







 本文详细探讨了Android系统中的音频与视频处理技术,包括StageFright媒体框架、ALSA音频系统、I2S总线、SD卡驱动、中断处理、并发控制等关键组件与原理。此外,文章还介绍了USB设备的枚举过程、USB设备的内存管理、以及嵌入式Linux启动优化策略。通过深入分析,旨在为开发者提供全面的技术指导。
本文详细探讨了Android系统中的音频与视频处理技术,包括StageFright媒体框架、ALSA音频系统、I2S总线、SD卡驱动、中断处理、并发控制等关键组件与原理。此外,文章还介绍了USB设备的枚举过程、USB设备的内存管理、以及嵌入式Linux启动优化策略。通过深入分析,旨在为开发者提供全面的技术指导。

StageFright (SF)媒体框架
1,播放标准audio格式
2,SF媒体架构作为客户接口和Qualcomm OpenMAX接口进行通讯,对adsp支持的audio格式进行解码。
3,解码后的audio流传递给audio manager
4,位置: \frameworks\base\ media\libstagefright
Audio manager/AudioFlinger
1, 所有的audio输出设备都要通过libaudio接口
2, 将多种audio流处理为PCM audio并且将audio路由为各种输出设备。
3, 这个地方主要有audiopolicyserver来实现。
4,位置\frameworks\base\services\ audioflinger
HAL
1,Google audio管理和qualcomm PCM与RPC驱动的中间层
2,管理设备配置,增益控制,audio的后处理
3,\hardware\msm7k\libaudio
OpenMAX IL
1,OpenMAX IL层基于Qualcomm audio解码驱动向SF媒体框架定义了软件接口
2,位置\vendor\qcom-opensource\omx
PCM driver
1,处理PCM播放,PCM录音,和audio后处理与前处理
2,分配PMEM内存
3,\kernel\arch\arm\mach-msm\ qdsp5\audio_out.c, audio_in.c and audpp.c
Audio decoder driver
1,接口层位于ADSP和OpenMAX IL之间
2,分配PMEM内存
3,\kernel\arch\arm\mach-msm\ qdsp5\audio_mp3.c,audio_aa.c
Audio encoder driver
1,接口层位于ADSP和用户HAL层(libaudio)之间
2,分配PMEM内存
3,位置:\kernel\arch\arm\ mach-msm\qdsp5\audio_voicememo.c
ADSP driver
1,接口位于ADSP和kernel audio驱动之间
2,管理了命令和反馈信息
3,位置:\kernel\arch\arm\mach-msm\ adsp*.*
RPC router
1,把命令和反馈信息在app处理器和mp处理器之间路由
2,服务器在mp处理器,客户端在ap处理器
3,位置:\kernel\arch\arm\mach-msm\rpc*.*
耳机服务属于这个rpc类型
2. http://blog.youkuaiyun.com/droidphone/article/details/6271122
ALSA是Advanced Linux Sound Architecture 的缩写,目前已经成为了linux的主流音频体系结构,想了解更多的关于ALSA的这一开源项目的信息和知识,请查看以下网址:http://www.alsa-project.org/。
在内核设备驱动层,ALSA提供了alsa-driver,同时在应用层,ALSA为我们提供了alsa-lib,应用程序只要调用alsa-lib提供的API,即可以完成对底层音频硬件的控制。

由图1.1可以看出,用户空间的alsa-lib对应用程序提供统一的API接口,这样可以隐藏了驱动层的实现细节,简化了应用程序的实现难度。内核空间中,alsa-soc其实是对alsa-driver的进一步封装,他针对嵌入式设备提供了一些列增强的功能。本系列博文仅对嵌入式系统中的alsa-driver和alsa-soc进行讨论。
3. android audio系统 : I2S/PCM/AC97 codec与cpu之间的协议/接口/总线
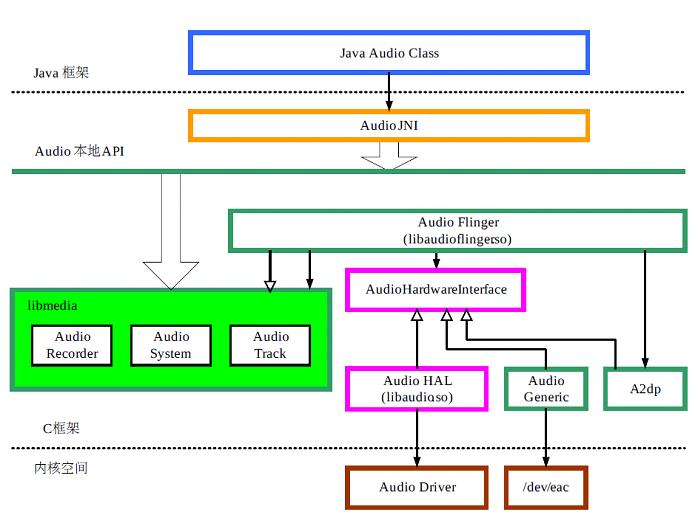
Audio系统主要分成如下几个层次:
(1)media库提供的Audio系统本地部分接口;
(2)AudioFlinger作为Audio系统的中间层;
(3)Audio的硬件抽象层提供底层支持;
(4)Audio接口通过JNI和Java框架提供给上层。
Audio系统的各个层次接口主要提供了两方面功能:放音(Track)和录音(Recorder)。
Android的Audio系统结构如图7-1所示。
4.I2S
I2S编辑
I2S(Inter—IC Sound)总线是飞利浦公司为数字音频设备之间的音频数据传输而制定的一种总线标准,该总线专责于音频设备之间的数据传输,广泛应用于各种多媒体系统。它采用了沿独立的导线传输时钟与数据信号的设计,通过将数据和时钟信号分离,避免了因时差诱发的失真,为用户节省了购买抵抗音频抖动的专业设备的费用。
I2S有3个主要信号
串行数据(SD)
5. sd卡驱动

4.1.1.MMC子系统的代码在kernel/driver/MMC下面,目前MMC子系统支持一些形式的记忆卡:SD,SDIO,MMC。
4.1.2.HOST:针对不同主机的驱动程序,这一部分需要根据自己的特定平台来完成。
4.1.3.CORE:这是整个MMC的核心层,这部分完成了不同协议和规范的实现,并且为HOST层的驱动提供接口函数。
4.1.4.CARD:因为这些记忆卡都是块设备,当然需要提供块设备的驱动程序,这部分就是实现了将SD卡如何实现为块设备的。

(1)

SD卡引脚功能详述:
|
引脚
编号
|
SD模式
|
| ||||
|
名称
|
类型
|
描述
|
名称
|
类型
|
描述
| |
|
1
|
CD/DAT3
|
IO或PP
|
卡检测/
数据线3
|
#CS
|
I
|
片选
|
|
2
|
CMD
|
PP
|
命令/
回应
|
DI
|
I
|
数据输入
|
|
3
|
VSS1
|
S
|
电源地
|
VSS
|
S
|
电源地
|
|
4
|
VDD
|
S
|
电源
|
VDD
|
S
|
电源
|
|
5
|
CLK
|
I
|
时钟
|
SCLK
|
I
|
时钟
|
|
6
|
VSS2
|
S
|
电源地
|
VSS2
|
S
|
电源地
|
|
7
|
DAT0
|
IO或PP
|
数据线0
|
DO
|
O或PP
|
数据输出
|
|
8
|
DAT1
|
IO或PP
|
数据线1
|
RSV
|
|
|
|
9
|
DAT2
|
IO或PP
|
数据线2
|
RSV
|
|
|
注:S:电源供给
PP:采用推拉驱动的输入输出
SD卡SPI模式下与单片机的连接图:

SD卡支持两种总线方式:SD方式与SPI方式。其中SD方式采用6线制,使用CLK、CMD、DAT0~DAT3进行数据通信。而SPI方式采用4线制,使用CS、CLK、DataIn、DataOut进行数据通信。SD方式时的数据传输速度与SPI方式要快,采用单片机对SD卡进行读写时一般都采用SPI模式。采用不同的初始化方式可以使SD卡工作于SD方式或SPI方式。这里只对其SPI方式进行介绍。
SD卡的SPI通信接口使其可以通过SPI通道进行数据读写。从应用的角度来看,采用SPI接口的好处在于,很多单片机内部自带SPI控制器,不光给开发上带来方便,同时也见降低了开发成本。然而,它也有不好的地方,如失去了SD卡的性能优势,要解决这一问题,就要用SD方式,因为它提供更大的总线数据带宽。SPI接口的选用是在上电初始时向其写入第一个命令时进行的。以下介绍SD卡的驱动方法,只实现简单的扇区读写。
////////////////////////
linux内核里面,内存申请有哪几个函数,各自的区别?
