




文章目录
前言
- 复习方便,直接截图,敬请见谅
- 转自<<大话数据结构>>
概述


- 树的根节点必定唯一
- 子树个数没有限制,且一定互不相交(若存在相交的子树——》不是树)
- 一对一的线性结构——》一对多的数据结构,比如树
- 线性结构与树结构比较

树节点概念
- 树节点包含一个数据元素及若干指向其子树的分支
- 节点的度:节点拥有的子树数(度为0,则叶节点,反之,度不为0,则分支节点【也称为内部节点】)
- 树的度:各节点的度的max
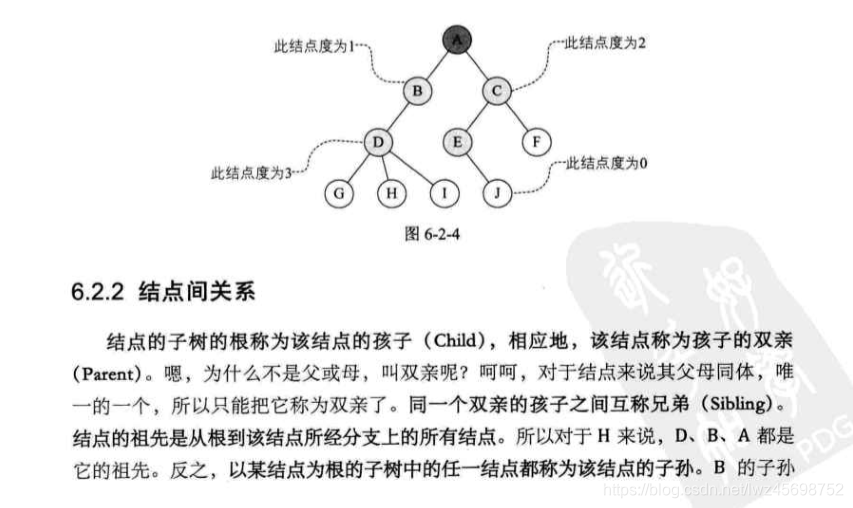
- 节点层次及深度和高度,有序树,无序树,森林
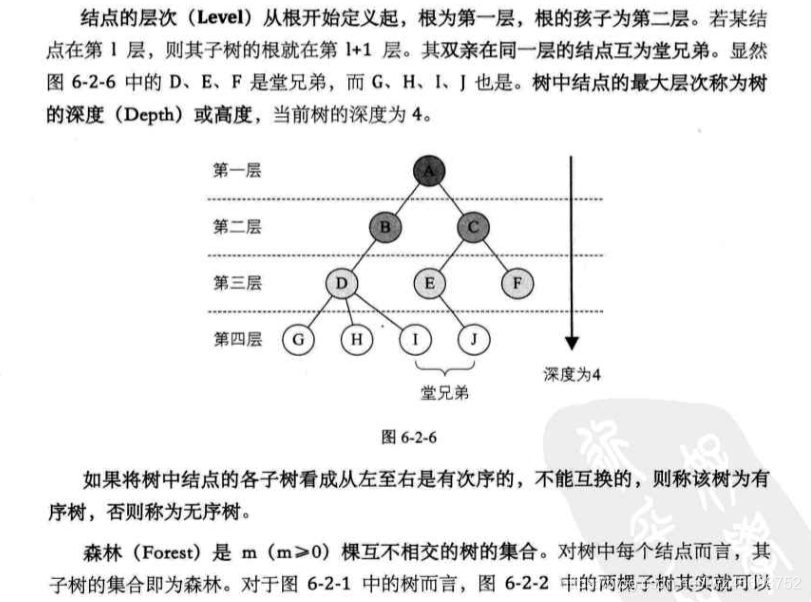
树的存储结构

