







 本文记录了使用MapReduce实现文章中高频单词TopN的过程,包括遇到的两个问题及解决办法。首先,通过MapReduce进行词频统计,然后在第二阶段处理中,通过自定义JavaBean和Mapper、Reducer解决数据覆盖问题,最终得到TopN结果。问题一是缺少JavaBean的空参构造导致运行失败;问题二是Reducer阶段因对象重用导致数据覆盖,通过每次创建新对象解决。
本文记录了使用MapReduce实现文章中高频单词TopN的过程,包括遇到的两个问题及解决办法。首先,通过MapReduce进行词频统计,然后在第二阶段处理中,通过自定义JavaBean和Mapper、Reducer解决数据覆盖问题,最终得到TopN结果。问题一是缺少JavaBean的空参构造导致运行失败;问题二是Reducer阶段因对象重用导致数据覆盖,通过每次创建新对象解决。
mapreduce-3
网上看到的topn实现需求,想用MapReduce实现下,在实现过程中,踩了两个坑,所以记录下来补充之前没提到的细节
需求:求一篇文章中出现的高频单词topn
数据源:
Since childhood, Mr. Lu Xun in his desk now on a "morning", this style started to affect the students of history, several generations of renewal and transformation, we have become on the desks of the "culture" A.
"Desks culture" is widespread in the class took to the ring, you can see a wide range of potential "authentic work culture."
A desk: "Nicholas Tse," as long as you live for the day "." Obviously, the desk is a master of popular songs like the people. He must love Nicholas Tse, whether he liked the song or like him. Have their own favorite idols, of course, not a bad thing, the idol of the songs and names written on desks, every day, of course, be able to see the show, "Iron". Starchaser but it's too old-fashioned way, and no content, and their "culture desk" is not associated with, so I go under a desk.
B desks: "listen carefully to class, do not speak so small." Hey, this sentence is so well written. This is not with Mr. Lu Xun was the same as you? The desk is definitely the master of small talk in class if the class has been severely criticized seize the meal, so they decided to "truly repentant" and determined to do after the speech, but Guanbu Zhu afraid of their own, so the desk So wrote a memorable quotation, a moment to remind ourselves. This is the master of that determination and I really admire. From this, but I can not see what the phrase "culture", and I continue to move forward to explore the line of sight.
C desks: "They told me how this, I do not live!" Wow! Such words are written out. Desks so that the owner is a good place to vent! It feels aggrieved after the owner of this table is not how to fight a few, or simply removed up to the table. Now the young people really terrible, what Dugan wrote to the above. Even if this is really the masters of the wronged, and should not be a non-live it. Oh, do not know if this is still the master of desks dead. I have this to the table, three Ju bow, then went to a school desks to find the real "culture desks."
Ding desks: "going its own way, others say go!" This is what I find the "culture of desks?" This sentence with the front desk to write a few words compared to what is different? In front of the mortals who are made, and this is a famous celebrity? Perhaps the author of this text in graffiti, yet they have been discouraged, and he openly just "go its own way", which control how other people say that? This front than there is on the table of contents of the "culture" do more?
Go back to their seats around, I am still pondering: What kind of writing truly the "culture desk"?
Appears to be accurate and can not find the answer. I slumped to sit down and suddenly found table goes Journey Into Amazing Caves: - literary, cultured, civilized; - painting, draw, then. Look no art, but at least tell me if Buwen Ya, uncivilized, no matter how painting, how draw, what can not be called "culture."
I understood why.