kmalloc vmalloc
kmalloc:分配连续的物理地址,如果没有这么大的,就是败了
vmalloc: 分配虚拟地址,在物理上不一定连续
不同处是他们的中断处理函数不同,
FIQ 优先
int *a;
char *b;
a 和 b本身是什么类型?
a、b里面本身存放的只是一个地址,难道是这两个地址有不同么?
a 、b本身是同一种类型,都是指针,不过它们所指的单元的类型是不一样的,一个是整形数,一个是字符
a中放的是指向int类型的指针的地址b中放的是指向char类型的指针的地址
两个不同的地址
讲下分成上半部分和下半部分的原因,为何要分?讲下如何实现?
中断处理程序从概念上被分为上半部分(top half)和下半部分(bottom half)。硬件的中断请求
在中断发生时上半部分的处理 过程立即执行,因为它是完全屏蔽中断的,所以要快,否则其它的中断就得不到及时的处理。(快速中断)
但是下半部分(如果有的话)几乎做了中断处理程序所有的事情,可以 推迟执行。
内核把上半部分和下半部分作为独立的函数来处理,上半部分的功能就是“登记中断”,决定其相关的下半部分是否需要执行。需要立即执行的部分必须 位于上半部分,而可以推迟的部分可能属于下半部分。下半部分的任务就是执行与中断处理密切相关但上半部分本身不执行的工作。
这样划分是有一定原因的,因为我们必须有一个快速、异步而且简单的处理程序专门来负责对硬件的中断请求做出快速响应,与此同时也要完成那些对时间要求很严格的操作。而那些对时间要求相对宽松,其他的剩余工作则会在稍候的任意时间执行,也就是在所谓的下半部分去执行。(中断上下两部分最大的不同是:上半部分不可中断,而下半部分可中断。)
在理想的情况下,最好是中断处 理程序上半部分将所有工作都交给下半部分执行,这样的话在中断处理程序上半部分中完成的工作就很少,也就能尽可能快地返回。
总之,这样划分一个中断处理过程主要是希望减少中断处理程序的工作量(当然了,理想情况是将全部工作都抛给下半段。但是中断处理程序至少应该完成对中断请求的相应。),因为在它运行期间至少会使得同级的中断请求被屏蔽,这些都直接关系到整个系统的响应能力和性能。而在下半段执行期间,则会允许响应所有的中断。和上半段只能通过中断处理程序实现不同的是,下半部可以通过多种机制来完成:小任务(tasklet),工作队列,软中断。
内核函数mmap的实现原理,机制
1、mmap系统调用(功能)
void* mmap ( void * addr , size_t len , int prot , int flags ,int fd , off_t offset )
内存映射函数mmap, 负责把文件内容映射到进程的虚拟内存空间, 通过对这段内存的读取和修改,来实现对文件的读取和修改,而不需要再调用read,write等操作。

2、mmap系统调用(参数)
1)addr: 指定映射的起始地址, 通常设为NULL, 由系统指定。
2)length: 映射到内存的文件长度。
3) prot: 映射区的保护方式, 可以是:
PROT_EXEC: 映射区可被执行
PROT_READ: 映射区可被读取
PROT_WRITE: 映射区可被写入
4)flags: 映射区的特性, 可以是:
MAP_SHARED:写入映射区的数据会复制回文件, 且允许其他映射该文件的进程共享。
MAP_PRIVATE:对映射区的写入操作会产生一个映射区的复制(copy-on-write), 对此区域所做的修改不会写回原文件。
5)fd: 由open返回的文件描述符, 代表要映射的文件。
6)offset: 以文件开始处的偏移量, 必须是分页大小的整数倍, 通常为0, 表示从文件头开始映射。
3、解除映射
int munmap(void *start,size_t length)
功能:取消参数start所指向的映射内存,参数length表示欲取消的内存大小。
返回值:解除成功返回0,否则返回-1,错误原因存于errno中。
驱动里面为什么要有并发、互斥的控制?如何实现?讲个例子?
并发(concurrency)指的是多个执行单元同时、并行被执行,而并发的执行单元对 共 享资源(硬件资源和软件上的全局变量、静态变量等)的访问则很容易导致竞态(race conditions) 。 解决竞态问题的途径是保证对共享资源的互斥访问, 所谓互斥访问就是指一个执行单 元 在访问共享资源的时候,其他的执行单元都被禁止访问。 访问共享资源的代码区域被称为临界区, 临界区需要以某种互斥机 制加以保护, 中断屏蔽, 原子操作,自旋锁,和信号量都是 linux 设备驱动中可采用的互斥途径。
-------自旋锁对信号量------------------------------------------------------
需求 建议的加锁方法
低开销加锁 优先使用自旋锁
短期锁定 优先使用自旋锁
长期加锁 优先使用信号量
中断上下文中加锁 使用自旋锁
持有锁是需要睡眠、调度 使用信号量
spinlock自旋锁是如何实现的?
spinlock 用于CPU同步(多个), 它的实现是基于CPU锁定数据总线的指令.
当某个CPU锁住数据总线后, 它读一个内存单元(spinlock_t)来判断这个spinlock 是否已经被别的CPU锁住. 如果否, 它写进一个特定值, 表示锁定成功, 然后返回. 如果是, 它会重复以上操作直到成功, 或者spin次数超过一个设定值. 锁定数据总线的指令只能保证一个机器指令内, CPU独占数据总线.