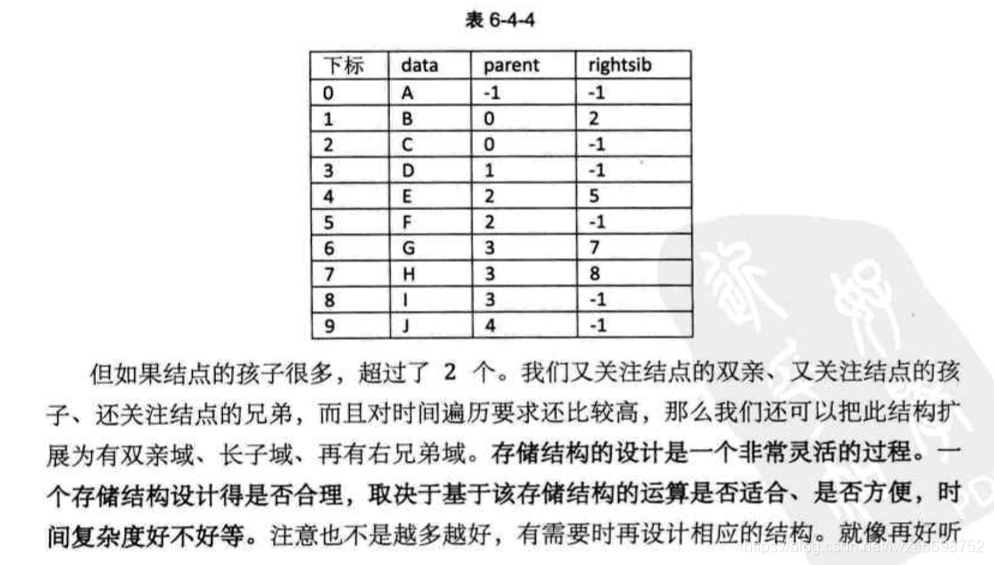
双亲表示法
- 结构定义:data+parent

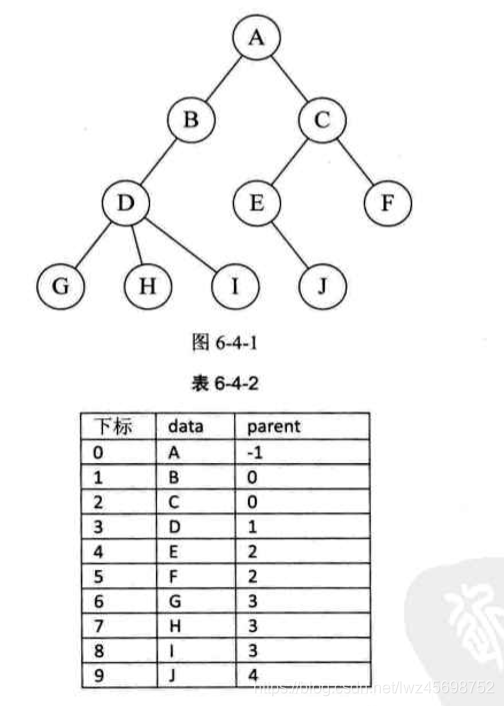 - 约定根节点的位置域设置为-1
- 约定根节点的位置域设置为-1

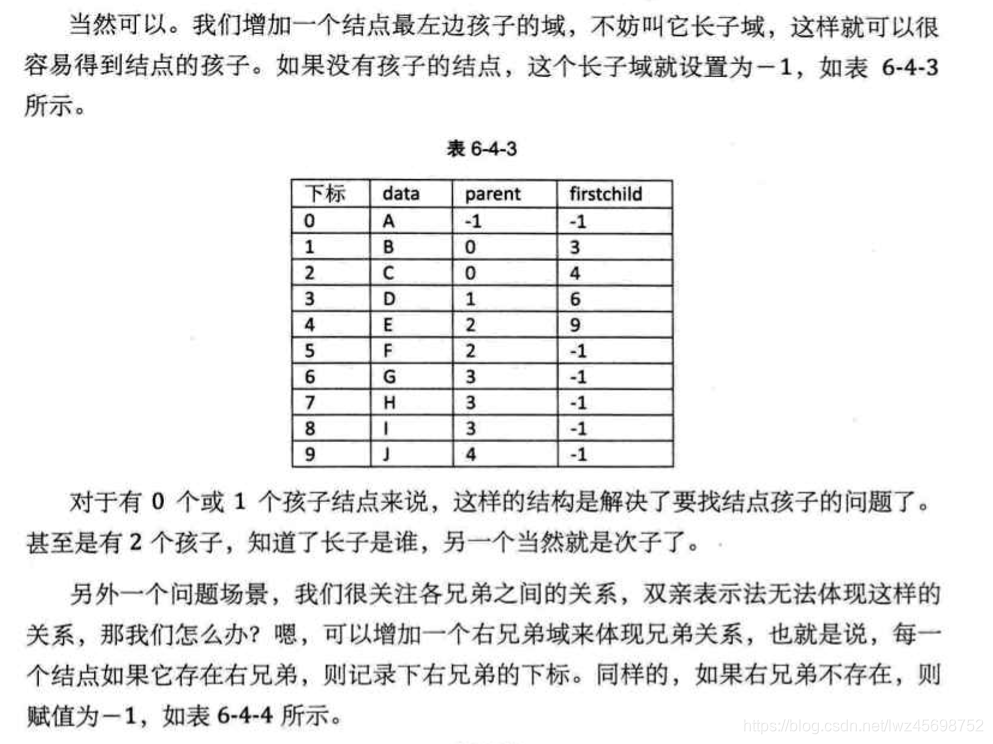
孩子表示法
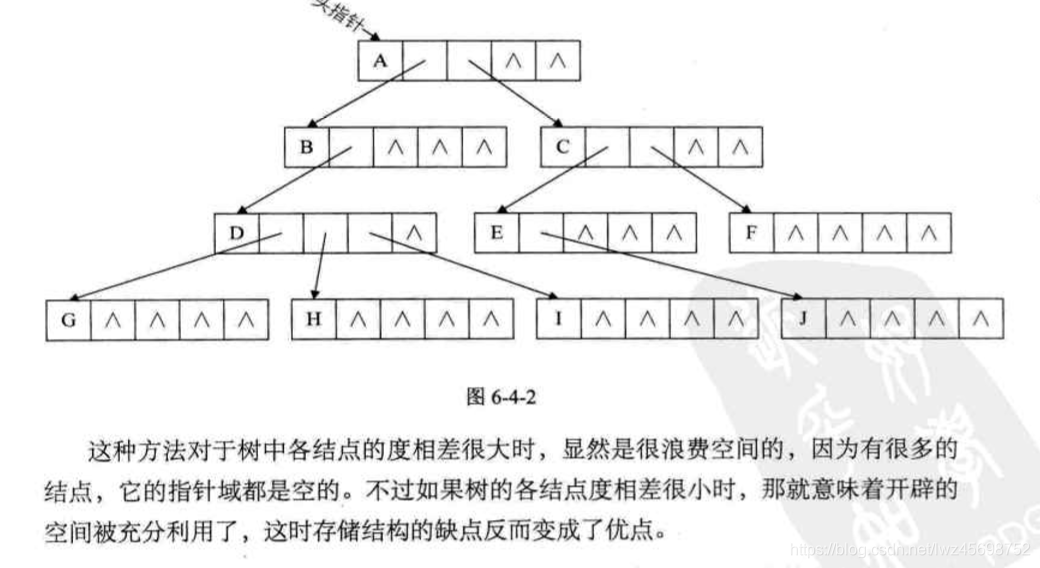