实现思路:采用比较简单的方式,分两段实现,第一段进行wordcount,统计出每个单词出现次数,第二阶段,在第一阶段的基础上读取数据,根据频率倒序排列,然后输出前N个;
第一阶段代码实现(忽略我随意取的名字):
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] mes = value.toString().split("[ |\t|,|\\.|-|-|?|\"]");
for (String str : mes) {
if (!"".equals(str)){
context.write(new Text(str), new LongWritable(1));
}
}
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int cnt = 0;
for (LongWritable value : values) {
cnt++;
}
context.write(key, new LongWritable(cnt));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class MostCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration(), "times");
job.setJarByClass(MostCount.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("D:\\file\\project\\hadoop\\mapreduce\\data\\1.txt"));
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("output/"));
boolean result = job.waitForCompletion(true);
System.out.println(result?"运行成功":"运行失败");
}
}
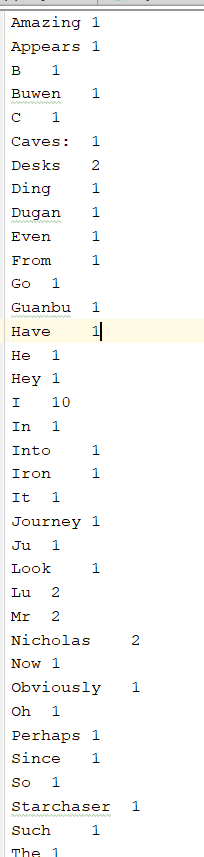
查看输出结果:
接下来是第二个阶段的代码实现(问题全部出现在这个阶段):
第二阶段的实现思路:使用TextInputFormat读取每行数据,此时一行数据就是使用Tab分隔的单词和出现次数(过滤掉最后一个空行),然后将这两个数据封装到JavaBean中,作为Map阶段的Value输出,而输出的Key可以选择使用任意类型的同一个值输出,或者自定义分区规则将所有值分到一个区中,两种做法都是为了一个目的:将所有单词汇总到一个分区,然后进行接下来的排序操作,当然,这里如果自定义了分区规则就可以实现每个分区内求取topn的效果,这里就选择第一种方式,全部定义为IntWritable类型的数值1
接下来定义一个JavaBean
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TimeBean implements Writable {
private String word;
private long time;
public TimeBean() {
}
public TimeBean(String word, long time) {
this.word = word;
this.time = time;
}
@Override
public String toString() {
return word + ":" + time;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
out.writeLong(time);
}
@Override
public void readFields(DataInput in) throws IOException {
this.word=in.readUTF();
this.time=in.readLong();
}
}
这里是踩的第一坑:没有定义空参构造,结果就是:
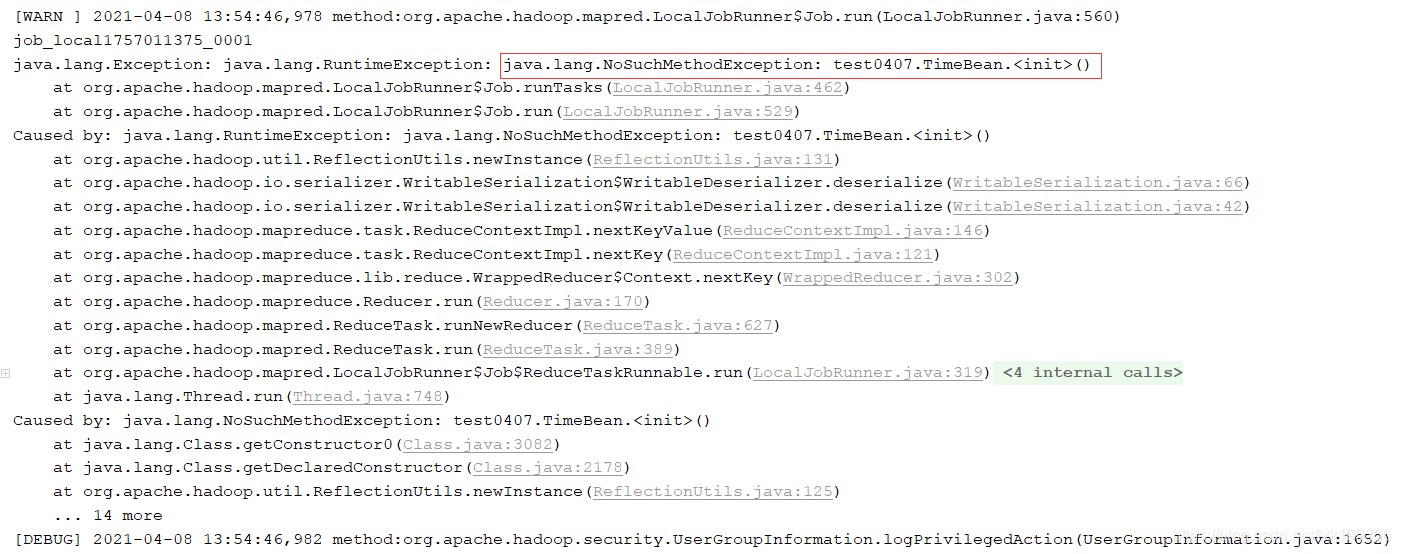
这里的报错原因是在mapreduce运行阶段,会使用反射机制调取输入输出类型的空参构造,而我重写了带参构造,没有了默认的空参构造就会运行失败
接下来是map和reduce阶段代码实现:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MostMapper extends Mapper<LongWritable, Text, IntWritable, TimeBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] mes = value.toString().split("\t");
TimeBean timeBean = new TimeBean();
timeBean.setWord(mes[0]);
timeBean.setTime(Long.parseLong(mes[1]));
context.write(new IntWritable(1), timeBean);
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.*;
public class MostReducer extends Reducer<IntWritable, TimeBean, Text, LongWritable> {
@Override
protected void reduce(IntWritable key, Iterable<TimeBean> values, Context context) throws IOException, InterruptedException {
List<TimeBean> list=new ArrayList<>();
int index = 0;