单CPU当然能用spinlock, 但实现上无需锁定数据总线.
spinlock在锁定的时候,如果不成功,不会睡眠,会持续的尝试,单cpu的时候spinlock会让其它process动不了.
任务调度的机制????
调度程序运行时,要在所有可运行状态的进程中选择最值得运行的进程投入运行。选择进程的依据是什么呢?在每个进程的task_struct结构中有以下四 项:policy、priority、counter、rt_priority。这四项是选择进程的依据。其中,policy是进程的调度策略,用来区分 实时进程和普通进程,实时进程优先于普通进程运行;priority是进程(包括实时和普通)的静态优先级;counter是进程剩余的时间片,它的起始 值就是priority的值;由于counter在后面计算一个处于可运行状态的进程值得运行的程度goodness时起重要作用,因此,counter 也可以看作是进程的动态优先级。rt_priority是实时进程特有的,用于实时进程间的选择。
Linux用函数goodness()来衡量一个处于可运行状态的进程值得运行的程度。该函数综合了以上提到的四项,还结合了一些其他的因素,给每个处于 可运行状态的进程赋予一个权值(weight),调度程序以这个权值作为选择进程的唯一依据。关于goodness()的情况在后面将会详细分析。
Linux进程调度分为主动调度和被动调度两种方式:
自愿的调度随时都可以进行,内核里可以通过schedule()启动一次调度,当然也可以将进程状态设置为TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE,暂时放弃运行而进入睡眠;用户空间可以通过pause()达到同样的目的;如果为这种暂时的睡眠放弃加上时间限制,内核态有schedule_timeout,用户态有nanosleep()用于此目的;注意内核中这种主动放弃是不可见的,隐藏在每一个可能受阻的系统调用中,如open()、read()、select()等。
被动调度发生在系统调用返回的前夕、中断异常处理返回前、用户态处理软中断返回前。
自从Linux 2.6内核后,linux实现了抢占式内核,即处于内核态的进程也可能被调度出去。比如一个进程正在内核态运行,此时一个中断发生使另一个高权值进程就绪,在中断处理程序结束之后,linux2.6内核之前的版本会恢复原进程的运行,直到该进程退出内核态才会引发调度程序;而linux2.6抢占式内核,在处理完中断后,会立即引发调度,切换到高权值进程。为支持内核代码可抢占,在2.6版内核中通过采用禁止抢占的自旋锁来保护临界区。在释放自旋锁时(spin_unlock_mutex),同样会引发调度检查。而对那些长期持锁或禁止抢占的代码片段插入了抢占点,此时检查调度需求,以避免不合理的延迟发生。而在检查过程中,调度进程很可能就会中止当前的进程来让另外一个进程运行,只要新的进程不需要持有该锁。
嵌入式linux和wince操作系统的特点和特性
Linux与嵌入式 Wince的比较 Linux与 Wince在实际的嵌入式系统应用上有各自的优势,下面从九个方面对它们进行比较:
1)开源方面
Linux是开放源代码的,不在存黑箱技术,遍布全球的众多 Linux爱好者都是 Linux开发者的强大技术支持者,Linux的源代码随处可得,注释丰富,文档齐全,易于解决各种问题;而 Windows CE是非开放性OS,使第三方很难实现产品定制。
2)内核大小
Linux的内核小、效率高;而 Windows CE在这方面是笨拙的,占用过多的RAM,应用程序庞大。
3)费用方面
Linux是开放源代码的OS,在价格上极具竞争力,适合中国国情。Windows CE的版权费用是厂家不得不考虑的因素。
4)支持平台
Linux不仅支持 x86芯片,还是一个跨平台的系统。到目前为止,它可以支持20~30种CPU。
5)网络功能
Linux内核的结构在网络方面是非常完整的,它提供了对包括十兆位、百兆位及千兆位的以太网络,还有无线网络、Token ring(令牌环)和光纤甚至卫星的支持。
6)可裁剪性
Linux在内核结构的设计中考虑适应系统的可裁减性的要求,Windows CE在内核结构的设计中并未考虑适应系统的高度可裁减性的要求。
1 )开发难度 Linux开发难度较高,需要很高的技术实力。
2 )调试工具 Linux调试工具不全,调试不太方便,尚没有很好的用户图形界面。
3 )占用内存
嵌入式 Linux占用较大的内存,当然,人们可以去掉部分无用的功能来减小使用的内存,但是如果不仔细,将引起新的问题。
嵌入式linux中tty设备驱动的体系结构??
Linux系统的终端设备一般有以下几种:
- 1、 控制台
- 系统控制台/dev/console
/dev/console是系统控制台,是与操作系统交互的设备。系统所产生的信息会发送到该设备上。平时我们看到的PC只有一个屏幕和键盘,它其实就是控制台。目前只有在单用户模式下,才允许用户登录控制台/dev/console。(可以在单用户模式下输入tty命令进行确认)。
console有缓冲的概念,为内核提供打印输出。内核把要打印的内容装入缓冲区__log_buff,然后由console来决定打印到哪里(比如是tty0还是ttySn等)。console指向激活的终端。历史上,console指主机本身的屏幕和键盘,而tty指用电缆链接的其它位置的控制台。
某些情况下console和tty0是一致的,就是当前所使用的是虚拟终端,也是激活虚拟终端。所以有些资料中称/dev/console是到/dev/tty0的符号链接,但是这样说现在看来是不对的:根据内核文档,在2.1.71之前,/dev/console根据不同系统设定,符号链接到/dev/tty0或者其他tty*上,在2.1.71版本之后则完全由内核代码内部控制它的映射。
如果一个终端设备要实现console功能,必须向内核注册一个struct console结构,一般的串口驱动中都会有。如果设备要实现tty功能,必须要内核的tty子系统注册一个struct tty_driver结构,注册函数在drivers/tty/tty_io.c中。一个设备可以同时实现console和tty_driver,一般串口都这么做。
- 当前控制台: /dev/tty
这是应用程序中的概念,如果当前进程有控制终端(Controlling Terminal),那么/dev/tty就是当前进程控制台的设备文件。对于你登录的shell,/dev/tty就是你使用的控制台,设备号是(5,0)。不过它并不指任何物理意义上的控制台,/dev/tty会映射到当前设备(使用命令“tty”可以查看它具体对应哪个实际物理控制台设备)。输出到/dev/tty的内容只会显示在当前工作终端上(无论是登录在ttyn中还是pty中)。你如果在控制台界面下(即字符界面下)那么dev/tty就是映射到dev/tty1-6之间的一个(取决于你当前的控制台号),但是如果你现在是在图形界面(Xwindows),那么你会发现现在的/dev/tty映射到的是/dev/pts的伪终端上。/dev/tty有些类似于到实际所使用终端设备的一个联接。
你可以输入命令 “tty",将显示当前映射终端如:/dev/tty1或者/dev/pts/0等。也可以使用命令“ps -ax”来查看其他进程与哪个控制终端相连。