- 多重链表表示法
法1
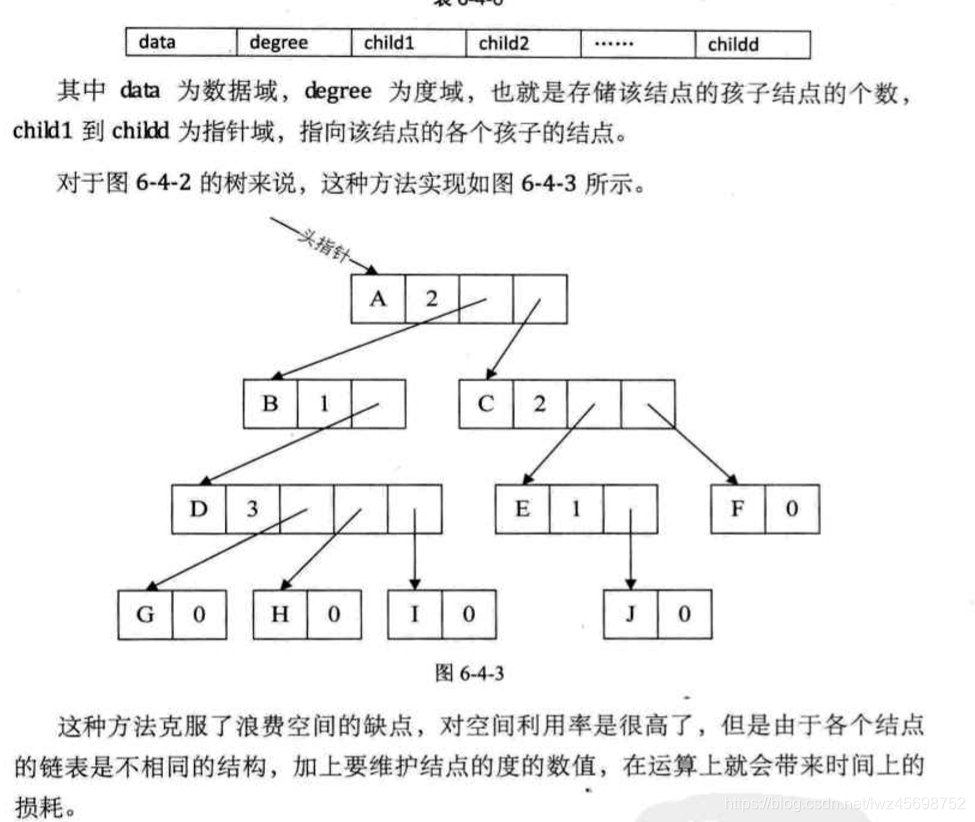
法2
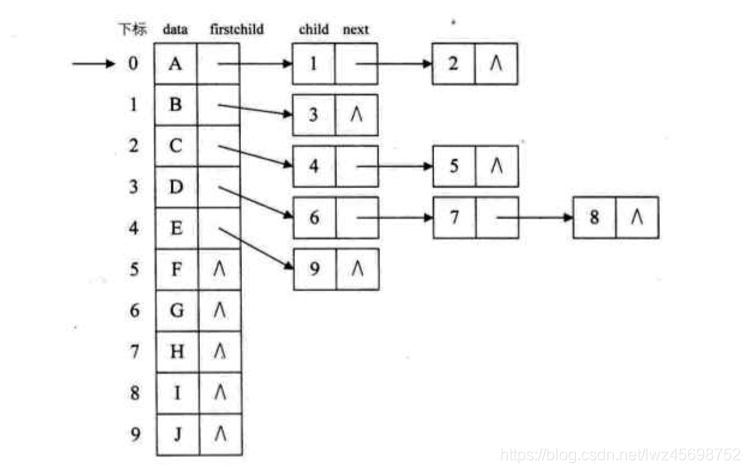
法3


 - 数组元素:树中每个节点,然后每个链表元素是该节点的孩子节点(连接起来了)
- 数组元素:树中每个节点,然后每个链表元素是该节点的孩子节点(连接起来了)
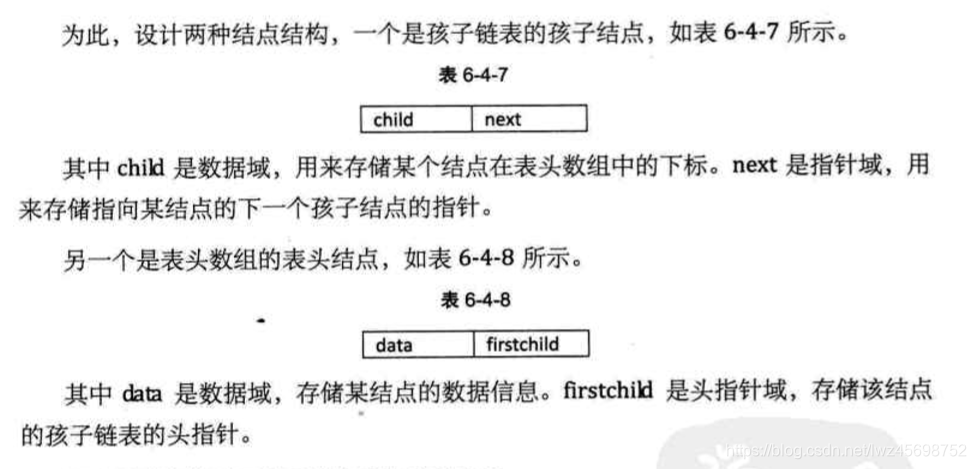
孩子兄弟表示法

