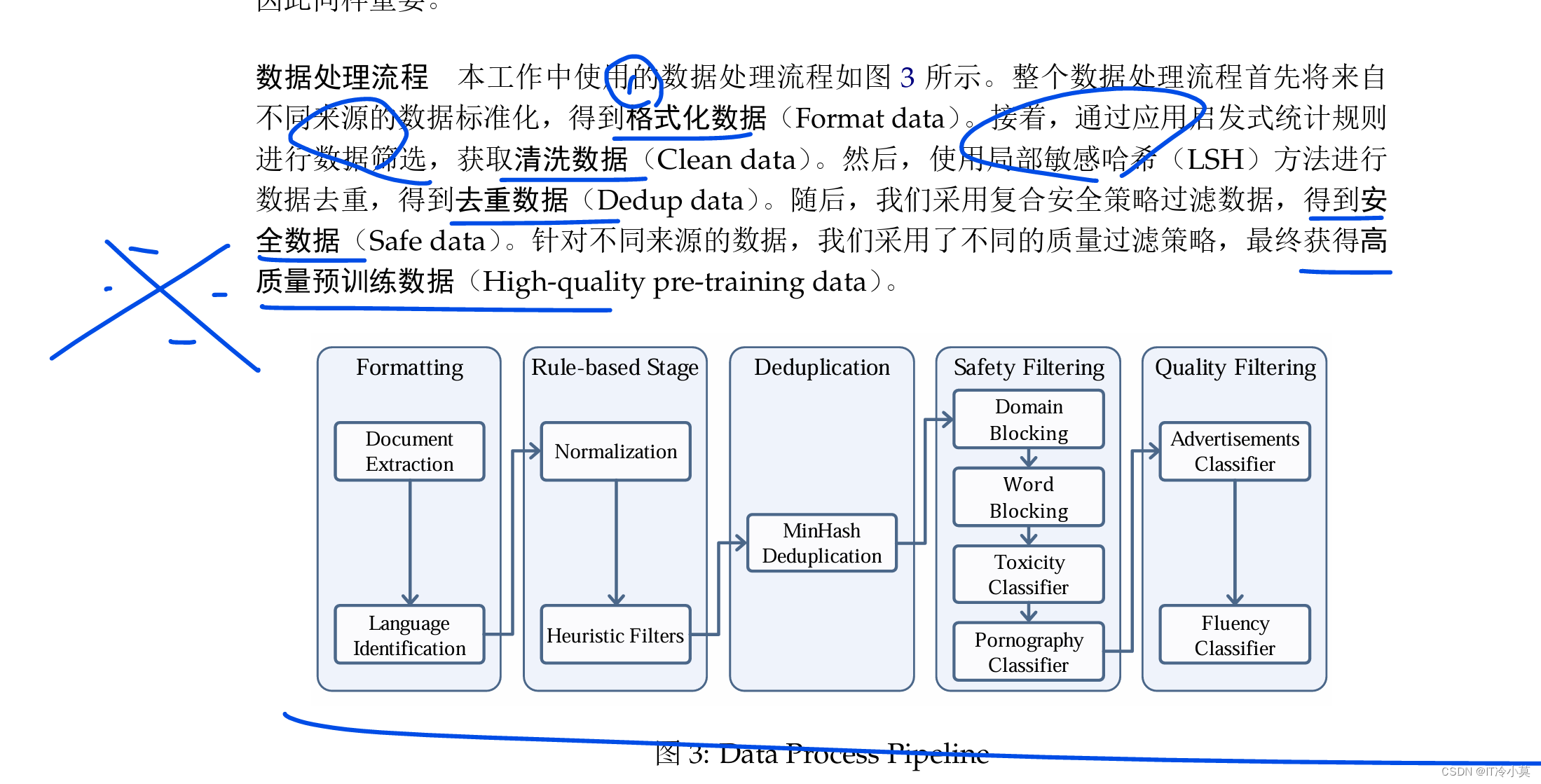
- 英特尔M2的优化:数据清洗、高质量语料和新数据补全提升模型性能。
- 下游任务性能提升:模型使用更少数据也能达到上一代效果,整体性能增强。
- 开源工具体系:覆盖数据到预训练、微调、部署和评测等全流程,如INTETRAIN、XTA、i M Deploy等。
- 数据集:提供丰富多样的数据,支持数据清洗、安全处理和公开使用。
- 性能评测与差距:大模型整体能力仍有提升空间,尤其在理科能力上,中文场景下国内模型表现出色。
- 部署解决方案:i M Deploy支持模型轻量化、量化和推理服务,与评测工具无缝对接。


文档笔记:





















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