在当前终端中输入 echo “tekkaman” > /dev/tty ,都会直接显示在当前的终端中。
- 虚拟控制台 /dev/ttyn
/dev/ttyn是进程虚拟控制台,他们共享同一个真实的物理控制台。
如果在进程里打开一个这样的文件且该文件不是其他进程的控制台时,那该文件就是这个进程的控制台。进程printf数据会输出到这里。在PC上,用户可以使用alt+Fn切换控制台,看起来感觉存在多个屏幕,这种虚拟控制台对应tty1~n,其中 :
/dev/tty1等代表第一个虚拟控制台
例如当使用ALT+F2进行切换时,系统的虚拟控制台为/dev/tty2 ,当前控制台(/dev/tty)则指向/dev/tty2
在UNIX系统中,计算机显示器通常被称为控制台(Console)。它仿真了类型为Linux的一种终端,并且有一些设备特殊文件与之相关联:tty0、tty1、tty2等。当你在控制台上登录时,使用的是tty1。使用Alt+[F1—F6]组合键时,我们就可以切换到tty2、tty3等上面去。
你可以登录到不同的虚拟控制台上去,因而可以让系统同时有几个不同的会话存在。
而比较特殊的是/dev/tty0,他代表当前虚拟控制台,是当前所使用虚拟控制台的一个别名。因此不管当前正在使用哪个虚拟控制台(注意:这里是虚拟控制台,不包括伪终端),系统信息都会发送到/dev/tty0上。只有系统或超级用户root可以向/dev/tty0进行写操作。tty0是系统自动打开的,但不用于用户登录。在Framebuffer设备没有启用的系统中,可以使用/dev/tty0访问显卡。
- 2、 伪终端pty(pseudo-tty)
伪终端(Pseudo Terminal)是终端的发展,为满足现在需求(比如网络登陆、xwindow窗口的管理)。它是成对出现的逻辑终端设备(即master和slave设备, 对master的操作会反映到slave上)。它多用于模拟终端程序,是远程登陆(telnet、ssh、xterm等)后创建的控制台设备。
历史上,有两套伪终端软件接口:BSD接口:较简单,master为/dev/pty[p-za-e][0-9a-f] ;slave为 /dev/tty[p-za-e][0-9a-f] ,它们都是配对的出现的。例如/dev/ptyp3和/dev/ttyp3。但由于在编程时要找到一个合适的终端需要逐个尝试,所以逐渐被放弃。
Unix 98接口:使用一个/dev/ptmx作为master设备,在每次打开操作时会得到一个master设备fd,并在/dev/pts/目录下得到一个slave设备(如 /dev/pts/3和/dev/ptmx),这样就避免了逐个尝试的麻烦。由于可能有好几千个用户登陆,所以/dev/pts/*是动态生成的,不象其他设备文件是构建系统时就已经产生的硬盘节点(如果未使用devfs、udev、mdev等) 。第一个用户登陆,设备文件为/dev/pts/0,第二个为/dev/pts/1,以此类推。它们并不与实际物理设备直接相关。现在大多数系统是通过此接口实现pty。我们在X Window下打开的终端或使用telnet 或ssh等方式登录Linux主机,此时均通过pty设备。例如,如果某人在网上使用telnet程序连接到你的计算机上,则telnet程序就可能会打开/dev/ptmx设备获取一个fd。此时一个getty程序就应该运行在对应的/dev/pts/*上。当telnet从远端获取了一个字符时,该字符就会通过ptmx、pts/*传递给 getty程序,而getty程序就会通过pts/*、ptmx和telnet程序往网络上返回“login:”字符串信息。这样,登录程序与telnet程序就通过“伪终端”进行通信。
- telnet<--->/dev/ptmx(master)<--->pts/*(slave)<--->getty
如果一个程序把 pts/*看作是一个串行端口设备,则它对该端口的读/写操作会反映在该逻辑终端设备对的另一个/dev/ptmx上,而/dev/ptmx则是另一个程序用于读写操作的逻辑设备。这样,两个程序就可以通过这种逻辑设备进行互相交流,这很象是逻辑设备对之间的管道操作。对于pts/*,任何设计成使用一个串行端口设备的程序都可以使用该逻辑设备。但对于使用/dev/ptmx的程序,则需要专门设计来使用/dev/ptmx逻辑设备。
通过使用适当的软件,就可以把两个甚至多个伪终端设备连接到同一个物理串行端口上。
- 实验:
- 1、在X下打开一个或N个终端窗口
- 2、#ls /dev/pts/*
- 3、关闭这个X下的终端窗口,再次运行;比较两次输出信息就明白了。
- 输出为/dev/ptmx /dev/pts/1存在一(master)对多(slave)的情况
- 3、 串口终端(/dev/ttySn)
串行端口终端(Serial Port Terminal)是使用计算机串行端口连接的终端设备。计算机把每个串行端口都看作是一个字符设备。有段时间串行端口设备通常被称为终端设备,那时它的最大用途就是用来连接终端,所以这些串行端口所对应的设备名称是/dev/tts/0(或/dev/ttyS0)、/dev/tts/1(或/dev /ttyS1)等,设备号分别是(4,0)、(4,1)等(对应于win系统下的COM1、COM2等)。若要向一个端口发送数据,可以在命令行上把标准输出重定向到这些特殊文件名上即可。
例如,在命令行提示符下键入:echo tekkaman> /dev/ttyS1会把“tekkaman”发送到连接在ttyS1(COM2)端口的设备上。
在2.6以后的内核中,部分三星芯片(例如S3C24x0等)将串口终端设备节点命名为ttySACn。TI的Omap系列芯片从2.6.37开始芯片自带的UART设备开始使用专有的的omap-uart驱动,故设备节点命名为ttyOn,以区别于使用8250驱动时的设备名“ttySn”。
- 4、 其它类型终端
还针对很多不同的字符设备存在有很多其它种类的终端设备特殊文件,例如针对ISDN设备的/dev/ttyIn终端设备等。
~~~~~~~~~~~~~~首先看看tty框架:(
- 终端或这TTY设备是一类特殊的字符设备。
- 一个终端设备是任何对于一个会话可以作为控制终端的设备。
- 这包括虚拟控制台、串口和伪终端(PTYs)。)
在linux系统中,tty表示各种终端。终端通常都跟硬件相对应。比如对应于输入设备键盘鼠标,输出设备显示器的控制终端和串口终端。
下面这张图是一张很经典的图了,很清楚的展现了tty框架的层次结构,大家先看图,下面给大家解释。

最上面的用户空间会有很多对底层硬件(在本文中就是8250uart设备)的操作,像read,write等。用户空间主要是通过设备文件同tty_core交互,tty_core根据用空间操作的类型再选择跟line discipline和tty_driver也就是serial_core交互,例如设置硬件的ioctl指令就直接交给serial_core处理。Read和write操作就会交给line discipline处理。Line discipline是线路规程的意思。正如它的名字一样,它表示的是这条终端”线程”的输入与输出规范设置,主要用来进行输入/输出数据的预处理。处理之后,就会将数据交给serial_core,最后serial_core会调用8250.c的操作。
对于TTY系统的理解(图解):

嵌入式设备,为加快启动速度,可以做哪些方面的优化??????