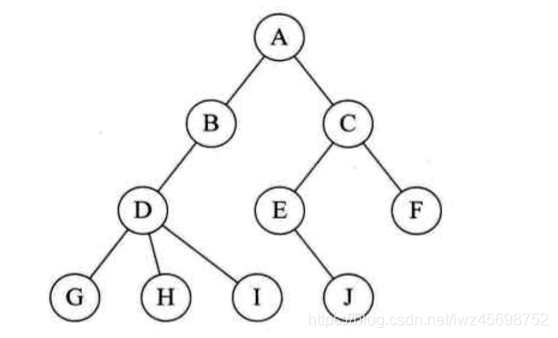
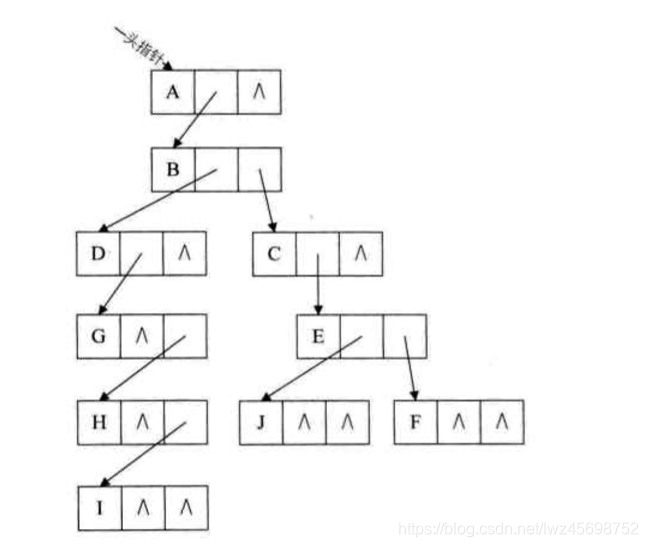
- 采用二叉链表(不同于二叉树的二叉链表)存储
二叉树
- 适合在某阶段都是两种结果的情形(如正反,01)——》利用二叉树建模
概述

