




 本文深入探讨了推荐系统中常用的几种相似度计算方法,包括曼哈顿距离、欧几里得距离、闵可夫斯基距离、皮尔逊相关系数及余弦相似度,并分析了它们在不同数据条件下的应用优势。
本文深入探讨了推荐系统中常用的几种相似度计算方法,包括曼哈顿距离、欧几里得距离、闵可夫斯基距离、皮尔逊相关系数及余弦相似度,并分析了它们在不同数据条件下的应用优势。
《Dataminingguide》书阅读,第二章 推荐系统入门
1、 曼哈顿距离
最简单的距离计算方式。在二维计算模型中,每个人都可以用(X,Y)的点来表示。例如(X1,Y1)来表示艾米,(X2,Y2)来表示另一位人,那么他们之间的曼哈顿距离就是:
|X1-X2|+|Y1-Y2|
也就是x之差的绝对值加上y之差的绝对值。
曼哈顿距离的优点之一就是计算速度快,对于Facebook这样需要计算百万用户之间的相似度时就非常有利。
2、 欧几里得距离
还是用(X,Y)来表示一个人,那么两个人之间的距离就是:
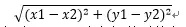
在计算两个用户之间的相似度距离时,只取双方都评价过的商品。
曼哈顿距离和欧几里得距离在 数据完整 的情况下效果最好。
3、闵克夫斯基距离
可以将曼哈顿距离和欧几里得距离归纳成一个公式,这个公式称为闵可夫斯基距离:

R值越大,单个维度的差值大小会对整体距离有更大的影响。
4、 皮尔逊相关系数
分数膨胀:例如用户对乐队的评分,可以发现每个用户的打分标准非常不同,A的4分相当于B的4分还是5分?
解决方法之一就是使用皮尔逊相关系数。
皮尔森相关系数用于衡量两个变量之间的相关性,它的值在-1到1之间,1表示完全吻合,-1表示完全相悖。
皮尔逊相关系数的计算公式是:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