By Falcon ofTinyLab.org
2009/02/17
背景
Linux 世界精彩纷呈,因为它自由、开放,是众多牛人智慧碰撞的结晶。
虽然硬件在不断地更新换代,但是这本身并没有给系统的启动速度带来太大的变化,反而是这之外的创新带来了革命性的变化。就加速 Linux 启动这一块而言,就是日新月异,创新辈出,下面简要回顾一下人们的探索和创新过程,以及我们未来可以做的一些工作。
如何优化 Linux 启动速度
首先来看看 Linux 系统的大概启动过程,可以通过 man boot查看到。
$ man boot
大概列出来这么几部分:
- Hardware-boot(BIOS)
- OS Loader
- Kernel Startup
- init and inittab
- Boot Scripts
- Sequencing Directories
- …
常规做法
为了能够加速 Linux 系统的启动,通常的做法是对这些步骤本身进行优化,比如:
- 减少或者合并某些步骤
- 对某些步骤内部进行优化
针对第一个,有人已经把 Linux 系统内置到了主板上(如 splashtop),这可以说是对前面三步的合并。而对于第二个办法,则有大量的例子,比如:
-
采用经过优化的专有(相对通用而言,比如Lilo, Grub)的 BIOS 和 BootLoader,比如 Lemote.com 公司采用的 PMON 2000。
-
至于内核启动过程的优化,则有大量的分析工具来跟踪内核的启动过程的函数调用图,找出可以优化的 hotspot,然后同样可以采用减少或者合并某些步骤以及对子步骤进行优化的措施来加速内核本身的启动。这类分析工具有 KFT(注:最新 mainline Linux 已经采用 Ftrace) 和 kgcov 5。
-
在传统的 Linux 发行版上采用的是 init 这个进程管理工具,而在 Ubuntu 6.10 以后则采用了基于事件的 upstart来加速进程启动过程,当然这也可以说是策略上的创新。类似地,Fedora 则采用了另外一套 systemd。
-
在启动 init 以后实际上就已经到了进程世界了,之后可能就需要通过脚本启动一序列的进程,这里可以做的优化包括把一些脚本替换为二进程程序(重写部分代码),然后通过诸如 bootchart 这样的工具来分析进程启动过程,然后对进程启动过程进行优化,同样可以采用上面提到的通常的做法。
-
对某些重要的进程运行进行优化,这种优化包括两个层面:第一个优化进程的内部启动过程,比如去掉某些不必要的初始化,另外一个是以进程使用过的内核系统调用作为入口,对内核进行优化,大概的做法是通过 strace跟踪到进程运行过程中调用的系统调用,然后通过 KFT/Ftrace 与 Kgcov 对内核进行优化,类似的工具可能还有 gcov, gprof, oprofile和 LTT等。对于系统启动而言,这类初始化比较重要的程序当然是 X 系统和你所采用的桌面管理程序。
非常规化方法
这些通常的做法确实也有效地提高了内核的启动速度,但是并没有带来质的变化。根本原因在于这种优化的策略是面向过程的,面向某一个具体的对象的,一种更为革命的做法是采用系统化的抽象化方法,不直接面向过程,也不直接面向某个具体对象。而是统观全局,下面我们来介绍这样一种策略。
-
Kexec:复用初始化过程
BIOS 与 Bootloader 也好,内核也好,启动的时候都需要对硬件进行扫描和初始化,但是对于某台组装好的机器来说,这些硬件是固定的,硬件信息也是固定,如果内核在第一次启动的时候就获取到了这些信息,并设法保存起来,这样下次启动时就可以忽略这样一个过程,从而加速以后的过程,采用这种方法的有 kboot(kexec-bootloader)。
-
STR:能耗换时间
另外一种更极端的做法是,既然可以保存硬件的初始化信息,为什么不可以保存某次常用进程都运行的内存状态,在下次开机时直接进入该状态,而越过大量的进程启动过程呢?而这一类实现就是通过休眠/唤醒到内存(STR)来模拟关机/开机,某些 Android 手机厂商就是这么做。
可以预想,如果能够有效结合这些策略,并通过不断创新,挖掘新的想法,系统的启动速度到时候将让我们无法预料。
更多的一些思路有在嵌入式 Linux 基金会的 Wiki 上做了详细介绍: Boot Time和 Boot up Time Reduction Howto。
USB设备的枚举过程?????
主机对一个USB设备的识别是经过一个枚举的过程来完成的,主机的总线枚举器随时监控必要的设备状态变化。总线枚举的过程如下:
(1)设备连接。USB设备经USB总线连接主机。
(2)设备上电。USB设备可以自供电,也可以使用USB总线供电。
(3)主机检测到设备,发出复位。主机通过检测设备在总线的上拉电阻检测到有新的设备连接,并获释设备是全速设备还是低速设备,然后向该端口发送一个复位信号。
(4)设备默认状态。设备从总线上接收到一个复位信号后,才可以对总线的处理操作做出响应。设备接收到复位信号后,就暂时使用默认地址(00H)来响应主机的命令。
(5)地址分配。当主机接收到有设备对默认地址(00H)响应的时候,就分配给设备一个空闲的地址,以后设备就只对该地址进行响应。
(6)读取USB设备描述符。主机读取USB设备描述符,确认USB设备的属性。
(7)设备配置。主机依照读取的USB设备描述符来进行配置,如果设备所需的USB资源得以满足,就发送配置命令给USB设备,表示配置完毕。
(s)挂起。如果使用总线供电,为了节省电源,当总线保持空闲状态超过3ms以后,设备驱动程序就会进入挂起状态,在挂起状态时,USB设备保留了包括其地址和配置信息在内的所有内部状态,设备的消耗电流不超过
500uA。
USB设备的枚举过程的具体说明如下:USB总线驱动程序自动检测新插入的USB设备。然后它读取设备内的设备描述符以查明插入的是何种设备,描述符中的厂商和产品标识以及其它描述符一同决定具体安装哪一个驱动程序。配置管理器调用驱动程序的AddDvecie函数。AddDvecie做以下工作:创建设备对象,把设备对象连接到驱动程序堆栈上,等等。最后,配置管理器向驱动程序发送一个即插即用请求IRP_MN_START_DEVICE。它通过调用一个名为StartDevice的辅助函数并传递一些参数,这些参数描述了赋予设备的经过转换的和未经转换的I/O资源。实际上它们不用任何I/O资源。USB使用了许多方法来帮助操作系统定位驱动程序,包括设备上的设备描述符、配置描述符,以及接口描述符。对于有厂商和产品标识的设备,配置管理器首先在注册表中查找设备名称,例如名为USB/VID一0471&PID-0666的设备。如果注册表中没有这个表项,配置管理器将触发“新硬件向导”来寻找该设备的INF文件。新硬件向导向用户询问INF文件的位置,然后安装驱动程序并填写注册表。一旦配置管理器找到了注册表表项,它就可以动态地装载驱动
程序。StartDveiee的执行过程大致如下,首先为设备选择一个配置。如果你的设备像大多数设备一样,应该仅有一种配置。选定了某个配置后,接着应该选择配置中的一个或多个接口。选定了一个配置和一组接口后,你应该向总线驱动程序发送配置选择URB。最后,总线驱动程序向设备发出命令确定能选定的配置和接口。总线驱动程序负责创建管道和用于访问管道的句柄,管道提供功能驱动程序与选定接口端点之间的通信,它同时还创建配置句柄和接口句柄。你可以从完成的URB中提取这些句柄,并保存为以后使用。至此,设备的枚举过程全部结束。
strncpy的源代码实现
#include <stdio.h>
#include <stdlib.h>
char* strncpy(char *dest,char *src,unsigned int n){
char *strRtn=dest;
while(n && (*dest++=*src++)){
n--;
}
printf("n:%d/n",n);
if(n)
{
while(--n)
*dest++;
}
return strRtn;
}
int main(){
char* dest=(char*)malloc(sizeof(char)*100);
char *src="helloworld!";
printf("%s/n",strncpy(dest,src,300));
}
C语言 把两个有序链表合并为一个有序链表(递增)
第一个有序链表是生成5个0~50的随机数,第二个有序链表是生成5蹶0~100的随机数,然後把它们合并
原题目:Write a program that inserts 5 random integers between 0 to 50 in order in one linked list and 5 random integers between 0 and 100 in order in another linked list.The program must merge these two linked lists into a single ordered list of integers.