特点
- 每个节点最多两个子树——》度<=2
- 左右子树有顺序,顺序树
特殊二叉树
斜树

满二叉树


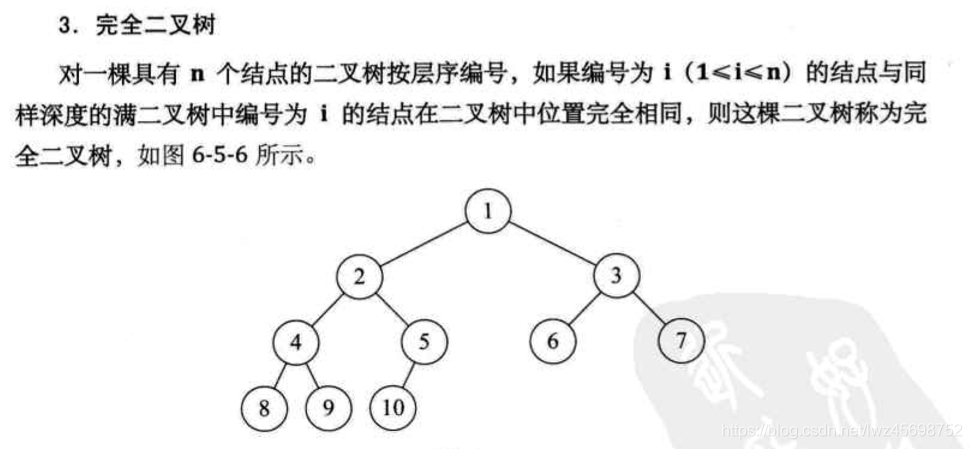
完全二叉树


二叉树性质



- 从1开始编号
二叉树的存储结构
顺序存储结构
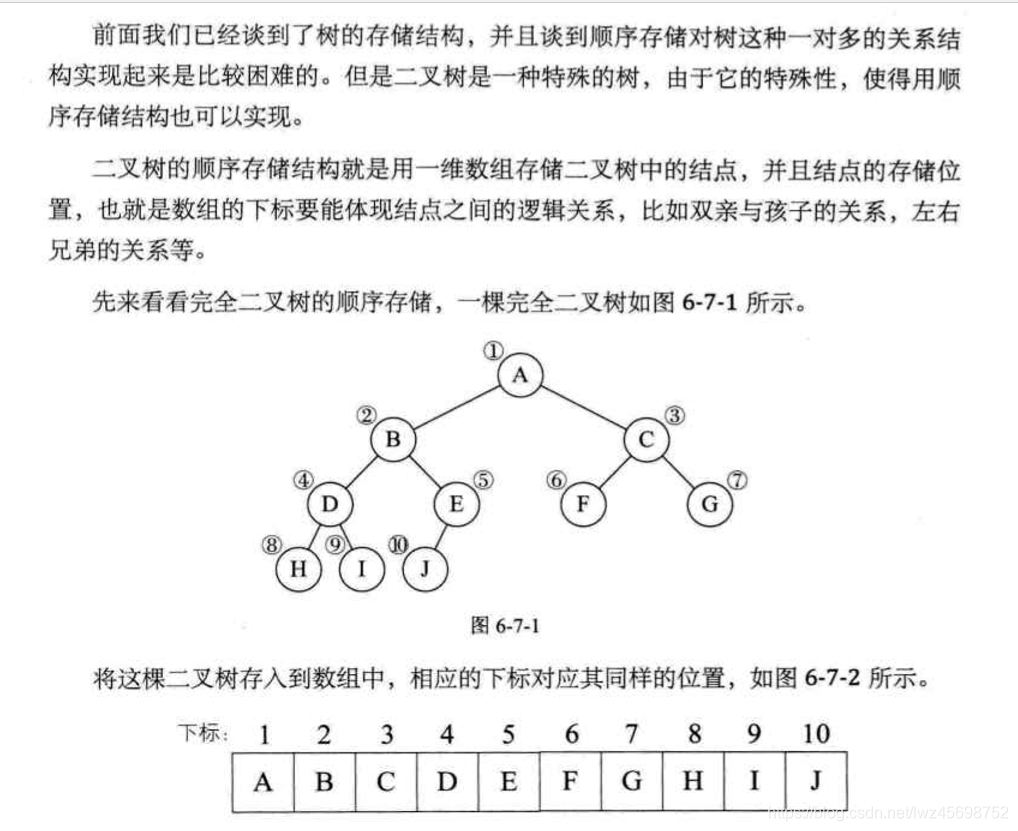

- 适用于完全二叉树
- 一维数组存储
- 按完全二叉树编号,对应编号位置存储元素,若不存在,对应位置为空
- 线性表结构,共需要2^k-1个存储单元空间,却只有k个节点——》浪费
二叉链表存储结构
- 顺序存储结构适用性不强——》链式
- 二叉链表增加指向parent指针——》三叉链表
- 二叉链表如图:

二叉树的遍历

- 访问:根据需要确定具体内容,如打印
- 一般限制了从左到右的习惯方式
- 了解前中后序遍历原理
- 研究树的遍历原因:
- 图形方式表示树的结构,直观
- 但计算机只会处理线性序列
- 遍历将节点变为线性序列
- 不同遍历提供了对节点依次处理的不同方式
前中后遍历/层序遍历
- 若二叉树为空,则空操作返回,否则先根节点,然后前序遍历左子树,然后前序遍历右子树
- 二叉树的定义是用递归方式——》递归实现
知2求1
- 前中/后中——》能确定二叉树
- 已知前后,不能确定二叉树
建立二叉树
- 目标:内存中生成一颗二叉链表的二叉树——》利用递归原理建立(打印节点处改为生成节点,给节点赋值的操作)
- 扩展二叉树:空指针引出一个虚节点
- 扩展二叉树能做到一个遍历序列(无论前中后序)就能确定一颗二叉树
- 区别在于生成节点和构造左右子树的代码顺序
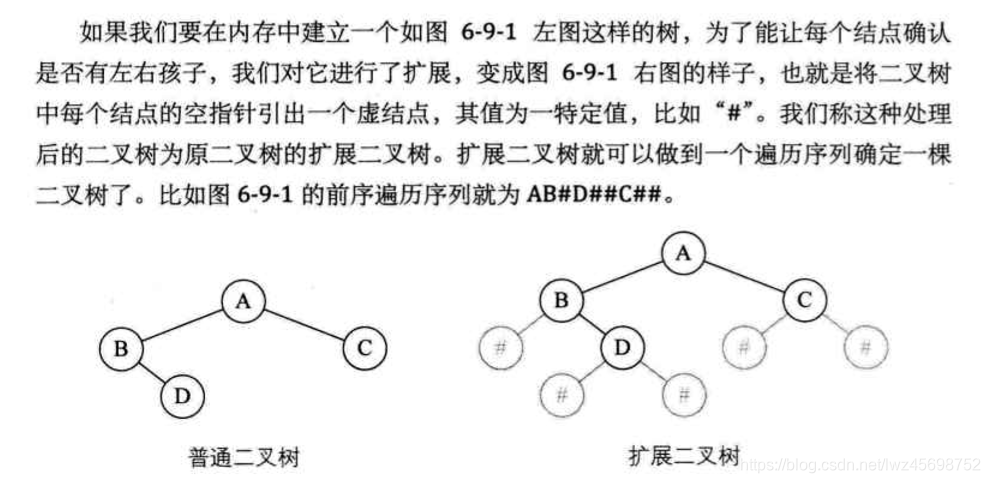
- 区别在于生成节点和构造左右子树的代码顺序
线索二叉树
- 存在某节点的指针域为空——》充分利用指针域——》存放指向节点的前驱或后继结点的地址
- 线索:指向前驱或后继结点的指针
- 所有空指针域的lchild指向前驱节点,rchild指向后继节点
- 总结:线索二叉树相当于把二叉树转化为一个双向链表,方便插入,删除和查找某节点的操作