Iterator<TimeBean> iter = values.iterator();
while (iter.hasNext()) {
TimeBean bean = iter.next();
//System.out.println(iter);
//System.out.println(bean);
list.add(bean);
//System.out.println(list);
}
list.sort(new Comparator<TimeBean>() {
@Override
public int compare(TimeBean o1, TimeBean o2) {
return (int) (o2.getTime() - o1.getTime());
}
});
for (int i = 0; i < 5; i++) {
TimeBean bean = list.get(i);
context.write(new Text(bean.getWord()), new LongWritable(bean.getTime()));
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Most10 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration(), "top10");
job.setJarByClass(Most10.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("D:\\file\\project\\hadoop\\mapreduce\\output\\part-r-00000"));
job.setMapperClass(MostMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(TimeBean.class);
job.setReducerClass(MostReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("outFinal/"));
boolean result = job.waitForCompletion(true);
System.out.println(result ? "运行成功" : "运行失败");
}
}
这个阶段遇到了第二个坑:虽然能运行成功,但是最后输出文件中只有一个单词重复指定的次数,可以打开reduce阶段输出语句的注释,看到过程中输出的结果:
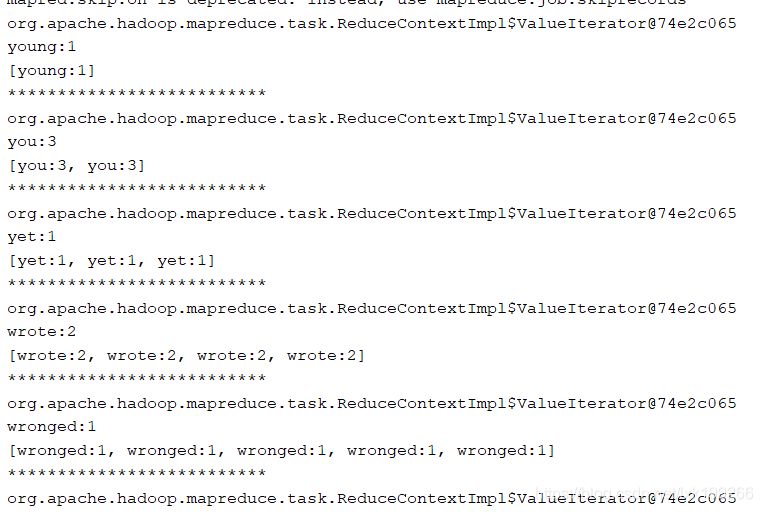
可以看到输出的迭代器对象的地址是统一的,说明成功将所有数据分到了一个分区内,再接下来可以看到每行的数据也可以顺利读取到,但是当数据添加到集合中后,问题就出现了,虽然集合长度会随着添加数据增加,但是同时前面添加的数据也会被覆盖掉,这也就解释了为什么最终输出只有一个单词,因为最终集合中就只有一种类型的对象;
出现这个问题的原因就是reduce阶段的对象重用机制,即每次迭代会使用同一个对象去接收数据,而记录在集合中的数据又是这个对象的地址,当下个数据被接收,集合中对应地址保存的数据发生了变化,所以就会发生上面的情况。明白了原因,解决方案也就简单了:每次创建不同的对象添加到集合中
修改后的reduce阶段代码:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.*;
public class MostReducer extends Reducer<IntWritable, TimeBean, Text, LongWritable> {
@Override
protected void reduce(IntWritable key, Iterable<TimeBean> values, Context context) throws IOException, InterruptedException {
List<TimeBean> list=new ArrayList<>();
int index = 0;
Iterator<TimeBean> iter = values.iterator();
while (iter.hasNext()) {
TimeBean bean = iter.next();
TimeBean b=new TimeBean();
b.setWord(bean.getWord());
b.setTime(bean.getTime());
list.add(b);
}
list.sort(new Comparator<TimeBean>() {
@Override
public int compare(TimeBean o1, TimeBean o2) {
return (int) (o2.getTime() - o1.getTime());
}
});
for (int i = 0; i < 5; i++) {
TimeBean bean = list.get(i);
context.write(new Text(bean.getWord()), new LongWritable(bean.getTime()));
}
}
}
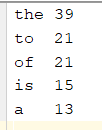
只要修改reduce阶段写出次数,即可控制n值,最终结果:
上面代码还存在另一个问题,即最终全部的数据要汇总到一个reduce,并且进行排序,如果数据量大时效率将会低,可以采用的解决方案:使用combiner提前聚合,求取topn就在每个map阶段聚合到只保留n个的程度(防止topn出现在同一个Map中的极端情况),最终聚合到reduce上的数据条数就会是n*分区数

















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