设链表结点结构为Node(int data, Node *next),typedef Node List,链表均带表头结点。思路是:把list1中的元素看成是集合1,把list2中的元素看成是集合2,把list1头结点(即list1结点)从集合1中脱离下来看成是目标集合的头结点,目标集合开始时是空集,并用last指针始终指向该集合的尾部,然后每次从集合1和集合2中取各自的第一个元素进行比较,较小者从相应集合里脱离,插入到目标集合list1的尾部即last的末尾,并将刚插入的元素作为目标集合list1的新的last,直到集合1为空或集合2为空时结束,最后将未空的集合中的剩余元素链接到last后面即可。
void Merge(List *list1, List *list2) {
/*将有序单链表list2合并到有序单链表list1中,并使list1仍然有序*/
Node *p, *q, *r, *last;
p = list1->next; /*p始终指向集合1的第一个元素*/
q = list2->next; /*q始终指向集合2的第一个元素*/
last = list1; /*将list1看成是目标集合,并从集合1中脱离,并将last始终指向表尾*/
last->next = NULL;
while(p && q) { /*当集合1和集合2都不空时*/
if(p->data < q->data) { /*取两集合中各自的第一个元素进行比较,取其中小者*/
r = p;
p = p->next;
}
else {
r = q;
q = q->next;
}
/*将较小者从相应集合中脱离并插入到目标集合list1的末尾,并使之成为新的last*/
r->next = last->next;
last->next = r;
last = r;
}
/*将未空集合中剩余元素都链接到目标集合list1的last的后面*/
if(p) last->next = p;
else last->next = q;
list2->next = NULL; /*现在的list2为空集了,赋空是为了避免list2的next指针悬空*/
}
嵌入式系统高级C语言编程及位操作
(2007-12-03 22:48:55)标签: it/科技 |
#include "stdafx.h"
#include "stdio.h"
unsigned
{
}
main()
{
}
这个程式运行起来是没有问题的。但是如果进行如下的改动就有问题了。
不是优先级的问题。
问题2:
怎样实现取字符的第n位值(返回0或1)的函数 BOOL GetBit(unsignedchar srcChar,int nBit)?
bool GetBit(unsigned srcChar,int nBit){
}
问题3:嵌入式系统高级C语言编程
一个整型数
int a;
一个指向整型数的指针
int *a;
一个指向指针的指针,它指向的指针是指向一个整型数
int **a;
一个有10个整型数的数组
int a[10];
一个有10个指针的数组,该指针是指向一个整型数的
int*a[10];
一个指向函数的指针,该函数有一个整型参数并返回一个整型数
int (*a)(int);
一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参并返回一个整型数
int (*a[10])(int);
关键字static的作用是什么?
在C语言中,关键字static有三个明显的作用:
1)在函数体,一个被声明为静态的变量在这一函数被调用过程中维持其值不变
2)在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所有函数访问,但不能被模块外其它函数访问,它是一个本地的全局变量。
3)在模块内,一个被声明为静态的函数只可被这一模块内的其他函数调用。那就是,这个函数被限制在声明它的模块的本地范围内使用。
const int a;
int const a;
const int *a;
int * const a;
int const *a const;
前两个的作用是一样,a 是一个常整型数;
第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可以修改的,但指针可以)
第四个意思a是一个指向整型数的常指针(指针指向的整型数是可以修改的,但是指针是不可以修改的)
最后一个意味着a是一个指向常整型数的常指针(指针指向的整型数是不可修改的,同时指针也是不可修改的)
const的优点:关键字const的作用是为给读你代码的人传达非常有用的信息,实际上,声明一个参数为常量是为了告诉了用户这个参数的应用目的。如果你曾花很多时间清理其它人留下的垃圾,你就会很快学会感谢这点多余的信息。
通过给优化器一些附加的信息,使用关键字const也许能产生更紧凑的代码。
合理地使用关键字const可以使编译器很自然的保护那些不希望被改变的参数,防止其被无意的代码修改。
简而言之,可以减少bug的实现。
一个定义为volatile的变量是说这个变量可能会被意想不到地改变。这样,编译器就不会去假设这个变量的值了。
精确的说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器的备份。下面是
volatile变量的几个例子:
1)并行设备的硬件寄存器(如:状态寄存器)
2)一个中断服务子程序中会访问到的非自动变量
3)多线程应用中被几个任务共享的变量。
嵌入式系统总是要用户对变量或寄存器进行位操作。给定一个整型变量a,写两段代码,第一个设置a的bit3,第二个清除a
的bit 3。在以上两个操作中,要保持其它位不变。
#define BIT3(0x1<<3)
static int a;
void set_bit3(void)
{
a|=BIT3;
}
void clear_bit3(void)
{
a &=~BIT3;
}
嵌入式系统经常具有要求程序员去访问某特定的内存位置的特点。在某工程中,要求设置一绝对地址为0x67a9的整型变量的值为0xaa66。编译器是一个纯粹的ANSI编译器。写代码去完成这一任务。
int *ptr;
ptr=(int * )0x67a9;
*ptr=0xaa66;
中断是嵌入式系统中重要的组成部分,这导致了很多编译开发商提供一种扩展--让标准C支持中断。其代表事实是,产生了了一个新的_interrupt.下面的代码就使用了_interrupt关键字去定义了一个中断服务子程序(ISR),请评价下这段代码.