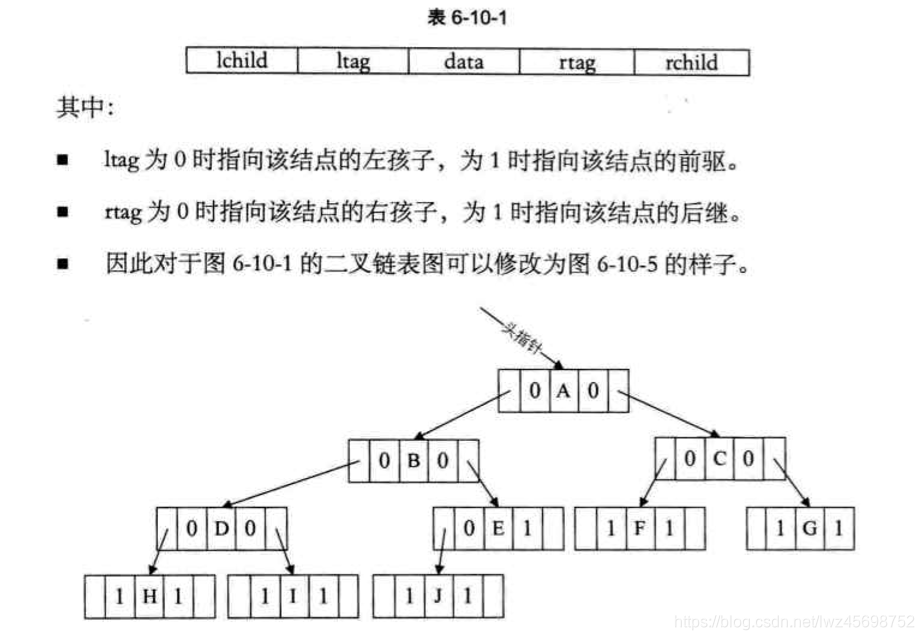
创建线索二叉树
 - 修改空指针的过程
- 修改空指针的过程

 - 遍历线索二叉树,相当于操作一个双向链表结构
- 遍历线索二叉树,相当于操作一个双向链表结构
- 添加一个头节点
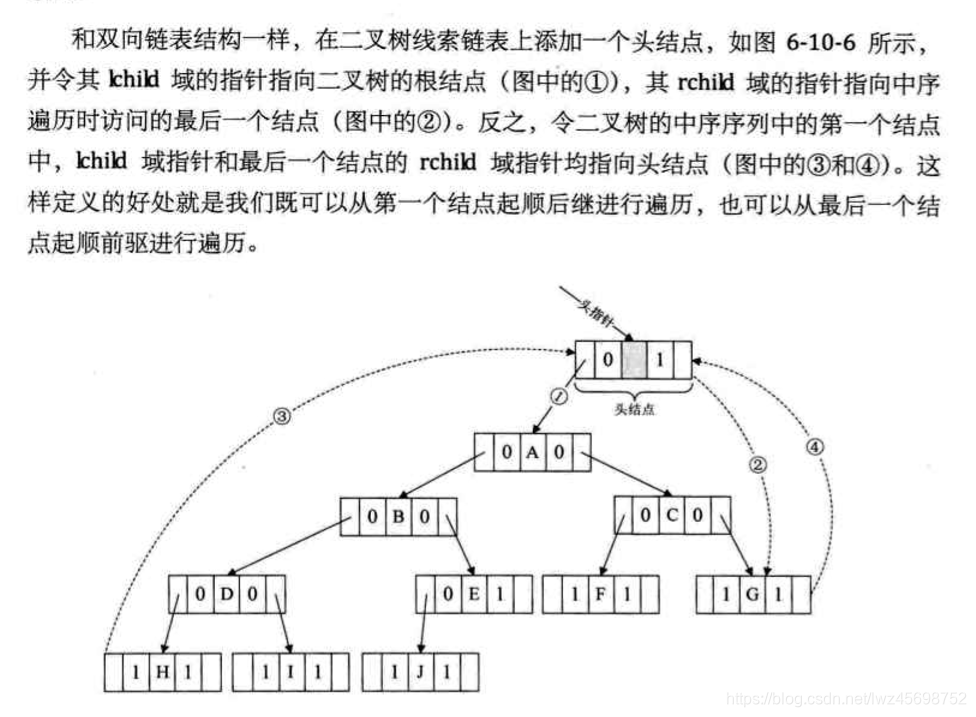
遍历代码
- 略
- 等价于链表的扫描
- 适用于频繁需要前驱和后继信息的场景