_interrupt double compute_area(double radius)
{
}
这个函数有太多的错误了
1)ISR不能返回一个值。
2)ISR不能传递参数。
3)在许多的处理器/编译器,浮点一般都是不可重入的。有些处理器/编译器需要让额外的寄存器入栈,有些处理器/编译器就是不允许在ISR中做浮点运算。此外,ISR应该是短而有效率的,在ISR中做浮点运算是不明智的。
4)与第三点一脉相承,printf()经常有重入和性能上的问题。
下面的代码输出是什么,为什么?
void foo(void)
{
}
这无符号整型问题的答案是输出是">6"。原因是当表达式中存在有符号类型和无符号类型时所有的操作都自动转换为无符号类型。因为-20变成了一个非常大的正整数,所有该表达式计算出的结果大于6。这一点对于频繁用到无符号数据类型的嵌入式系统是非常重要的。
C语言同意一些令人震惊的结构,下面的结构是合法的吗。如果是,它做些什么?
int a=5,b=7,c;
c=a+++b;
//a=6;b=7;c=12;
这是个关于代码的可读性,代码的可修改性的好的话题。
字符指针变量与字符数组的区别
字符数组由若干元素组成,每个元素存放一个字符,而字符指针变量只存放字符串的首地址,不是整个字符串。
char *str[14];
str="i love c!";此时赋给str的不是字符,而是字符串首地址。
static char *name[]={"li jing","wangji","hongjiujing"};不要以为数组中存放的是字符串,它存放的是字符串首地址。
ANSI新增了一种void*指针类型,即定义一个指针变量,但不指向任何数据类型,等用到的时候再强制转换类型。
如:
char *p1;
void *p2;
p1=(char *)p2;
也可以将一个函数定义成void *型:
如:void *func(ch1,ch2)
表示函数fun返回一个地址,它指向空类型,如果需要用到此地址,可以使用强制转换,如(假设p1为char型);
p1=(char *)fun(c1,c2);
&按位与 |按位或
&对于将一个单元清零,取一个数中的某些指定位以及保留指定位有很大用途。
|常被用来将一个数的某些位置1。^判断两个位值,不同为1,相同为0。常用来使特定位翻转等。
~常用来配置配合其它位运算符使用的,常用来设置屏蔽字。<<将一个数的各二进制位全部位移,高位左移后溢出,舍弃不起作用。左移一位相当于该数乘2,左移n位相当于乘2n。左移比乘法运算要快的多。
>>右称移时,要注意符号问题,对无符号数,右移时左边高位移位0,对于有符号数,如果原来符号位为0(正数);则左边移入0;如果符号位为1(负数),则左边移入0还是1要取决于系统。移入0称为逻辑右移,移入1称为算数右移。
位段
将一个字符分为几段存放几个信息。所谓位段是以位为单位定义长度的结构体类型中的成员。如:
struct packed-data{
unsigned a:2;
unsigned b:6;
unsigned c:4;
unsigned d:4;
int l;
}data;
其中a,b,c,d分别占2位,6位,4位,4位。l为整数,占4个字节。对于位段成员的引用如下:
data.a=2;等,但要注意赋值时,不要超出位段定义的范围。如位段成员a定义为2位,最大值为3,即(11)2,所以data.a=5;就会取5的两个低位进行赋值,就得不到想要的值了。
关于位段的定义和引用,有几点重要说明:
1、若某一个段要从另一个字开始存放,可以定义:
unsigned a:1;
unsigned b:2;
unsigned :0;
unsigned c:3;(另一单位)
使用长度为0的位段,作用就是使下一个位段从下一个存储单元开始存放。
2一个位段必须存放在用一个存储单元中,不能跨两个单元。
3可以定义无名位段。如:
unsigned a:1;
unsigned :2;(这两位空间不用)
unsigned b:3;
4、位段的长度不能大于存储单元的长度,也不能定义位段数组。
变量在没有赋值之前,其值不定的。对于指针变量,可以表述为:指向不明。
程序访问了一个没有初始化的指针:
int* p;
p 的内存是随机的一个数,比如:
0x3FF0073D
程序随即访问内存地址:
0x3FF0073D
0x3FF0073D是哪里的内存?说不定正好是Windows老大要用的内存,你竟敢访问!
Windows一生气,蓝屏。
一个指向不明的指针,是非常危险的!!!
因此,指针在使用前一定要初始化;在使用前一定要确定指针是非空的!!!
(1). 空指针
是个特殊指针值,也是唯一对任何指针类型都合法的指针值。一个指针变量具有
空指针值,表示它当时没指向有意义的东西,处于闲置状态。空指针值用0表
示,这个值绝不会是任何程序对象的地址。给一个指针赋值0就表示要它不指向
任何有意义的东西。为了提高程序的可读性,标准库定义了一个与0等价的符号
常量NULL,程序里可以写:
p = NULL; //注意不要与空字符NUL混淆,NUL等价于‘\0’
或者:
p = 0;
注意:
在编程时,应该将处于闲置的指针赋为空指针;
在调用指针前一定要判断是否为空指针,只有在非空情况下才能调用。
函数指针即指向函数地址的指针。利用该指针可以知道函数在内在中的位置。因为也可以利用函数指针调用函数。
注意:int *func(void)和int (*func)(void)的区别
int*func(void)//这是返回一个整型指针的函数
不能将普通变量的地址赋给函数指针,不能将函数的调用赋给函数指针
函数指针的用途:一旦函数可以通过指针被传递、被记录,这开启了许多应用,特别是下列三者:
1多态(polymorphism):指用一个名字定义不同的函数,这函数执行不同但又类似的操作,从而实现“一个接口,多种方法”。
2、多线程:将函数指针传进负责建立多线程的API中:例如win32的CreateThread(...pF...)。
3。回调:所谓的回调机制就是:当发生某事件时,自动呼叫某段程序代码。事件驱动的系统经常透过函数指针来实现回调机制,例如Win32的WinProc其实就是一种回调,用来处理窗口听讯息。
函数指针数组:
double add(double,double);
double sub(double,double);
double (*open_func[ ](double,double)={add,sub,...};
第2个步骤是用下面语句替换前面整条switch语句:
result=oper_func[oper](op1,op2);
oper从数组中选择正确的函数指针,而函数调用操作符将执行这个函数。
ASIX Window中的函数指针
typedef struct window_class
{
U8 wndclass_id;
STATUS (*create)(char *caption, U32 style, U16 x, U16 y, U16width,
U16 hight, U32 wndid, U32 menu, void **ctrl_str, void*exdata);
STATUS (*destroy)(void *ctrl_str);
STATUS (*msg_proc)( U32 win_id, U16 asix_msg, U32 lparam,void
*data, U16 wparam, void *reserved);
STATUS (*msg_trans)(void *ctrl_str, U16 msg_type, U32 areaId,
P_U16 data, U32 size, PMSG trans_msg);
STATUS (*repaint)(void *ctrl_str, U32 lparam);
STATUS (*move)(void *ctrl_str, U16 x, U16 y, U16 width, U16hight,
void *reserved);
STATUS (*enable)(void *ctrl_str, U8 enable);
STATUS (*caption)(void *ctrl_str, char *caption, void*exdata);
STATUS (*information)(void *ctrl_str, struct asix_window*wndinfo);
} WNDCLASS;
WNDCLASS WindowClass[] = {
{WNDCLASS_WIN, wn_create, wn_destroy, wn_msgproc,wn_msgtrans,wn_repaint, NULL,NULL,wn_caption, NULL},
{WNDCLASS_BUTTON,Btn_create,Btn_destroy,Btn_msg_proc,Btn_msg_trans,Btn_repaint,NULL,Btn_enable,Btn_caption,
NULL},
{WNDCLASS_SELECT,sl_create, sl_destroy, sl_msg_proc, sl_msg_trans,sl_repaint,NULL, sl_enable, sl_caption, NULL},
{WNDCLASS_SELECTCARD,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL},
{WNDCLASS_MENU,menu_create, menu_destroy, menu_msgproc,menu_msgtrans, mn_repaint, NULL, NULL,NULL,NULL},
{WNDCLASS_LIST, Lbox_create, Lbox_destroy, Lbox_msgproc,Lbox_msgtrans, lb_repaint, NULL, NULL,NULL,NULL},
{WNDCLASS_KEYBD, kbd_create,kbd_destroy, kbd_msgproc, kbd_msgtrans,kbd_repaint, NULL, NULL,NULL,NULL},
{WNDCLASS_SCROLL,sb_create, sb_destroy, sb_msgproc, sb_msgtrans,sb_repaint, NULL,sb_enable, NULL,NULL},
{WNDCLASS_KEYBAR,kb_create, kb_destroy, kb_msgproc,kb_msgtrans,NULL,NULL, NULL,NULL, NULL},
#ifdef ASIX_DEBUG
{WNDCLASS_TEST,tst_create, tst_destroy, tst_msgproc, tst_msgtrans,NULL,NULL,NULL,NULL,NULL}
#endif
};
1 结构体
结构是由若干(可不同类型的)数据项组合而成的复合数据对象,这些数据
项称为结构的成分或成员。
(1) 字段
C语言的结构还提供了一种定义字段的机制,使人在需要时能把几个结构成
员压缩到一个基本数据类型成员里存放,这可以看作是一种数据压缩表示方
式。
例16: struct pack {
unsigned a:2;
unsigned b:8;
unsigned c:6;
} pk1, pk2;
结构变量pk1或者pk2的三个成员将总共占用16位存储,其中a占用2位,b占
用8 位,c占用6 位。
(2)结构体内部的成员的对齐
在计算结构体长度(尤其是用sizeof)时,需要注意!
根据不同的编译器和处理器,结构体内部的成员有不同的对齐方式,这
会引起结构体长度的不确定性。
例17:
#include <stdio.h>
struct a{ char a1; char a2; char a3; }A;
struct b{ short a2; char a1; }B;
void main(void)
{
printf(“%d,%d,%d,%d”, sizeof(char), sizeof(short), sizeof(A),sizeof(B));
}
在Turbo C 2.0中结果都是
1,2,3,3
在VC6.0中是
1,2,3,4
www.cnasic.com
字节对齐的细节和编译器实现相关,但一般而言,满足三个准则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2)结构体每个成员相对于结构首地址的偏移量(offset)都是成员大小的整数
倍,
如有需要编译器会在成员之间加上填充字节(internal adding);
3)结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会
在最末一个成员之后加上填充字节(trailing padding)。
对于上面的准则,有几点需要说明:
1)结构体某个成员相对于结构体首地址的偏移量可以通过宏offsetof()来获得,这
个宏也在stddef.h中定义,如下:
#define offsetof(s,m) (size_t)&(((s *)0)->m)
2)基本类型是指前面提到的像char、short、int、float、double这样的内置数据类型,这里所说的“数据宽度”就是指其sizeof的大小。由于结构体的成员可以是复合类型,比如另外一个结构体,所以在寻找最宽基本类型成员时,应当包括复合
类型成员的子成员,而不是把复合成员看成是一个整体。但在确定复合类型成员
的偏移位置时则是将复合类型作为整体看待。
2 联合体
在一个结构(变量)里,结构的各成员顺序排列存储,每个成员都有自
己独立的存储位置。联合变量的所有成员共享从同一片存储区。因此一个联
合变量在每个时刻里只能保存它的某一个成员的值。
(1)联合变量的初始化
联合变量也在可以定义时直接进行初始化,但这个初始化只能对第一个成员
做。例如下面的描述定义了一个联合变量,并进行了初始化:
例18:
union data
{
char n;
float f;
};
union data u1 = {3}; //只有u1.n被初始化
3 枚举
枚举是一种用于定义一组命名常量的机制,以这种方式定义的常量一般称为
枚举常量。
一个枚举说明不但引进了一组常量名,同时也为每个常量确定了一个整数值。
缺省情况下其第一个常量自动给值0,随后的常量值顺序递增。
(1)给枚举常量指定特定值
与给变量指定初始值的形式类似。如果给某个枚举量指定了值,跟随其后的
没有指定值的枚举常量也将跟着顺序递增取值,直到下一个有指定值的常量为止。
例如写出下面枚举说明:
enum color {RED = 1, GREEN, BLUE, WHITE = 11, GREY, BLACK=15};
这时,RED、GREEN,、BLUE 的值将分别是1、2、3,WHITE、GREY的值
将分别是11、12,而BLACK 的值是15。
(2)用枚举常量作为数组长度
例19:
typedef enum{WHITE, RED, BLUE, YELLOW, BLACK, COLOR_NUM
}COLOR;
… …
float BallSize[COLOR_NUM];
上例中当颜色数量发生变化时,只需在枚举类型定义中加入或删去颜色。
无需修改COLOR_NUM的定义。与大量使用#define相比既简洁又可靠。如:
typedef enum{ WHITE, RED, BLUE,COLOR_NUM }COLOR;
4 sizeof的定义和使用
sizeof是C/C++中的一个操作符(注意!不是函数!就像return一样)。
其作用就是返回一个对象或者类型所占的内存字节数。
sizeof有三种使用形式,如下:
1) sizeof(var); // sizeof( 变量);
2) sizeof(type_name); // sizeof( 类型);
3) sizeof var; // sizeof 变量;
所以,
int i;
sizeof(i); // ok
sizeof i; // ok
sizeof(int); // ok
sizeof int; // error
为求形式统一,不建议采用第3种写法,忘掉它吧!
数组的sizeof
数组的sizeof值等于数组所占用的内存字节数,如:
例21:char* ss = "0123456789";
sizeof(ss); // 结果4 , ss是指向字符串常量的字符指针
sizeof(*ss); // 结果1 ,*ss是第一个字符
char ss[] = "0123456789";
sizeof(ss); // 结果11 , 计算到‘\0’位置,因此是10+1
sizeof(*ss); // 结果1 , *ss是第一个字符
char ss[100] = "0123456789";
sizeof(ss); // 结果100 , 表示在内存中的大小100×1
strlen(ss); // 结果10 , strlen是到‘\0’为止之前的长度
int ss[100] = "0123456789";
sizeof(ss); //结果200 , ss表示在内存中的大小100×2
strlen(ss); //错误,strlen的参数只能是char*且必须以‘\0’结尾
数组和指针
char *f1(void)
{
}
char *f1(void)
{
}
main()
{
}
Trackback:
冒泡排序
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