树,森林与二叉树

树转换为二叉树
- 后来的节点当右孩子

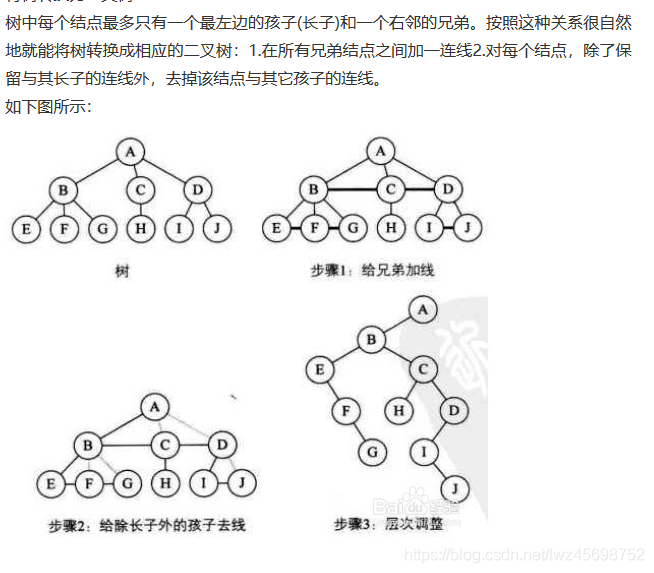
二叉树转换为树
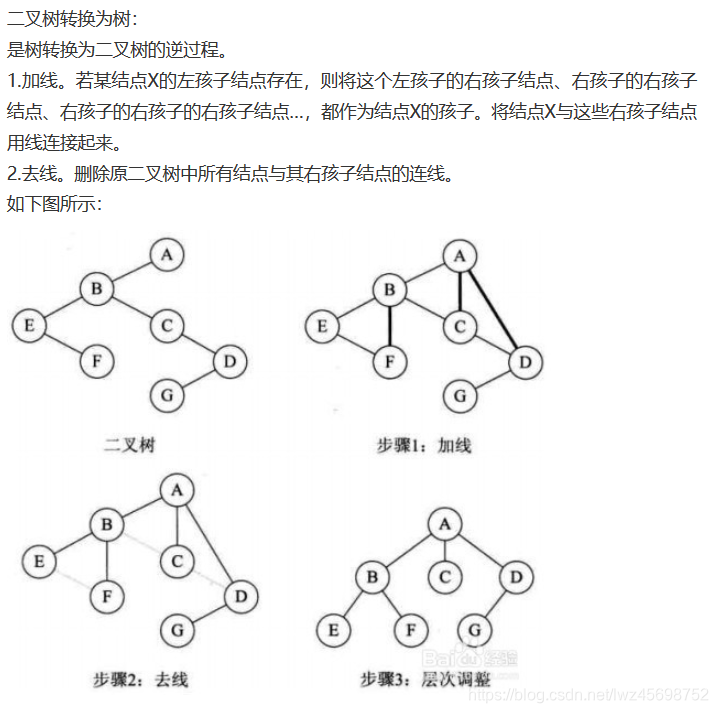
- 各个节点的左孩子的右孩子节点(及右孩子的右孩子。。。)
- 抹线与加线同等数量
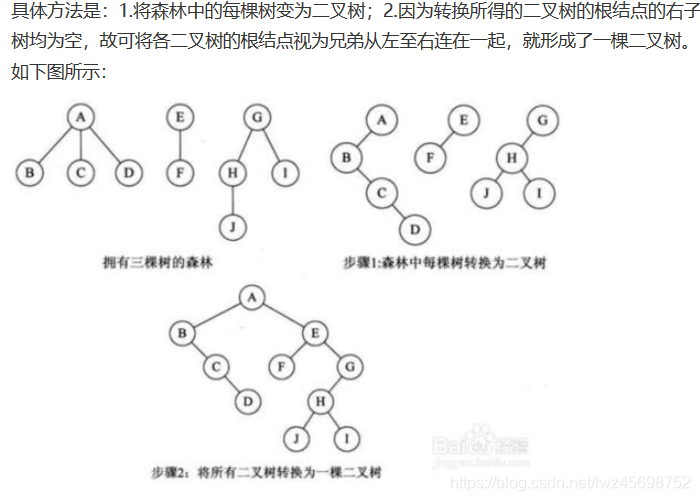
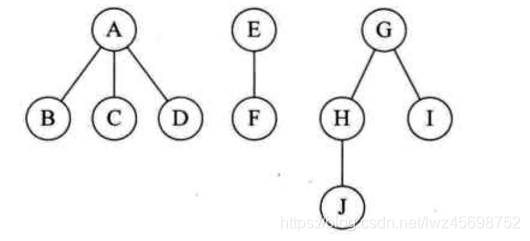
森林转换为二叉树
- 树——》二叉树——》森林(根节点是兄弟)
- 森林——》二叉树——》树

二叉树转换为森林
- 二叉树的根节点有右孩子,则这棵二叉树能够转换为森林,否则将转换为一棵树
-
- 与右孩子及右孩子后代有仇,一刀两断
-
- 每棵二叉树再转化为树
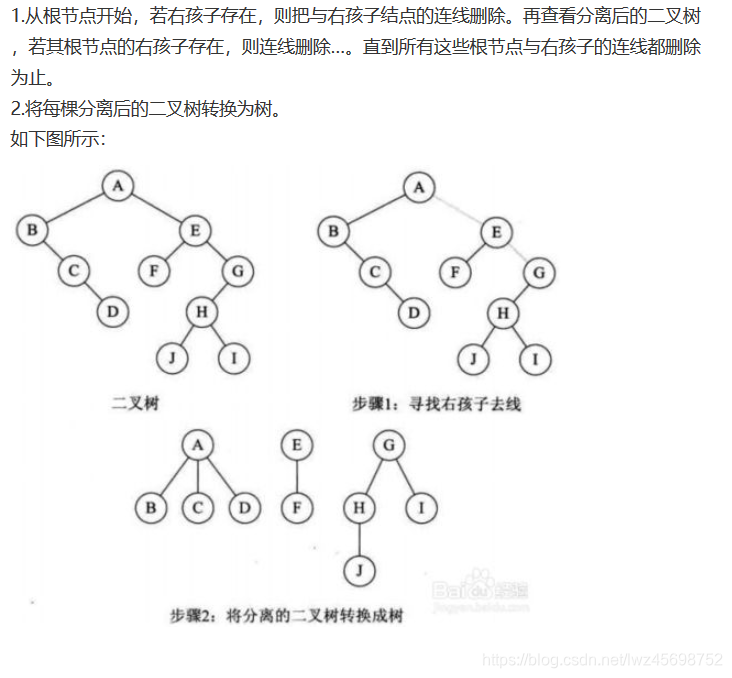
- 每棵二叉树再转化为树
树与森林的遍历
- 先根遍历
- 后根遍历
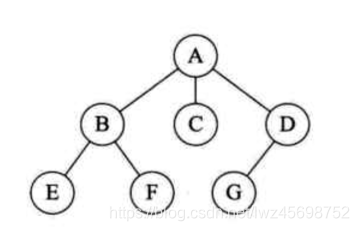


- 发现森林的前序遍历同二叉树的前序遍历,后序遍历同二叉树的中序遍历——》树的先根遍历和后跟遍历完全可以借用二叉树的前序和中序遍历算法实现
赫夫曼树及其应用
- 目标:压缩文件而不出错
- 基本过程:把要压缩的文本进行重新编码,减少不必要的空间
- 解决数据传输的最优化问题(传输单词,但每个单词出现频率不一样,不能一刀切地编码)
赫夫曼编码
- 最基本的压缩编码方法
- 基本思想:if-else判断成绩等第——》若高分段人数多,自然要先if(grade>60),而不是先判断if(grade<60),以此类推
- 这种判断结构类似于二叉树——》怎么设计
- 将二叉树简化为叶子节点带权的二叉树(每个叶子的分支线上的数字就是各分段所占的比例数)
基本概念
- 路径:一个节点到另一个节点之间的分支(连线)构成路径,分支数目为路径长度
- 树的路径:根节点到每一节点的路径长度之和(计算所有节点)
- 节点的带权的路径长度:从该节点到根节点之间的路径长度*节点上的权
- 树的带权路径长度(WPL):所有叶子节点的带权的路径长度之和(仅仅计算叶子节点)
- WPL最小的二叉树——》赫夫曼树(最优二叉树)
- WPL可理解为求一个成绩的等第的比较次数(叶子节点的权值为5%,即该分数段的所占比例)
构造哈夫曼树
- 带权叶子节点排序,从小到大
- 取最小的两个权值叶子节点,左节点smaller,右节点bigger,产生新节点
- 新节点加入排序队伍,继续上述过程
- 直到到达老队伍的最大权值叶子节点

哈夫曼编码
- 按照哈夫曼树来编码
- 构造哈尔曼树(频率为权值)——》左分支为0,右分支为1
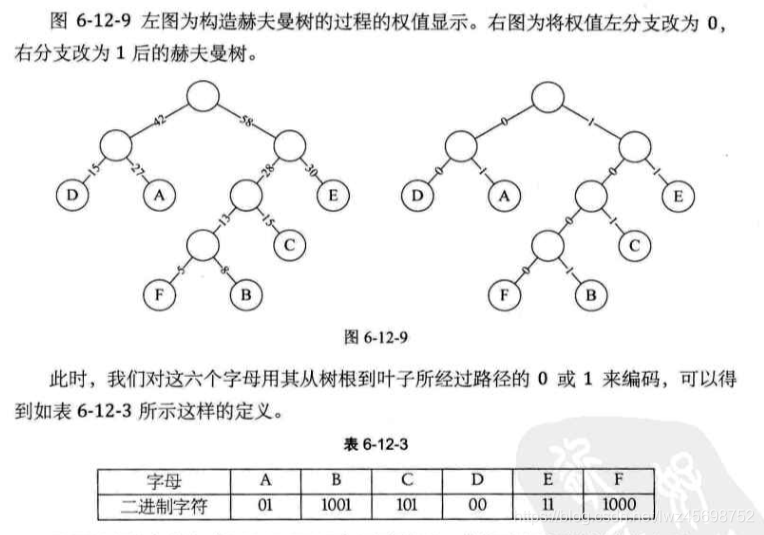
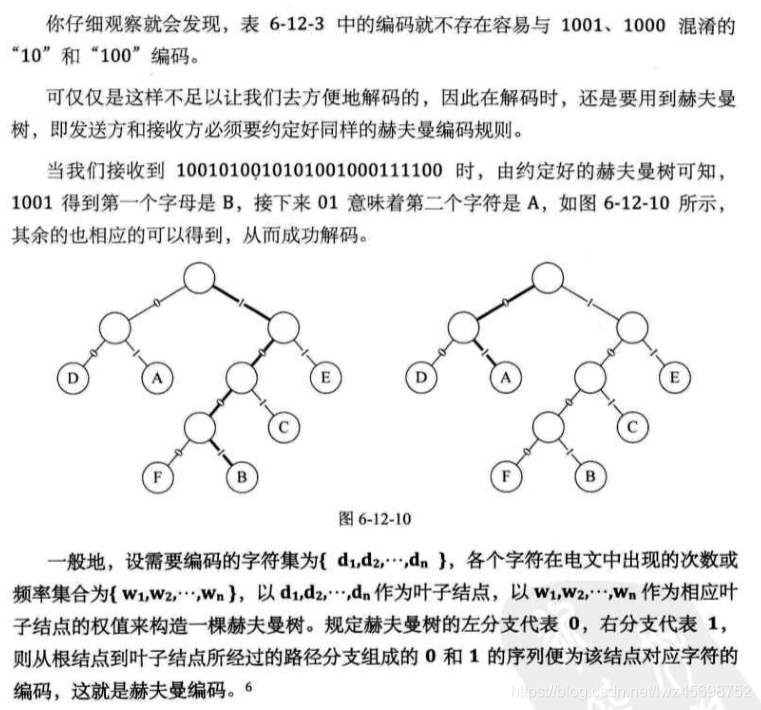
哈夫曼解码
- 每个字母对应长度不一的编码容易混淆——》设计长短不一的编码,要保证任一字符的编码都不是另一个字符的编码的前缀(称为前缀编码)
- 发送方与接收方要约定好同样的编码规则
总结



















 1770
1770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









